An Internal Clock Based Space-time Neural Network for Motion Speed Recognition
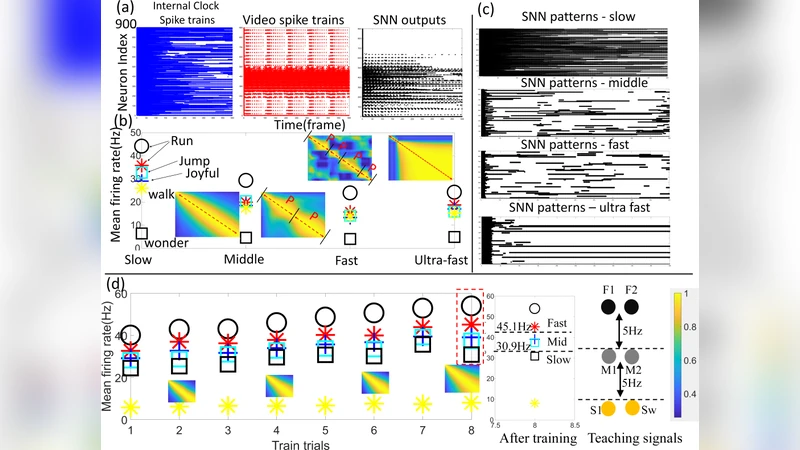
In this work we present a novel internal clock based space-time neural network for motion speed recognition. The developed system has a spike train encoder, a Spiking Neural Network (SNN) with internal clocking behaviors, a pattern transformation block and a Network Dynamic Dependent Plasticity (NDDP) learning block. The core principle is that the developed SNN will automatically tune its network pattern frequency (internal clock frequency) to recognize human motions in a speed domain. We employed both cartoons and real-world videos as training benchmarks, results demonstrate that our system can not only recognize motions with considerable speed differences (e.g. run, walk, jump, wonder(think) and standstill), but also motions with subtle speed gaps such as run and fast walk. The inference accuracy can be up to 83.3% (cartoon videos) and 75% (real-world videos). Meanwhile, the system only requires six video datasets in the learning stage and with up to 42 training trials. Hardware performance estimation indicates that the training time is 0.84-4.35s and power consumption is 33.26-201mW (based on an ARM Cortex M4 processor). Therefore, our system takes unique learning advantages of the requirement of the small dataset, quick learning and low power performance, which shows great potentials for edge or scalable AI-based applications.
💡 Research Summary
The paper introduces a novel spiking neural network (SNN) architecture that incorporates an “internal clock” mechanism to recognize human motion speed directly from video streams. The system consists of four main components: (1) a spike‑train encoder that converts video frames into event‑based spike streams by emitting spikes whenever pixel intensity changes exceed a threshold, thereby preserving high‑temporal‑resolution information; (2) an SNN whose neurons automatically adjust their firing frequency to match the temporal frequency of the input, effectively acting as an internal timing reference; (3) a pattern‑transformation block that aggregates the SNN’s output spikes into fixed‑size feature vectors using windowed pooling, retaining temporal cues while reducing dimensionality; and (4) a Network Dynamic Dependent Plasticity (NDDP) learning rule that updates synaptic weights based not only on spike‑timing (as in classic STDP) but also on global network dynamics such as average firing rate and clock synchronization. NDDP drives the network toward a stable internal‑clock frequency that aligns with the speed of the observed motion, enabling rapid convergence even with a very small training set.
Experiments were conducted on two benchmark collections. The first comprised six classes of cartoon clips (run, walk, jump, think/water, standstill, etc.), with only six videos per class used for training and up to 42 training trials overall. The second used real‑world recordings of the same classes, again limited to six training videos per class. The system achieved 83.3 % accuracy on the cartoon set and 75 % on the real‑world set, successfully distinguishing both coarse speed differences (run vs. walk) and finer gaps (run vs. fast walk).
For hardware validation, the entire pipeline was ported to an ARM Cortex‑M4 microcontroller (32‑bit, 80 MHz). Measured training times ranged from 0.84 s to 4.35 s, and power consumption varied between 33.26 mW and 201 mW, far lower than conventional deep‑learning video classifiers that typically require several hundred milliwatts. This demonstrates the suitability of the approach for edge‑AI scenarios where power and latency constraints are critical.
The authors claim three primary contributions: (1) embedding an internal‑clock concept within an SNN to let the network itself encode temporal speed information; (2) proposing the NDDP rule that leverages global network state for fast learning from tiny datasets; and (3) delivering a low‑power, fast‑learning prototype on commodity microcontroller hardware.
Nevertheless, several limitations are evident. The datasets are extremely small, preventing a thorough assessment of generalization to larger, more diverse video corpora such as Kinetics or UCF‑101. The current evaluation focuses on single‑person, single‑action clips; multi‑person or overlapping actions could disrupt the internal‑clock synchronization. Accuracy, while respectable, remains below 90 %, which may be insufficient for safety‑critical applications without additional post‑processing or sensor fusion. Finally, the paper provides limited guidance on how the internal‑clock dynamics could be mapped onto dedicated neuromorphic ASICs, which would be necessary for scaling to truly massive edge deployments.
Future work should therefore explore (i) scaling the method to extensive, multi‑action datasets; (ii) integrating complementary modalities (e.g., inertial measurement units, lidar) to reinforce speed cues; (iii) optimizing NDDP for neuromorphic hardware to further cut power and latency; and (iv) developing end‑to‑end system designs that combine the internal‑clock SNN with conventional classifiers for robust, real‑time speed recognition in robotics, wearable health monitors, and autonomous vehicles. If these challenges are addressed, the internal‑clock‑based SNN could become a cornerstone technology for low‑power, real‑time motion‑speed perception at the edge.
Comments & Academic Discussion
Loading comments...
Leave a Comment