Publication bias and the canonization of false facts
In the process of scientific inquiry, certain claims accumulate enough support to be established as facts. Unfortunately, not every claim accorded the status of fact turns out to be true. In this paper, we model the dynamic process by which claims ar…
Authors: Silas B. Nissen, Tali Magidson, Kevin Gross
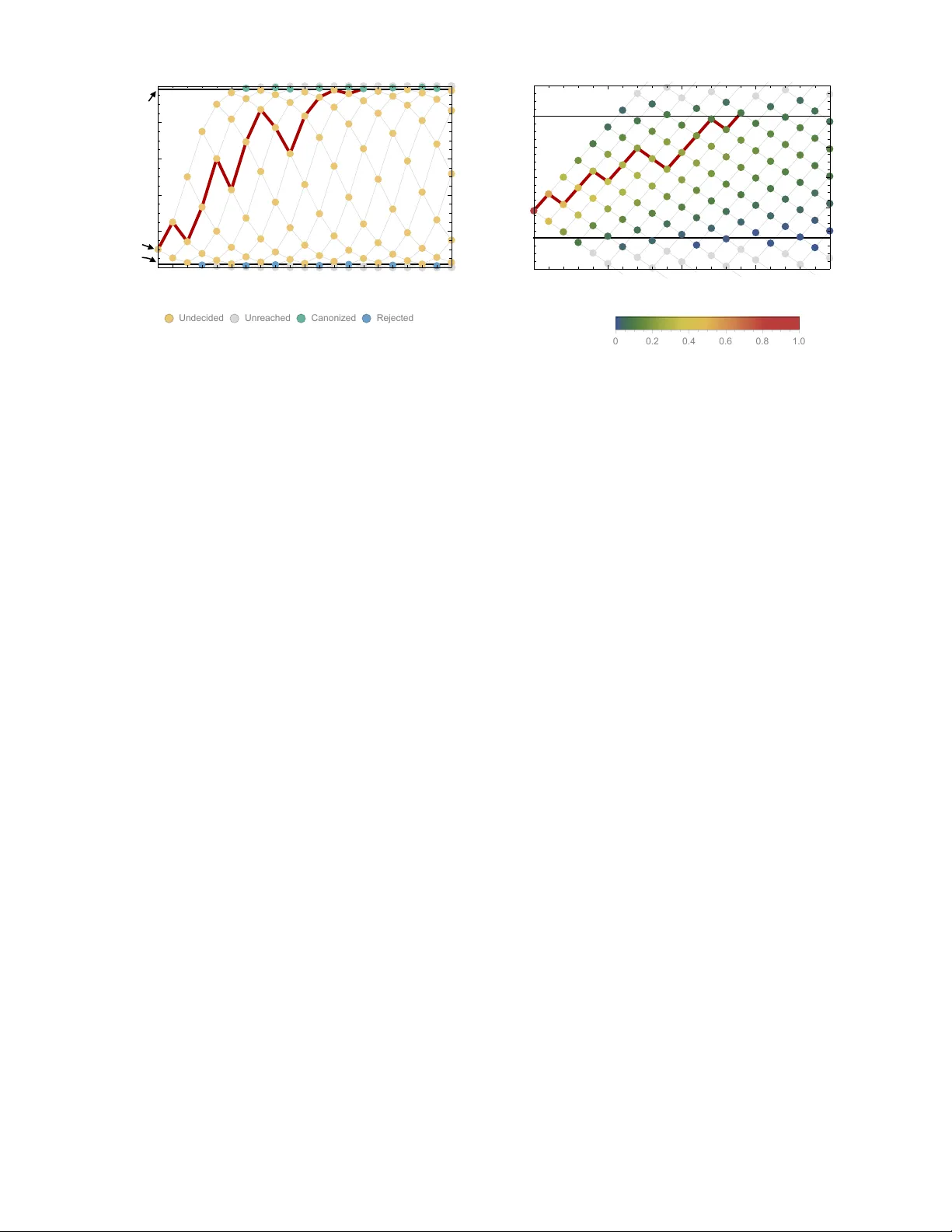
Publication bias and the canonization of false facts ∗ Silas B. Nissen † Niels Bohr Institute University of Cop enhagen Cop enhagen, Denmark T ali Magidson ‡ Dep artment of Computer Scienc e University of Washington Se attle, W A USA Kevin Gross § Dep artment of Statistics North Car olina State University R aleigh, NC USA Carl T. Bergstrom ¶ Dep artment of Biolo gy University of Washington Se attle, W A USA (Dated: Septem b er 5, 2018) Science is facing a “replication crisis” in whic h many experimental findings are irreplicable and lik ely false. Do es this imply that many scientific facts are false as well? T o find out, we explore the pro cess by which a claim becomes fact. W e mo del the comm unity’s confidence in a claim as a Marko v pro cess with successive published results shifting the degree of b elief. Publication bias in fa vor of p ositive findings influences the distribution of published results. W e find that unless a sufficien t fraction of negativ e results are published, false claims frequen tly can b ecome canonized as fact. Data-dredging, p-hacking, and similar b ehaviors exacerbate the problem. When results b ecome easier to publish as a claim approac hes acceptance as a fact, ho wev er, true and false claims can b e more readily distinguished. T o the degree that the model reflects the real world, there ma y b e serious concerns ab out the v alidity of purp orted facts in some disciplines. I. INTR ODUCTION Science is a pro cess of collective knowledge creation in whic h researchers use exp erimental, theoretical, and ob- serv ational approac hes to dev elop a naturalistic under- standing of the w orld. In the developmen t of a scientific field, certain claims stand out as b oth significan t and stable in the face of further exp erimen tation [1]. Once a claim reaches this stage of widespread acceptance as true, it has transitioned from claim to fact . This tran- sition, which we call c anonization , is often indicated by some or all of the follo wing: a canonized fact can b e tak en for granted rather than treated as an open hypothesis in the subsequen t primary literature; tests that do no more than to confirm previously canonized facts are seldom considered publication-worth y; and canonized facts be- gin to app ear in review papers and textb o oks without the company of alternative h yp otheses. Of course the ∗ KG and CTB contributed equally and share the senior author role. † silas@nbi.ku.dk ‡ talim@uw.edu § krgross@ncsu.edu ¶ cbergst@u.washington.edu v eracity of so-called facts ma y b e called back in to ques- tion [2, 3], but for time being the issue is considered to b e settled. Note that w e consider facts to b e epistemologi- cal rather than ontological: a claim is a fact b ecause it is accepted by the relev ant communit y , not b ecause it ac- curately reflects or represents underlying ph ysical reality [1, 3]. But what is the status of these facts in ligh t of the repli- cation crisis purp ortedly plaguing science to da y? Large scale analyses hav e revealed that many published pap ers in fields ranging from cancer biology to psyc hology to eco- nomics cannot b e replicated in subsequent exp erimen ts [4 – 10]. One p ossible explanation is that man y published exp erimen ts are not replicable b ecause man y of their con- clusions are ontologically false [11, 12]. If man y exp erimen tal findings are ontologically false, do es it follow that man y scientific facts are on tologically un true? Not necessarily . Claims of the sort that b ecome facts are rarely if ever tested directly in their en tirety . In- stead, such claims t ypically comprise multiple subsidiary h yp otheses whic h m ust be individually v erified. Th us m ultiple exp erimen ts are usually required to establish a claim. Some of these may include direct replications, but more typically an ensem ble of distinct exp erimen ts will pro duce multiple lines of evidence b efore a claim is ac- cepted b y the comm unity . 2 F or example, as molecular biologists w orked to unrav el the details of the euk aryotic RNA interference (RNAi) path wa y in the early 2000s, they w anted to understand ho w the RNAi pathw ay was initiated. Based on work with Dr osophila cell lines and embry o extracts, one group of researc hers made the claim that the RNAi pathw ay is initiated by the Dicer enzyme which slices double- stranded RNA into short fragme n ts of 20-22 amino acids in length [13]. Like man y scientific facts, this claim was to o broad to b e v alidated directly in a single exp erimen t. Rather, it comprised a num b er of subsidiary assertions: an enzyme called Dicer exists in euk ary otic cells; it is es- sen tial to initiate the RNAi path wa y; it binds dsRNA and slices it into pieces; it is distinct from the enzyme or en- zyme complex that destroys targeted messenger RNA; it is ubiquitous across euk aryotes that exhibit RNAi path- w ay . Researchers from n umerous labs tested these sub- sidiary hypotheses or asp ects thereof to derive numerous lines of conv ergent evidence in supp ort of the original claim. While the initial breakthrough came from w ork in Dr osophila melano gaster cell lines [13], subsequent re- searc h inv olved in establishing this fact drew up on in vitr o and in vivo studies, genomic analyses, and ev en mathematical mo deling efforts, and spanned sp ecies in- cluding the fission yeast Schizosac char omyc es p omb e , the protozoan Giar dia intestinalis , the nemoto de Caenorhab- ditis ele gans , the flow ering plant A r abidopsis thaliana , mice, and humans [14]. Ultimately , sufficient support- ing evidence accum ulated to establish as fact the original claim about Dicer’s function. Requiring m ultiple studies to establish a fact is no panacea, how ever. The same pro cesses that allow pub- lication of a single incorrect result can also lead to the accum ulation of sufficien tly man y incorrect findings to establish a false claim as fact [15]. This risk is exacerbated b y public ation bias [16 – 25]. Publication bias arises when the probabilit y that a scien- tific study is published is not indep endent of its results [16]. As a consequence, the findings from published tests of a claim will differ in a systematic wa y from the findings of all tests of the same claim [22, 26]. Publication bias is perv asive. Authors hav e systematic biases regarding whic h results they consider worth writ- ing up; this is kno wn as the “file draw er problem” or “out- come rep orting bias” [17, 24]. Journals similarly hav e bi- ases about whic h results are w orth publishing. These t wo sources of publication bias act equiv alently in the model dev elop ed here, and thus we will not attempt to sepa- rate them. Nor would separating them b e simple; even if authors’ b eha vior is the larger contributor to publication bias [23, 25], they may simply b e responding appropri- ately to incentiv es imp osed by editorial preferences for p ositiv e results. What kinds of results are most v alued? Findings of sta- tistically significan t differences b et ween groups or treat- men ts tend to b e view ed as more w orthy of submission and publication than those of non-significant differences. Correlations b et ween v ariables are often considered more in teresting than the absence of correlations. T ests that reject null hypotheses are commonly seen as more note- w orthy than tests that fail to do so. Results that are in teresting in an y of these w ays can b e described as “pos- itiv e”. A substantial ma jorit y of the scientific results pub- lished app ear to b e p ositive ones [27]. It is relativ ely straigh tforward to measure the fraction of published re- sults that are negative. One extensiv e study found that in 2007, more than 80% of pap ers rep orted p ositiv e find- ings, and this num b er exceeded 90% in disciplines such as psychology and ecology [28]. Moreo ver, the fraction of publications reporting positive results has increased o ver the past few decades. While this high prev alence of p ositiv e results could in principle result in part from ex- p erimen tal designs with increasing statistical p ow er and a gro wing preference for testing claims that are believed lik ely to b e true, publication bias doubtless contributes as w ell [28]. Ho w sizable is this publication bias? T o answer that, w e need to estimate the fraction of negative results that are published, and doing so can be difficult b ecause we rarely ha ve access to the set of findings that go unpub- lished. The best a v ailable evidence of this sort comes from registered clinical trials. F or example, in 2008 meta- analysis of 74 FDA-registered studies of antidepressan ts [26]. In that analysis, 37 of 38 p ositiv e studies were pub- lished as p ositiv e results, but only 3 of 24 negative studies w ere published as negative results. An additional 5 neg- ativ e studies were re-framed as p ositiv e for the purposes of publication. Th us, negativ e studies w ere published at scarcely more than 10% the rate of p ositiv e studies. W e would like to understand how the p ossibilit y of mis- leading exp erimen tal results and the prev alence of pub- lication bias shape the creation of scien tific facts. Math- ematical models of the scien tific pro cess can help us un- derstand the dynamics by whic h scientific kno wledge is pro duced and, consequen tly , the likelihoo d that elemen ts of this knowledge are actually correct. In this pap er, w e lo ok at the wa y in which rep eated efforts to test a scien- tific claim establish this claim as fact or cause it to b e rejected as false. W e develop a mathematical model in which succes- siv e publications influence the comm unity’s p erceptions around the likelihoo d of a given scientific claim. Positiv e results imp el the claim tow ard fact, whereas negative re- sults lead in the opposite direction. Describing this pro- cess, Bruno Latour [3] compared the fate of a scientific claim to that of a rugby ball, pushed alternativ ely to- w ard fact or falseho o d b y the efforts of comp eting teams, its fate determined b y the balance of their collectiv e ac- tions. Put in these terms, our aim in the present pap er is to develop a formal model of how the ball is driven up and down the epistemological pitch until one of the goal lines is reached. In the subsequent sections, we outline the mo del, explain how it can b e analyzed, presen t the results that we obtain, and consider its implications for the functioning of scien tific activit y . 3 I I. MODEL In this section, we will develop a simplified mo del of scientific activity , designed to capture the imp ortan t qualitativ e features of fact-creation as a dynamic pro cess. A. Mo del description W e explore a simple model in whic h researc hers se- quen tially test a single claim until the scientific commu- nit y b ecomes sufficiently certain of its truth or falseho od that no further exp erimen tation is needed. Our mo del is conceptually related to those developed in refs. [15, 29], though it is considerably simpler than either since we only consider a single claim at a time. Figure 1 provides a schematic illustration of the ex- p erimen tation and publication pro cess. W e begin with a claim whic h is ontologically either true or false. Re- searc hers sequentially conduct exp erimen ts to test the claim; these experiments are t ypically not direct replica- tions of one another, but rather distinct approaches that lend broader supp ort to the claim. Eac h exp erimen t re- turns either a positive outcome supp orting the claim, or a negative outcome con trav ening it. F or mathematical simplicit y , we assume all tests to hav e the same error rates, in the sense that if the claim under scrutiny is false, then inv estigators obtain false p ositives with prob- abilit y α . Conv ersely , when the claim is true, inv estiga- tors obtain false negatives with probabilit y β . W e take these error rates to b e the ones that are conv entionally asso ciated with statistical h yp othesis testing, so that α is equiv alent to the significance lev el (tec hnically , the size ) of a statistical test and 1 − β is the test’s p ow er. W e as- sume that, as in any reasonable test, a true claim is more lik ely to generate a p ositiv e result than a negative one: 1 − β > α . A broader interpretation of α and β b ey ond statistical error do es not c hange the interpretation of our results. After completing a study , the in vestigators ma y at- tempt to publish their experimental results. How ever, publication bias o ccurs in that the result of the exp er- imen t influences the c hance that a study is written up as a paper and accepted for publication. Positiv e re- sults are even tually published somewhere with proba- bilit y ρ 1 while negativ e results are even tually published somewhere with probability ρ 0 . Giv en the reluctance of authors to submit negative results and of journals to pub- lish them, we exp ect that in general ρ 1 > ρ 0 . Finally , readers attempt to judge whether a claim is true b y consulting the published literature only . F or mo deling purp oses, we will consider a b est-case scenario, in which the false p ositive and false negative rates α and β are established by disciplinary custom or accepted b enc hmarks, and readers p erform Bay esian up dating of their b eliefs based up on these known v alues. In practice, these v alues may not b e as well standardized or widely rep orted as would b e desirable. Moreov er, readers are un- T rue False Positive Negative Claim Experiment Publication Support Fail to support Unpublished 1 - β β 1 - α α ρ 1 1 - ρ 1 ρ 0 1 - ρ 0 Repeat or FIG. 1. Conducting and rep orting the test of a claim . In our mo del, a scientific claim is either true or false. Re- searc hers conduct an exp erimen t whic h either supp orts or fails to the supp ort the claim. T rue claims are correctly sup- p orted with probabilit y 1 − β while false claims are incorrectly supp orted with probability α . Next, the researchers may at- tempt to publish their results. Positiv e results that supp ort the claim are published with probabilit y ρ 1 whereas nega- tiv e results that fail to supp ort the claim are published with probabilit y ρ 0 . This pro cess then rep eats, with additional ex- p erimen ts conducted until the claim is canonized as fact or rejected as false. lik ely to b e this sophisticated in drawing their inferences. Instead readers are likely to form sub jective b eliefs in an informal fashion based on a general assessment of the ac- cum ulated p ositive and negative results and the strength of each. But the Bay esian up dating case provides a well- defined mo del under which to explore the distortion of b elief by publication bias. The problem is that the results describ ed in the pub- lished literature are now biased b y the selection of which articles are drafted and accepted for publication. W e as- sume that readers are unaw are of the degree of this bias, and that they fail to correct for publication bias in draw- ing inferences from the published data. It may seem p es- simistic that researchers would fail to make this correc- tion, but muc h of the curren t concern o ver the replication crisis in science is predicated on exactly this. Moreo ver, it is usually impossible for a researcher to accurately es- timate the degree of publication bias in a given domain. B. Mo del dynamics Consider a claim that the communit y initially consid- ers to ha ve probability q 0 of b eing true. Researc hers it- erativ ely test h yp otheses that bear up on the claim until it accum ulates either sufficient supp ort to b e canonized as fact, or sufficien t counter-evidence to be discarded as false. If the claim is true, the probabilit y that a single test leads to a p ositiv e publication is (1 − β ) ρ 1 , and the cor- resp onding probability of a negative publication is β ρ 0 . The remaining probabilit y corresp onds to results of the 4 test not being published. If the claim is false, these prob- abilities are α ρ 1 and (1 − α ) ρ 0 for positive and negative published outcomes, resp ectiv ely . Giv en that a claim is true, the probabilit y that a published test of that claim rep orts a positive outcome is therefore ω T = (1 − β ) ρ 1 (1 − β ) ρ 1 + β ρ 0 . (1) F or a false claim, the probabilit y that a published test is p ositiv e is ω F = αρ 1 αρ 1 + (1 − α ) ρ 0 . (2) Because only the ratio of ρ 1 to ρ 0 matters for the pur- p oses of our mo del, we set ρ 1 to 1 for the remainder of the pap er. W e initially assume that ρ 0 is constan t, but will relax this latter assumption later. T o formalize ideas, consider a sequence of published outcomes X , and let Y k b e the num b er of p ositiv e pub- lished outcomes in the first k terms of X . When the prob- abilities of publishing a negative result ρ 0 is constan t, the outcomes of published experiments are exc hangeable ran- dom v ariables. Th us after k published tests, the distri- bution of Y k for a true claim is the binomial distribution Bin( k , ω T ) and for a false claim is Bin( k, ω F ). More- o ver, the sequence { Y k } ∞ k =1 is a Marko v chain. When the exten t of publication bias is known, we can compute the conditional probabilit y that a claim is true, given Y k = y , as ω y T (1 − ω T ) k − y q 0 ω y T (1 − ω T ) k − y q 0 + ω y F (1 − ω F ) k − y (1 − q 0 ) . (3) W e now consider the consequences of dra wing infer- ences based on the published data alone, without cor- recting for publication bias. F or mo del readers who do not condition on publication bias, let q k ( y ) b e the p er- ceiv ed, conditional probability that a claim is true giv en Y k = y . W e say “p erceived” b ecause these readers use Ba yes’ La w to up date q k , but do so under the incorrect assumption that there is no publication bias, i.e., that ρ 0 = ρ 1 = 1. T o ease the narrative, we refer to the per- ceiv ed conditional probabilit y that a claim is true as the “b elief ” that the claim is true. Expressing this formally , q k ( y ) = (1 − β ) y β k − y q 0 (1 − β ) y β k − y q 0 + α y (1 − α ) k − y (1 − q 0 ) . (4) Note that without publication bias, w e hav e ω T = (1 − β ) and ω F = α , and thus eq. 3 coincides with eq. 4. F rom the p ersp ectiv e of an observ er who is una ware of an y publication bias, the pair ( Y k , k ) is a sufficien t statistic for the random v ariable A ∈ { T rue , F alse } rep- resen ting the truth v alue of the claim in question. This follo ws from the definition of statistical sufficiency and the fact that prob h A = T rue | Y k , k , { Y i } k i =1 i = q k ( y ) = prob [ A = T rue | Y k , k ] . By analogous logic, the pair ( Y k , k ) is also a sufficient statistic for an observ er aw are of the degree of publication bias pro vided that the publication probabilities ρ 0 and ρ 1 are constan t. W e en vision science as pro ceeding iteratively until the b elief that a claim is true is sufficien tly close to 1 that the claim is canonized as fact, or un til belief is sufficiently close to 0 that the claim is discarded as false. W e let τ 0 and τ 1 b e the b elief thresholds at whic h a claim is rejected or canonized as fact, resp ectively (0 < τ 0 < τ 1 < 1), and refer to these as eviden tiary standards. In our analysis, we make the simplifying assumption that the eviden tiary standards are symmetric, i.e., τ 0 = 1 − τ 1 . W e describ e the consequences of relaxing this assumption in the Discussion. Th us, mathematically , we mo del b elief in the truth of a claim as a discrete-time Mark ov chain { q k } ∞ k =0 with absorbing b oundaries at the evidentiary standards for canonization or rejection (Fig. 2A). When the Marko v c hain represents b elief, its p ossible v alues lie in the inter- v al from 0 to 1. F or mathematical con venience, how ever, it is often helpful to con vert belief to the log o dds scale, that is, ln( q k / (1 − q k )). Some algebra shows that the log o dds of belief q k ( y ) can b e written as ln q k ( y ) 1 − q k ( y ) = y ln 1 − β α + ( k − y ) ln β 1 − α + ln q 0 1 − q 0 . (5) The log o dds scale is conv enien t b ecause, as eq. 5 shows, eac h published positive outcome increases the log odds of belief b y a constant increment d 1 = ln 1 − β α > 0 (Fig. 2B). Eac h published negativ e outcome decreases the log odds of b elief b y d 0 = ln β 1 − α < 0 . Belo w, w e will see that muc h of the b eha vior of our model can be understo od in terms of the exp ected c hange in the log o dds of b elief for each published outcome. F or a true claim, the exp ected change in the log o dds of belief is d 1 ω T + d 0 (1 − ω T ) (6) whereas for a false claim, the exp ected change in the log o dds of belief is d 1 ω F + d 0 (1 − ω F ) . (7) C. Computing canonization and rejection probabilities In general, w e cannot obtain a closed-form expression for the probability that a claim is canonized as fact or 5 0 5 10 15 20 0.0 0.2 0.4 0.6 0.8 1.0 E xperiment s Posterior Probability Undecided Unreached Canonized Reject ed A τ 1 0 τ q 0 Published experiments 0 5 10 15 20 - 6 - 4 - 2 0 2 4 6 E xperiment s Log Odds Visit probability 0 0. 2 0. 4 0. 6 0. 8 1. 0 B Published experiments FIG. 2. A time-directed graph represen ts the ev olution of b elief o ver time . In panel A, the horizontal axis indicates the num b er of exp eriments published and the vertical axis reflects the observ er’s belief, quan tified as the probability that the claim is true. The pro cess begins at the single p oin t at far left with an initial b elief q 0 . Eac h subsequent experiment either supp orts the claim, moving to the next node up and right, or con tradicts the claim, mo ving to the next no de do wn and righ t. At y ellow nodes, the status of the claim is as yet undecided. A t green no des, it is canonized as fact, and at blue no des, it is rejected as false. The black horizontal lines show the evidentiary standards ( τ 0 and τ 1 ). The red path shows one p ossible tra jectory , in whic h a p ositiv e exp erimen t is follow ed by a negative, then tw o p ositives, then a negative, etc., ultimately b ecoming canonized as fact when it reaches the upp er b oundary . Panel B shows the same netw ork, but with the vertical axis representing log o dds and using color to indicate the probabilit y that the pro cess visits that node. In log-o dds space, eac h published positive result shifts b elief by the constant distance d 1 > 0 and each negative result by a different distance d 0 < 0. Shown here (in b oth panel A and B) is a false claim with false positive rate α = 0 . 2, false negative rate β = 0 . 4, publication probabilities p 0 = 0 . 1 and p 1 = 1, and initial b elief q 0 = 0 . 1. In this case, the claim is likely to b e canonized as fact, despite b eing false. for the probabilit y that it is rejected as false. W e can, ho wev er, derive recursive expressions for the probabili- ties that after k published experiments a claim has b een canonized as fact, has b een discarded as false, or remains undecided. F rom these, it is straigh tforward to compute the canonization and rejection probabilities numerically to an y desired lev el of precision. F or each num b er of published exp eriments k , the state space for Y k is simply Y k ∈ { 0 , 1 , . . . , k } . P artition this state space as follo ws: C k = { y : q k ( y ) > τ 1 } I k = { y : q k ( y ) ∈ [ τ 0 , τ 1 ] } R k = { y : q k ( y ) < τ 0 } . That is, C k is the set of outcomes corresp onding to a b elief greater than the eviden tiary standard for canonization, R k is the set of outcomes corresp onding to a b elief less than the evidentiary standard for rejection, and I k is the set of outcomes corresp onding to belief in b etw een these t wo standards (the “interior”). Let T b e the n umber of publications until a claim is either canonized or rejected. F ormally , T = min { k : Y k ∈ C k ∪ R k } . F or a true claim, w e calculate the probabilit y of canon- ization as follo ws. (A parallel set of equations gives the probabilit y of canonization for a false claim.) F or eac h y ∈ I k , define p k ( y ) = Prob { Y k = y , T > k } . That is, p k ( y ) is the probabilit y that there are exactly y p ositive outcomes in the first k publications, and the claim has y et to b e canonized or rejected by publication k . Sup- p ose these probabilities are known for each y ∈ I k . Then for each y ∈ I k +1 , these probabilities can be found re- cursiv ely b y p k +1 ( y ) = ω T p k ( y − 1) + (1 − ω T ) p k ( y ) . F or computational purposes, in the recursion ab ov e w e define p k ( y ) = 0 whenever y / ∈ I k . The probability that the claim has yet to b e canonized or rejected by publica- tion k is simply Prob { T > k } = X y ∈I k p k ( y ) . Let φ k b e the probabilit y that a claim is first canonized at publication k . F ormally , φ k = X y : y − 1 ∈I k − 1 and y ∈C k ω T p k − 1 ( y − 1) . Let k ? b e the smallest v alue of k for whic h Prob { T > k } ≤ . T o calculate the probability of canon- ization, we calculate p k ( y ) for all k = 1 , . . . , k ? . The probabilit y of canonization is then P k ? k =1 φ k . F or the analyses in this paper, w e ha ve set = 10 − 4 . 6 τ 0 = 0.1 ρ � A τ 0 = 0.001 B FIG. 3. ROC curv es rev eal that true claims are almost alwa ys canonized as fact . In the receiv er op erating charac- teristic (ROC) curves shown here, the vertical axis represen ts the probabilit y that a true claim is correctly canonized as fact, and the horizontal axis represents the probability that a false one is incorrectly canonized as fact. P anel A: lax eviden tiary standards τ 0 = 0 . 1 and τ 1 = 0 . 9. Panel B: strict evidentiary standards τ 0 = 0 . 001 and τ 1 = 0 . 999. Error rates and initial b elief are α = 0 . 05, β = 0 . 2, and q 0 = 0 . 5. Each p oint along the ROC curve corresp onds to a differen t v alue of negative publication rate, ρ 0 , as indicated by color. Grey regions of the curve correspond to the unlikely situations in which ρ 0 > ρ 1 = 1, i.e., negative results are more likely to be published than p ositive ones. The figures rev eal t wo imp ortan t p oints. First, when negativ e results are published at any rate ρ 0 ≤ 1, the v ast ma jority of true claims are canonized as fact. Second, when negative results are published at a low rate ( ρ 0 less than 0.3 or 0.2 dep ending on eviden tiary standards), many false claims will also b e canonized as true. I II. RESUL TS W e fo cus throughout the pap er on the dynamic pro- cesses b y which false claims are canonized as facts, and explore how the probabilit y of this happening depends on prop erties of the system such as the publication rate of negativ e results, the initial b eliefs of researchers, the rates of exp erimental error, and the degree of evidence required to canonize a claim. In principle, the conv erse could b e a problem as w ell: true claims could be discarded as false. Ho wev er, this is rare in our mo del. Publication bias fa- v ors the publication of p ositive results and therefore will not tend to cause true claims to b e discarded as false, irresp ectiv e of other parameters. W e first establish this, and then proceed to a detailed examination of how scien- tific experimentation and publication influences the rate at whic h false claims are canonized as fact. A. T rue claims tend to b e canonized as facts In our mo del, true claims are almost alwa ys canonized as facts. Figure 3 illustrates this result in the form of a re- ceiv er op erating characteristic (ROC) curv e. Holding the other parameters constan t, the curve v aries the negativ e publication rate ρ 0 , and uses the v ertical and horizon- tal axes to indicate the probabilities that true and false claims respectively are canonized as fact. One might fear that as the probabilit y ρ 0 of publish- ing negative results clim bs tow ard unity , the risk of re- jecting a true claim would increase dramatically as well. This is not the case. Even as the probabilit y of publish- ing negative results approac hes 1, the risk of rejecting a true claim is low when evidentiary standards are lax (Fig. 3A), and negligible when evidentiary standards are strict (Fig. 3B). This result turns out to b e general across a broad range of parameters. Assuming the mild requirements that (i) tests of a true claim are more likely to result in p ositiv e publications than negative publications (i.e., ω T > 1 / 2, or equiv alently (1 − β ) > β ρ 0 ), and (ii) p ositiv e published outcomes increase b elief that the claim is true ( d 1 > 0, or equiv alently (1 − β ) > α ), true claims are highly likely to b e canonized as facts. The exceptions occur only when minimal evidence is needed to discard a claim, i.e., when initial b elief is small ( q 0 ≈ τ 0 ). In such cases a bit of bad luc k—the first one or tw o published exp eriments rep ort false negativ es, for example—can cause a true claim to b e rejected. But otherwise, truth is sufficien t for canon- ization. Unfortunately , truth is not required for canonization. The risk of canonizing a false claim—shown on the hor- izon tal axis v alue in figure 3—is highly sensitiv e to the rate at which negative results are published. When neg- ativ e results are published with high probability , false claims are seldom canonized. But when negative results are published with low er probability , many false claims are canonized. Th us we see that the predominant risk associated with publication bias is the canonization of false claims. In 7 0 0.2 0.4 0.6 0.8 1 A α =.25 α =.2 α =.15 α =.1 α =.05 B α =.25 α =.2 α =.15 α =.1 α =.05 0 0.2 0.4 0.6 0.8 0 0.2 0.4 0.6 0.8 C α =.25 α =.2 α =.15 α =.1 α =.05 0 0.2 0.4 0.6 0.8 1 D Negative publication rate Probability of canonizing false claim as fact α =.25 α =.2 α =.15 α =.1 α =.05 = .2 = .1 = .4 0 = .9 = .001 = .999 τ τ 0 1 1 τ τ β β FIG. 4. Publishing negativ e outcomes is essential for rejecting false claims . Probability that a false claim is incorrectly canonized, as a function of the negative publica- tion rate. Throughout, initial b elief is q 0 = 0 . 5, and indi- vidual data series sho w false positive rates α = 0 . 05 (yel- lo w), 0 . 10 , . . . , 0 . 25 (red). T op row: w eak evidentiary stan- dards τ 0 = 0 . 1 and τ 1 = 0 . 9. Panel A: false negativ e rate β = 0 . 2. Panel B: β = 0 . 4. Panels C–D: similar to panels A–B, with more demanding evidentiary standards τ 0 = 0 . 001 and τ 1 = 0 . 999. the remainder of this analysis, we fo cus on this risk of incorrectly establishing a false claim as a fact. B. Publication of negativ e results is essential As we discussed in the introduction, authors and jour- nals alik e tend to be reluctan t to publish negativ e results, and as w e found in the previous subsection, when most negativ e results go unpublished, science p erforms po orly . Here, w e explore this relationship in further detail. Figure 4 sho ws how the probability of erroneously can- onizing a false claim as fact dep ends on the probability ρ 0 that a negative result is published. F alse claims are lik ely to be canonized b elo w a threshold rate of nega- tiv e publication, and unlikely to be canonized ab o ve this threshold. F or example, when the false positive rate α is 0.05, the false negativ e rate β is 0.4, and the evidentiary requiremen ts are strong (y ellow p oin ts in Panel 4D), a false claim is likely to b e canonized as fact unless nega- tiv e results are at least 20% as likely as p ositiv e results to be published. Figure 4 also reveals that the probabilit y of canonizing false claims as facts depends strongly on b oth the false p ositiv e rate and the false negativ e rate of the exp eri- men tal tests. As these error rates increase, an increas- ingly large fraction of negative results must b e published 0 0.2 0.4 0.6 0.8 1 A ρ 0 =.025 .05 .1 .2 .4 B ρ 0 =.1 .3 .4 .5 1 0 0.2 0.4 0.6 0.8 0 0.2 0.4 0.6 0.8 C 0 0.2 0.4 0.6 0.8 1 D Prior belief of being true Probability of canonizing false claim as fact α = .1 α = .2 = .4 = .2 = .05 = .9 = .001 = .999 τ τ τ τ 0 0 1 1 β β FIG. 5. F alse canonization rates are relatively insen- sitiv e to initial belief, unless exp erimen tal tests are inaccurate and evidentiary standards are w eak . Prob- abilit y that a false claim is mistakenly canonized as a true fact vs. prior b elief for v arious negative publication rates. T op ro w: w eak evidentiary standards τ 0 = 0 . 1 and τ 1 = 0 . 9. Panel A: false positive rate α = 0 . 05, false negativ e rate β = 0 . 2, and publication rate of negativ e results ρ 0 = 0 . 025 (light green), 0 . 05 , 0 . 1 , 0 . 2 , 0 . 4 (dark green). Panel B: α = 0 . 2, β = 0 . 4, and ρ 0 = 0 . 1 (ligh t green), 0 . 3 , 0 . 4 , 0 . 5 , 1 (dark green). Panels C– D: similar to panels A–B, with more demanding eviden tiary standards τ 0 = 0 . 001 and τ 1 = 0 . 999. to preserv e the ability to discriminate betw een true and false claims. C. Initial b eliefs usually do not matter m uch If the scientific pro cess is working prop erly , it should not automatically confirm what we already b eliev e, but rather it should lead us to change our b eliefs based on evidence. Our mo del indicates that in general, this is the case. Figure 5 shows how the probabilit y that a false claim is canonized as true dep ends on the initial belief q 0 that the claim is true. Under most circumstances, the probability of canonization is relatively insensitive to initial b elief. F alse canonization rates dep end strongly on initial b elief only when eviden tiary standards are weak and exp eri- men ts are highly prone to error (Fig. 5B). In this case, b elief is a random walk without a systematic tendency to increase or decrease with eac h published outcome, and th us the o dds of canonization or rejection dep end most strongly on the initial b elief. The step-function-lik e appearance of some of the re- sults in Fig. 5, particularly Fig. 5A, is a real prop erty of the curves in question and not a numerical artifact. 8 0 0.2 0.4 0.6 0.8 0 0.2 0.4 0.6 0.8 1 A τ 0 =.1 τ 0 =.01 τ 0 =.001 0 0.2 0.4 0.6 0.8 1 B Negative publication rate Probability of canonizing false claim as fact τ 0 =.1 τ 0 =.01 τ 0 =.001 = .25 = .05 α α FIG. 6. Strengthening evidentiary requiremen ts do es not necessarily decrease canonization of false facts. In panel 6A, the false p ositiv e rate is α = 0 . 05, the false negativ e rate is β = 0 . 2, the original b elief in the claim is q 0 = 0 . 5, and the evidentiary standards are symmetric τ 1 = 1 − τ 0 . In panel 6B, the false positive rate is increased to α = 0 . 25 while the other parameters remain unchanged. Particularly in this latter case, increasing eviden tiary standards do es not neces- sarily decrease the rate at which false claims are canonized as facts. The “steps” arise b ecause, when evidentiary standards are weak, canonization or rejection often happ ens after a small num b er of exp eriments. Because the n umber of exp erimen ts must b e integral, probabilities of false can- onization can change abruptly when a small change in initial b elief increases or decreases the num b er of exp eri- men ts in the most lik ely path to canonization or rejection. D. Stronger eviden tiary standards do not reduce the need to publish negative outcomes W e hav e seen in the previous sections that the scien- tific pro cess struggles to distinguish true from false claims when the rate of publishing negative results is low. W e migh t hope that we could remedy this problem simply b y demanding more evidence b efore accepting a claim as fact. Unfortunately , this is not only exp ensiv e in terms of time and effort—sometimes it will not ev en help. Figure 6 illustrates the problem. In this figure, we see the probability of canonizing a false claim as a function of negativ e publication rate for three different evidentiary standards: τ 0 = 0 . 1, τ 0 = 0 . 01, and τ 0 = 0 . 001. When the false p ositive rate α is relatively low (Fig. 6A), in- creasing the evidentiary requiremen ts reduces the chance of canonizing a false claim for negative publication rates ab o v e 0.1 or so, but below this threshold there is no ad- v antage to requiring stronger evidence. When the false p ositiv e rate is higher (Fig. 6B), the situation is even w orse: for negativ e publication rates below 0.3 or so, in- creasing eviden tiary requirements actually increases the c hance of canonizing a false fact. The limited b enefits of strengthening eviden tiary stan- dards can be understoo d through the mathematical the- ory of random w alks [30]. In short, the thresholds of − 1 0 1 2 A: F alse h ypothesis 0 0.2 0.4 0.6 0.8 1 α = 0.25 α = 0.2 α = 0.15 α = 0.1 α = 0.05 B: T rue h ypothesis 0 0.2 0.4 0.6 0.8 1 Negative pub lication rate, ρ 0 Expected change in log odds of belief A: False claim B: Tr u e claim = .25 = .20 = .15 = .10 = .05 α α α α α FIG. 7. Scientific activity will tend to increase b elief in false claims if to o few negativ e outcomes are pub- lished . Exp ected change in log o dds of b elief vs. negative publication rate for (A) false and (B) true claims. Lines show false positive rates α = 0 . 05 (yello w), 0 . 10 , . . . , 0 . 25 (red). Other parameter v alues are false negativ e rate β = 0 . 2 and p ositiv e publication rate ρ 1 = 1. b elief for canonizing or rejecting a claim are absorbing b oundaries such that once b elief attains either b oundary , the walk terminates and b eliefs will not c hange further. Increasing the eviden tiary standards for canonization or rejection is tantamoun t to increasing the distance b e- t ween these b oundaries and the initial b elief state. Basic results from the theory of random walks suggest that, as the distance b etw een the initial state and the b oundaries increases, the probability of encountering one b oundary b efore the other dep ends increasingly strongly on the av- erage change in the log o dds of b elief at each step (ex- p erimen t), and less on the random fluctuations in b elief that arise from the sto c hasticit y of the walk. Thus, for exacting evidentiary standards, the probability of even- tual canonization or rejection dep ends critically on the a verage c hange in the log o dds of b elief for eac h exp eri- men t. These are giv en by eq. 6 for a true claim and eq. 7 for a false one. Figure 7 shows how the exp ected change in log o dds of belief v aries in response to c hanges in the publication rate of negativ e outcomes, for both false and true claim. Critically , for false claims, if to o few negativ e outcomes are published, then on av erage each new publication will incr e ase the b elief that the claim is true, b ecause there is a high probabilit y this publication will rep ort a p os- itiv e result. Th us, paradoxically , scientific activity do es not help sort true claims from false ones in this case, but instead promotes the erroneous canonization of false claims. The only remedy for this state of affairs is to publish enough negative outcomes that, on av erage, each published result mov es b elief in the “correct” direction, that is, to wards canonization of true claims (a positive a verage change p er exp eriment in log o dds of b elief ) and rejection of false ones (a negative av erage change p er ex- p erimen t in log odds of b elief ). Tw o additional p oints are in order here. First, for true claims, under most circumstances the exp ected c hange in the log o dds of belief is positive (Fig. 7B). That is, 9 on av erage, scientific activity prop erly increases belief in true claims, and thus the risk of incorrectly rejecting a true claim is small (under reasonable evidentiary stan- dards). Second, the observ ation that more exacting evi- den tiary standards can o ccasionally increase the chance of incorrectly canonizing a false claim is not m uch of an argumen t in fa vor of w eaker eviden tiary standards. In short, w eaker standards cause canonization or rejection to dep end more strongly on the happ enstance of the first sev eral published exp erimen ts. When scientific activit y tends to increase b elief in a false claim, weak er eviden- tiary standards app ear b eneficial b ecause they increase the c hance that a few initial published negativ es will lead to rejection and bring a halt to further inv estigation. While this is a logical result of the mo del, it is somewhat tan tamount to stating that, if scien tific activity tends to increase b elief in false claims, then the b est option is to w eaken the dep endence on scientific evidence. More ro- bust practices for rejecting false claims seem desirable. E. P -hacking dramatically increases the probability of canonizing false claims Our mo del has b een based on the optimistic premise that the significance levels rep orted in each study accu- rately reflect the actual false p ositiv e rates. This means that there is only a 5% c hance that a false claim will yield a positive result at the α = 0 . 05 level. In practice, reported significance levels can be mislead- ing. Questionable research practices of all sorts can result in higher-than-reported false p ositiv e rates; these include p-hac king [31], outcome switching [32], unrep orted m ul- tiple comparisons [33], data dredging [34], HARKing— h yp othesizing after the results are known [35], data- dep enden t analysis [36], and opportunistic stopping or con tinuation [37]. Insufficient v alidation of new technolo- gies, or even softw are problems can also drive realized er- ror rates far abov e what is expected given stated levels of statistical confidence (see e.g. ref. [38]). Research groups ma y b e positively disposed tow ard their prior h yp otheses or reluctant to con tradict the work of closely allied labs. Finally , industry-sponsored clinical trials often allo w the sp onsors some degree of control o ver whether results are published [39], resulting in an additional source of publi- cation bias separate from the journal acceptance process. T o understand the consequences of these problems and practices, we can extend our mo del to distinguish the ac- tual false p ositiv e rate α act from nominal false p ositiv e rate α nom whic h is rep orted in the paper and used by readers to draw their inferences. W e assume the actual false p ositive rate is alwa ys at least as large as the nom- inal rate, that is, α act ≥ α nom . In this scenario, the probabilit y that a false claims leads to a p ositiv e pub- lished outcome dep ends on the actual false p ositive rate, i.e., ω F = α act ρ 1 α act ρ 1 + (1 − α act ) ρ 0 . 0 0.2 0.4 0.6 0.8 1 0 0.2 0.4 0.6 0.8 1 Negative publication rate Probability of canonizing false claim as fact α act =.25 α act =.2 α act =.15 α act =.1 α act =.05 FIG. 8. p -hac king dramatically increases the chances of canonizing false claims . Probabilit y that a false claim is canonized as fact vs. fraction of negativ e outcomes. Through- out, all positive outcomes are published ( p 1 = 1), and the nominal false p ositiv e rate is α nom = 0 . 05, the false nega- tiv e rate is β = 0 . 2, and evidentiary standards are strong ( τ 0 = 0 . 001 and τ 1 = 0 . 999). Curv es sho w actual false p os- itiv e rates α act = 0 . 05 (yello w), 0 . 10 , . . . , 0 . 25 (red). Com- pared with Fig. 4C, in which the nominal rates are equal to the actual rates, the probability of canonizing a false claim as fact is substant ially higher. Ho wev er, the c hange in b elief following a p ositiv e or nega- tiv e published outcome resp ectiv ely depends on the nom- inal false p ositiv e rate: d 1 = ln 1 − β α nom d 0 = ln β 1 − α nom An inflated false p ositiv e rate makes it muc h more lik ely that false claims will be canonized as true facts (Fig. 8). F or example, suppose the false negativ e rate is β = 0 . 2, the nominal false p ositiv e rate is α nom = 0 . 05, but the actual false positive rate is α act = 0 . 25. Ev en eliminating publication bias against negativ e outcomes (i.e., ρ 0 = 1) and using strong evidentiary standards do es not eliminate the possibility that false claims will b e canonized as facts under these circumstances (Fig. 8). Less dramatic inflation of the false p ositiv e rate leav es op en the possibility that true vs. false claims can b e dis- tinguished, but only if a higher p ercen tage of negativ e outcomes are published. 10 F. Increasing negativ e publication rates as a claim approac hes canonization greatly increases accuracy Th us far we hav e told a troubling story . Without high probabilities of publication for negativ e results, the sci- en tific pro cess may perform p o orly at distinguishing true claims from false ones. And there are plent y of reasons to susp ect that negativ e results may not alw ays b e likely to be published. Ho wev er, authors, reviewers, and editors are all drawn to unexp ected results that challenge or modify prev alent views—and for a claim widely b elieved to b e true, a neg- ativ e result from a well-designed study is surprising. As a consequence, the probabilit y of publishing a negativ e re- sult may be higher for claims that are already considered lik ely to b e true [40, 41] In a simulation of p oin t estimation b y successiv e exper- imen tation, de Winter and Happ ee considered an even more extreme situation in whic h it is only possible to publish results that contradict the prev ailing wisdom [42]. They argue that this has efficiency b enefits, but their re- sults ha ve b een challenged p ersuasively by v an Assen and colleagues [43]. In any even t, such a publication strategy w ould not work in the framew ork we consider here, b e- cause a claim could neither b e canonized nor rejected if eac h new published result w ere required to contradict the curren t beliefs of the communit y . Some meta-analyses hav e rev ealed patterns consisten t with this mo del [44]. F or example, when the fluctuat- ing asymmetry hypothesis was prop osed in ev olution- ary ecology , the initial publications exclusively rep orted strong asso ciations b etw een symmetry and attractiv eness or mating success. As time passed, how ever, an increas- ing fraction of the papers on this h yp othesis reported negativ e findings with no asso ciation b etw een these v ari- ables [45]. A likely interpretation is that initially jour- nals were reluctan t to publish results inconsisten t with the h yp othesis, but as it b ecame b etter established, neg- ativ e results came to be viewed as in teresting and w orthy of publication [45–47]. T o explore the consequences of this effect, w e consider a mo del in whic h the probability of publishing a negativ e outcome increases linearly from a baseline v alue ρ b when b elief in the claim is w eak, to a maxim um v alue of ρ 0 = 1 when b elief in the claim is strong. W e assume that the probability of publishing a negativ e outcome is ρ 0 = ρ b + q (1 − ρ b ), where ρ b is the baseline probability for publishing negativ e outcomes, and q is the curren t b elief. As before, our agen ts are una ware of an y publication bias in updating their own b eliefs. Figure 9 indicates that dynamic publication rates can mark edly reduce (though not eliminate) the false canon- ization rate under man y scenarios. In particular, Fig. 9 suggests that even if it is difficult to publish negativ e out- comes for claims already susp ected to b e false, we can still accurately sort true claims from false ones provided that negativ e outcomes are more readily published for claims nearing canonization. In practice, this mechanism may 0 0.2 0.4 0.6 0.8 1 A α =.25 α =.2 α =.15 α =.1 α =.05 B α =.25 α =.2 α =.15 α =.1 α =.05 0 0.2 0.4 0.6 0.8 0 0.2 0.4 0.6 0.8 C α =.25 α =.2 α =.15 α =.1 α =.05 0 0.2 0.4 0.6 0.8 1 D Baseline of negative publication rate Probability of canonizing false claim as fact α =.25 α =.2 α =.15 α =.1 α =.05 = .2 = .4 β β τ = .1 0 τ 1 = .9 0 τ = .001 = .999 τ 1 FIG. 9. Publishing a larger fraction of negativ e out- comes as b elief increases lessens the c hances of can- onizing false claims . Probability that a false claim is mis- tak enly canonized as a true fact vs. baseline probabilit y of publishing a negative outcome. The baseline probability of publishing a negative outcome is the probabilit y that pre- v ails when b elief in the claim is w eak. The actual probability of publishing a negative outcome increases linearly from the baseline rate when b elief is 0 to a v alue of 1 when b elief is 1. All other parameters are the same as in Fig. 4. pla y an imp ortant role in preven ting false results from b ecoming canonized more frequently . IV. DISCUSSION In the mo del of scien tific inquiry that w e hav e de- v elop ed here, publication bias creates serious problems. While true claims will seldom b e rejected, publication bias has the p oten tial to cause man y false claims to b e mistak enly canonized as facts. This can b e av oided only if a substantial fraction of negative results are published. But at present, publication bias app ears to b e strong, giv en that only a small fraction of the published sci- en tific literature presents negative results. Presumably man y negative results are going unrep orted. While this problem has b een noted b efore [48], w e do not kno w of an y previous formal analysis of its consequences regard- ing the establishment of scien tific facts. A. Should scien tists publish all of their results? There is an active debate ov er whether science func- tions most effectively when researc hers publish all of their results, or when they publish only a select subset of their findings [15, 42, 43, 49]. In our mo del, we observe no ad- 11 v antage to selectiv e publication; in all cases treated we find that false canonization decreases monotonically with increasing publication of negative results. This seems log- ical enough. Decision theory affirms that in the absence of information costs, withholding information cannot on a verage improv e p erformance in a decision problem suc h as the classification task we treat here [50 – 52]. As Goo d [51] notes, a decision-mak er “should use all the evidence alr e ady a v ailable, provided that the cost of doing so is negligible.” Nonetheless, sev eral researc h groups hav e argued that selectiv e publishing can b e more efficien t than publishing the results of all studies. Clearly they m ust b e implic- itly or explicitly imposing costs of some sort on the acts of publishing pap ers or reading them, and it can b e in- structiv e to see where these costs lie. One source of such costs comes simply from the increased volume of scien- tific literature that ensues when all results are published; this is sometimes known as the “cluttered office” effect [49]. If w e envision that searc h costs increase with the v olume of literature, for example, it ma y b e beneficial not to publish ev erything. Another possible cost is that of actually writing a pa- p er and going through the pu blication pro cess. If prepar- ing a pap er for publication is costly relative to doing the exp erimen ts whic h would b e reported, it may be adv an- tageous to publish only a subset of all exp erimental re- sults. This is the argument that de Win ter and Happ ee mak e when, in a mathematical mo del of point estima- tion, they find that selective publication minimizes the v ariance given the numb er of public ations (as opp osed to the num b er of exp erimen ts conducted). Note, how ever, that they assume a mo del of science in which exp erimen ts are only published when they con tradict the prev ailing wisdom—and that their results ha ve been roundly chal- lenged in a follo wup analysis [43]. McElreath and Smaldino [15] analyzed a mo del that is more similar to ours in structure. As w e do, they consider rep eated tests of binary-v alued hypotheses. But rather than fo cusing on a single claim at a time, they mo del the progress of a group of scien tists testing a suite of hy- p otheses. Based on this mo del, McElreath and Smaldino conclude that there can b e adv antages to selective pub- lication under certain conditions. While selectiv e publication certainly can ameliorate the cluttered office problem—observ ed in their mo del as the flocking of researc hers to questions already sho wn lik ely to b e false—we are skeptical ab out the other adv an- tages to selectiv e publication. McElreath and Smaldino’s mo del and results appear to rely in part on their assump- tion that “the only information relev ant for judging the truth of a hypothesis is its tal ly , the difference b et ween the num b er of published p ositiv e and the num b er of p os- itiv e negativ e findings” (p. 3). As a mathematical claim, this is incorrect. Presumably the claim is instead intended to b e a tactical assumption that serves to simplify the analysis. But this assumption is severely limiting. The tally is often an inadequate sum- mary of the evidence in fav or of a h yp othesis. One can see the problem with lo oking only at the tally by consid- ering a simple example in which false p ositive rates are v ery low, false negative rates are high, and all studies are published. There is mild evidence that a h yp othe- sis is false if no p ositiv e studies and one negativ e study ha ve b een published, but there is strong evidence that the h yp othesis is true if three p ositiv e and four negativ e studies hav e b een published. Y et b oth situations share the same tally: − 1. The same problem arises when pub- lication bias causes p ositiv e and negative findings to b e published at different rates. If one is forced to use only the tally to mak e decisions, an agen t can sometimes make b etter inferences b y thro w- ing aw ay some of the data (i.e., under selectiv e publica- tion). F or example, when false negatives are common it ma y be b eneficial to suppress some fraction of the nega- tiv e results lest they swamp an y p ositiv e signal from true p ositiv e findings. This is not the case when the agent has access to complete information ab out the n umber of p ositiv e and the n umber of negativ e results published. As a result, it is unclear whether most of McElreath and Smaldino’s argumen ts in fav or of selective publication are relev ant to optimal scien tific inference, or whether they are consequences of the assumption that readers draw their inferences based on the tally alone. B. What do w e do ab out the problem of publication bias? Sev eral studies ha ve indicated that m uc h of the publi- cation bias observed in science can b e attributed to au- thors not writing up n ull results, rather than journals rejecting null results [23, 25, 53]. This do es not necessar- ily exonerate the journals; authors may b e resp onding to incen tives that the journals hav e put in place [22]. Au- thors may b e motiv ated by other reputational factors as w ell. It w ould be a very unusual job talk, promotion sem- inar, or grant application that was based primarily up on negativ e findings. So what can w e as a scientific comm unity do? How can w e a void canonizing too man y false claims, so that we can b e confident in the v eracity of most scientific facts? In this pap er, w e hav e sho wn that strengthening evidentiary standards do es not necessarily help. In the presence of strong publication bias, false claims become canonized as fact not so muc h b ecause of a few misleading chance results, but rather because on a verage, misleading results are more likely to be published than correct ones. F ortunately , this problem ma y b e ameliorated by sev- eral current asp ects of the publication pro cess. In this pap er, w e ha ve mo deled claims that hav e only one w ay of generating “p ositive” results. F or many scientific claims, e.g. those like our Dicer example that prop ose partic- ular mechanisms, this ma y be appropriate. In other cases, ho wev er, results ma y b e contin uous: not only do w e care whether v ariables X and Y are correlated, but 12 also we wan t to know ab out the strength of the corre- lation, for example. This do es not mak e the problem go a wa y , if stronger or highly significant correlations are seen as more w orthy of publication than weak er or non- significan t correlations. How ever, one adv antage of fram- ing exp erimen tal results as contin uous-v alued instead of binary is that there ma y be multiple opp osing directions in whic h a result could b e considered p ositive. F or ex- ample, the expression of t wo genes could b e correlated, uncorrelated, or anticorrelated. Both correlation and an- ticorrelation might b e seen as p ositiv e results, whereas the null result of no correlation could b e sub ject to pub- lication bias. But supp ose there is truly no effect: what do es publication bias do in this case? W e w ould exp ect to see false positives in b oth directions. Meta-analysis w ould readily pick up the lac k of a consisten t direction of the effect, and (if the authors av oid mistak enly inferring p opulation heterogeneity) it is unlik ely that correlations in either direction w ould be falsely canonized as fact. Our model assumes that researc h con tinues until each claim is either rejected or canonized as fact. In practice, researc hers can and do lose in terest in certain claims. F alse claims might generate more conflicting results, or tak e longer to reach one of the eviden tiary thresholds; either mechanism could lead researchers to mo ve on to other problems and lea ve the claim as unresolved. If this is the case, w e might exp ect that instead of b eing rejected or canonized as fact, man y false claims migh t simply b e abandoned. Another possible difference b et ween the mo del and the real world is that w e mo del the eviden tiary standards as symmetric, but in practice it may require less certaint y to discard a claim as false than it requires to accept the same claim as fact. In this case, the probability of reject- ing false claims w ould b e higher than predicted in our mo del—possibly with only a v ery small increase in the probabilit y of rejecting true claims. The scien tific communit y could also actively resp ond to the problem of canonizing false claims. One of the most direct wa ys w ould be to in v est more hea vily in the publication of negative results. A num b er of new jour- nals or collections within journals hav e been established to sp ecialize in publishing negativ e results. This includes Elsevier’s New Ne gatives in Plant Scienc e , PLOS One’s P ositively Negativ e collection, Biomed Cen tral’s Jour- nal of Ne gative R esults in Biome dicine , and many others [54]. Alternatively , peer reviewed publication ma y be un- necessary; simply publishing negative results on preprint arc hives suc h as the arXiv, bioRxiv, and So cArXiv ma y mak e these results sufficien tly visible. In either case, w e face an incen tive problem: if researchers accrue scan t credit or reward for their negative findings, there is little reason for them to in v est the substan tial time needed in taking a negativ e result from a b enc h-top disapp oin tment to a formal publication. Another p ossibilit y—which may already b e in pla y— in volv es shifting probabilities of publishing negativ e re- sults. W e ha ve shown that if negativ e results become easier to publish as a claim b ecomes b etter established, this can greatly reduce the probability of canonizing false claims. One p ossibilit y is that negativ e results may b e- come easier to publish as they b ecome more surprising to the communit y , i.e., as researc hers become increas- ingly convinced that a claim is true. Referees and jour- nal editors could make an active effort to v alue pap ers of this sort. At present, how ever, our experience sug- gests that negative results or even corrections of blatant errors in previous publications rarely land in journals of equal prestige to those that published the original p osi- tiv e studies [55]. A final sa ving grace is that ev en after false claims are established as facts, science can still self-correct. In this pap er, w e hav e assumed for simplicity that claims are in- dep enden t propositions, but in practice claims are en tan- gled in a web of logical in terrelations. When a false claim is canonized as fact, inconsistencies b etw een it and other facts so on b egin to accum ulate un til the field is forced to reev aluate the conflicting facts. Results that resolve these conflicts b y dispro ving accepted facts then take on a sp ecial significance and suffer little of the stigma placed up on negativ e results. Un til the scientific comm unity finds more wa ys to deal with publication bias, this may b e an essential corrective to a process that sometimes loses its wa y . A CKNOWLEDGMENTS The authors thank Luis Amaral, Jacob G. F oster, F razer Meacham, Peter Rodgers, Ludo W altman, and Kevin Zollman for helpful comments and suggestions on the manuscript. This work was supp orted by the Danish National Research F oundation and b y a generous grant to the Metaknowledge Netw ork from the John T empleton F oundation. KG thanks the Univ ersity of W ashington Departmen t of Biology for sabbatical supp ort. 13 [1] Jerome R. Rav etz. Scientific Know ledge and its So cial Pr oblems . British So ciety for the Philoso- ph y of Science, 1971. ISBN 9788578110796. doi: 10.1017/CBO9781107415324.004. [2] Samuel Arb esman. The Half-life of F acts: Why Every- thing We Know Has an Expir ation Date . Penguin, 2012. [3] Bruno Latour. Scienc e in A ction: How to F ol low Scien- tists and Engine ers thr ough So ciety . Harv ard Universit y Press, 1987. ISBN 0-674-79290-4. [4] C. Glenn Begley and Lee M. Ellis. Drug dev elop- men t: Raise standards for preclinical cancer research. Natur e , 483(7391):531–3, 2012. ISSN 1476-4687. doi: 10.1038/483531a. [5] Op en Science Collab oration. Estimating the re- pro ducibilit y of psyc hological science. Scienc e , 349 (6251):aac4716–aac4716, 2015. ISSN 0036-8075. doi: 10.1126/science.aac4716. [6] Timothy M Errington, Elizab eth Iorns, William Gunn, F raser Elisab eth T an, Jo elle Lomax, and Brian A Nosek. An op en inv estigation of the repro ducibilit y of cancer biology research. eLife , 3:e04333, 2014. ISSN 2050-084X. doi:10.7554/eLife.04333. [7] Shanil Ebrahim, Zahra N Sohani, Luis Monto ya, Ar- na v Agarw al, Kristian Thorlund, Edward J Mills, and John P a Ioannidis. Reanalyses of randomized clinical trial data. The Journal of the A meric an Me dic al Asso- ciation , 312(10):1024–32, 2014. ISSN 1538-3598. doi: 10.1001/jama.2014.9646. [8] Andrew C Chang and Phillip Li. Is Economics Research Replicable? Sixty Published Papers from Thirteen Jour- nals Say “Usually Not”. Financ e and Ec onomics Dis- cussion Series , 083:1–26, 2015. ISSN 19362854. doi: 10.17016/FEDS.2015.083. [9] Colin F Camerer, Anna Dreb er, Eskil F orsell, T eck- h ua Ho, J ¨ urgen Hub er, Mic hael Kirc hler, Johan Almen- b erg, Adam Altmejd, T aizan Chan, F elix Holzmeister, T aisuke Imai, Siri Isaksson, Gideon Nav e, Thomas Pfeif- fer, Michael Razen, and Hang W u. Ev aluating repli- cabilit y of lab oratory experiments in economics. Sci- enc e , 351(6280):1433–1436, 2016. ISSN 0036-8075. doi: 10.1126/science.aaf0918. [10] Mony a Baker. 1,500 scientists lift the lid on reproducibil- it y . Natur e , 533(7604):452–454, 2016. [11] John P A Ioannidis. Why Most Published Researc h Findings Are F alse. PLoS Me dicine , 2(8), 2005. ISSN 15491277. doi:10.1371/journal.pmed.0020124. [12] Andrew D. Higginson and Marcus R. Munaf` o. Cur- ren t Incentiv es for Scientists Lead to Underp ow ered Studies with Erroneous Conclusions. PLOS Biol- o gy , 14(11):e2000995, 2016. ISSN 1545-7885. doi: 10.1371/journal.pbio.2000995. [13] Emily Bernstein, Amy A Caudy , Scott M Hammond, and Gregory J Hannon. Role for a bidentate ribonu- clease in the initiation step of RNA interference. Na- tur e , 409(6818):363–366, 2001. ISSN 0028-0836. doi: 10.1038/35053110. [14] Luk asz Jaskiewicz and Witold Filip o wicz. Role of Dicer in p osttranscriptional RNA silencing. Curr ent T opics in Micr obiolo gy and Immunolo gy , 320:77–97, 2008. [15] Richard McElreath and Paul E. Smaldino. Replication, Comm unication, and the Population Dynamics of Scien- tific Discov ery . PL oS ONE , 10(8), 2015. ISSN 19326203. doi:10.1371/journal.p one.0136088. [16] Theo dore D Sterling. Publication Decisions and Their P ossible Effects on Inferences Drawn from T ests of Sig- nificance –Or Vice V ersa. Journal of the Americ an Sta- tistic al Asso ciation , 54(285):30–34, 1959. [17] Rob ert Rosenthal. The “File Dra wer Problem” and T olerance for Null Results. Psycholo gic al Bul letin , 86 (3):638–641, 1979. ISSN 0033-2909. doi:10.1037/0033- 2909.86.3.638. [18] Rob ert G Newcom b e. T ow ards a reduction in publication bias. British Me dical Journal , 295(6599):656–659, 1987. ISSN 0959-8138. doi:10.1136/bmj.295.6599.656. [19] Colin B Begg and Jesse A Berlin. Publication Bias: A Problem in Interpreting Medical Data. Sour c e Journal of the Royal Statistic al So ciety. Series A (Statistics in So ciety) J. R. Statist. So c. A , 151(3):419–463, 1988. ISSN 09641998. doi:10.2307/2982993. [20] Kay Dick ersin. The Existence of Publication Bias and Risk F actors for its Occurrence. The Journal of the Americ an Me dical Association , (10):1385, 1990. [21] Philippa J Easterbrook, Jesse A Berlin, Ramana Gopalan, and David R Matthews. Publication bias in clinical research. The L ancet , 337(8746):867–872, 1991. ISSN 01406736. doi:10.1016/0140-6736(91)90201-Y. [22] F. Song, A. J. Eastw o od, S. Gilb ody , L. Duley , and A. J. Sutton. Publication and related biases. He alth T e chnol- o gy Assessment , 4(10), 2000. ISSN 13665278. doi:Health T echnology Assessment. [23] Carin M Olson, Drummond Rennie, Deb orah Co ok, Kay Dic kersin, Annette Flanagin, Joseph W Hogan, Qi Zh u, Jennifer Reiling, and Brian P ace. Publication Bias in Editorial Decision Making. The Journal of the Ameri- c an Me dic al Asso ciation , 287(21):2825–2828, 2002. ISSN 00987484. doi:10.1001/jama.287.21.2825. [24] An-W en Chan and Douglas G Altman. Iden tify- ing outcome rep orting bias in randomised trials on PubMed: review of publications and survey of au- thors. BMJ , 330(7494):753, 2005. ISSN 1756-1833. doi: 10.1136/bmj.38356.424606.8F. [25] Annie F ranco, Neil Malhotra, and Gab or Simono vits. Publication bias in the so cial sciences: Unlo cking the file dra wer. Scienc e , 345(6203):1502–1505, 2014. [26] Erick H. T urner, Annette M. Matthews, Eftihia Linardatos, Rob ert A. T ell, and Robert Rosenthal. Se- lectiv e Publication of Antidepressan t T rials and Its In- fluence on Apparen t Efficacy . The New England Journal of Medicine , 358(3):252–260, 2008. ISSN 0028-4793. doi: 10.1056/NEJMsa065779. [27] Ryan D Csada, Paul C James, and Richard H M Espie. The ”File Draw er Problem” of Non-Significant Resluts: Do es It Apply to Biologica Research? Oikos , 76(3):591– 593, 1996. [28] Daniele F anelli. Negativ e results are disappearing from most disciplines and coun tries. Scientometrics , 90(3): 891–904, 2012. ISSN 01389130. doi:10.1007/s11192-011- 0494-7. [29] Andrey Rzhetsky , Iv an Iossifov, Ji Meng Loh, and Kevin P White. Microparadigms: Chains of collectiv e reasoning in publications ab out molecular interactions. Pr o c e e dings of the National A c ademy of Scienc es of the 14 Unite d States of Americ a , 103(13):4940–5, 2006. ISSN 0027-8424. doi:10.1073/pnas.0600591103. [30] James R. Norris. Markov Chains . Cambridge Universit y Press, 1998. [31] Megan L. Head, Luke Holman, Rob Lanfear, Andrew T. Kahn, and Michael D. Jennions. The Extent and Con- sequences of P-Hacking in Science. PL oS Biolo gy , 13(3), 2015. ISSN 15457885. doi:10.1371/journal.pbio.1002106. [32] Joanna Le Noury, John M Nardo, Da vid Healy , Jon Ju- reidini, Melissa Ra ven, Catalin T ufanaru, and Elia Abi- Jaoude. Restoring Study 329: efficacy and harms of paro xetine and imipramine in treatment of ma jor depres- sion in adolescence. BMJ (Clinic al r ese ar ch e d.) , 351(7): h4320, 2015. ISSN 1756-1833. doi:10.1136/bmj.h4320. [33] Ian F. T anno c k. F alse-Positiv e Results in Clinical T ri- als: Multiple Significance T ests and the Problem of Un- rep orted Comparisons. Journal of the National Canc er Institute , 88(3/4):206–207, 1996. [34] George Dav ey Smith and Shah Ebrahim. Data dredg- ing, bias, or confounding. BMJ (Clinic al r ese ar ch e d.) , 325(7378):1437–1438, 2002. ISSN 09598138. doi: 10.1136/bmj.325.7378.1437. [35] Norb ert L Kerr. HARKing: Hyp othesizing After the Re- sults are Known. Personality and So cial Psycholo gy R e- view , 2(3):196–217, 1998. [36] Andrew Gelman and Eric Loken. The Statistical Crisis in Science. Americ an Scientist , 102(6):460–465, 2014. [37] Stuart J P o cock, Michael D Hughes, and Rob ert J Lee. Statistical Problems in the Reporting of Clinical T rials. The New England Journal of Me dicine , 317(7):426–32, 1987. ISSN 0028-4793. doi: 10.1056/NEJM198708133170706. [38] Anders Eklund, Thomas E. Nichols, and Hans Knutsson. Cluster failure: Why fMRI inferences for spatial extent ha ve inflated false-p ositiv e rates. Pr o c e edings of the Na- tional A c ademy of Scienc es , page 201602413, 2016. ISSN 0027-8424. doi:10.1073/pnas.1602413113. [39] Benjamin Kasenda, Erik von Elm, John J Y ou, Anette Bl ¨ umle, Y uki T omonaga, Ramon Saccilotto, Alain Am- stutz, Theresa Bengough, Joerg J Meerp ohl, Mihaela Ste- gert, et al. Agreemen ts betw een industry and academia on publication righ ts: A retrosp ective study of proto cols and publications of randomized clinical trials. PL oS Me d , 13(6):e1002046, 2016. [40] Jonathan Silv ertown and Kevin J. McConw ay . Does “Publication Bias” Lead to Biased Science? Oikos , 79 (1):167–168, 1997. [41] John P A Ioannidis and Thomas A. T rik alinos. Early ex- treme contradictory estimates may app ear in published researc h: The Proteus phenomenon in molecular genet- ics research and randomized trials. Journal of Clinic al Epidemiolo gy , 58(6):543–549, 2005. ISSN 08954356. doi: 10.1016/j.jclinepi.2004.10.019. [42] Jo ost de Win ter and Riender Happ ee. Why Selectiv e Publication of Statistically Significant Results Can Be Effectiv e. PL oS ONE , 8(6), 2013. ISSN 19326203. doi: 10.1371/journal.p one.0066463. [43] Marcel A L M v an Assen, Robbie C M v an Aert, Mic h` ele B Nuijten, and Jelte M Wicherts. Wh y Publishing Everything Is More Effective than Se- lectiv e Publishing of Statistically Significant Results. PL oS ONE , 9(1), 2014. ISSN 1932-6203. doi: 10.1371/journal.p one.0084896. [44] R P oulin. Manipulation of host b eha viour b y parasites: a w eakening paradigm? Pr oc ee dings of the Royal So ciety of L ondon B: Biologic al Scienc es , 267(1445):787–792, 2000. [45] Leigh W Simmons, J L T omkins, J S Kotiaho, and J Hunt. Fluctuating paradigm. Pro c e e dings of the R oyal So ciety of L ondon B: Biolo gic al Scienc es , 266(1419):593– 595, 1999. ISSN 0962-8452. doi:10.1098/rspb.1999.0677. [46] A. Richard Palmer. Quasi-Replication and the Contract of Error: Lessons from Sex Ratios, Heritabilities and Fluctuating Asymmetry . A nnual R eview of Ec olo gy and Systematics , 31(1):441–480, 2000. [47] Michael D Jennions and Anders P Møller. Relation- ships fade with time: a meta-analysis of temporal trends in publication in ecology and evolution. Pr o- c e e dings of the R oyal So ciety of L ondon B: Biolo gic al Scienc es , 269(1486):43–48, 2002. ISSN 0962-8452. doi: 10.1098/rspb.2001.1832. [48] Jonathan Knight. Negativ e results: Null and void. Na- tur e , 422(6932):554–555, 2003. ISSN 0028-0836. doi: 10.1038/422554a. [49] Leif D Nelson, Joseph P Simmons, and Uri Simon- sohn. Let’s Publish F ewer Papers. Psycholo gic al In- quiry , 233(23):291–293, 2012. ISSN 1532-7965. doi: 10.1080/1047840X.2012.705245. [50] Leonard J. Sav age. The foundations of statistics . John Wiley & Sons, 1954. [51] I. J. Go o d. On the Principle of T otal Evidence. British Journal for the Philosophy of Scienc e , 17(4):319–321, 1967. [52] F. P . Ramsey . W eight or the V alue of Kno wledge. The British Journal for the Philosophy of Scienc e , 41(1):1–4, 1990. [53] Kay Dick ersin, Y uan-I Min, and Curtis L Meinert. F ac- tors influencing publication of research results. F ollow- up of applications submitted to tw o institutional review b oards. The Journal of the Americ an Me dic al Asso cia- tion , 267(3):374–8, 1992. [54] Editors. Go forth and replicate! Natur e , 536:373, 2016. [55] Natalie Matosin, Elisabeth F rank, Martin Engel, Jerem y S Lum, and Kelly a Newell. Negativit y to wards negativ e results: a discussion of the disconnect b etw een scien tific worth and scientific culture. Dise ase Models & Me chanisms , 7(2):171–3, 2014. ISSN 1754-8411. doi: 10.1242/dmm.015123.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment