On Solving Cooperative MARL Problems with a Few Good Experiences
Cooperative Multi-agent Reinforcement Learning (MARL) is crucial for cooperative decentralized decision learning in many domains such as search and rescue, drone surveillance, package delivery and fire fighting problems. In these domains, a key challenge is learning with a few good experiences, i.e., positive reinforcements are obtained only in a few situations (e.g., on extinguishing a fire or tracking a crime or delivering a package) and in most other situations there is zero or negative reinforcement. Learning decisions with a few good experiences is extremely challenging in cooperative MARL problems due to three reasons. First, compared to the single agent case, exploration is harder as multiple agents have to be coordinated to receive a good experience. Second, environment is not stationary as all the agents are learning at the same time (and hence change policies). Third, scale of problem increases significantly with every additional agent. Relevant existing work is extensive and has focussed on dealing with a few good experiences in single-agent RL problems or on scalable approaches for handling non-stationarity in MARL problems. Unfortunately, neither of these approaches (or their extensions) are able to address the problem of sparse good experiences effectively. Therefore, we provide a novel fictitious self imitation approach that is able to simultaneously handle non-stationarity and sparse good experiences in a scalable manner. Finally, we provide a thorough comparison (experimental or descriptive) against relevant cooperative MARL algorithms to demonstrate the utility of our approach.
💡 Research Summary
The paper tackles a critical yet under‑explored problem in cooperative multi‑agent reinforcement learning (MARL): learning when positive reinforcement is extremely sparse, i.e., “few good experiences.” While single‑agent RL has a rich literature on sparse‑reward techniques and MARL has many methods for handling non‑stationarity and scalability, none of the existing approaches simultaneously address the challenges posed by rare positive outcomes in a cooperative multi‑agent setting.
The authors first articulate why this scenario is especially difficult. Coordination of exploration across agents is required to obtain any good experience; the environment becomes non‑stationary because all agents are learning concurrently; and the joint state‑action space grows exponentially with the number of agents, making sample efficiency critical.
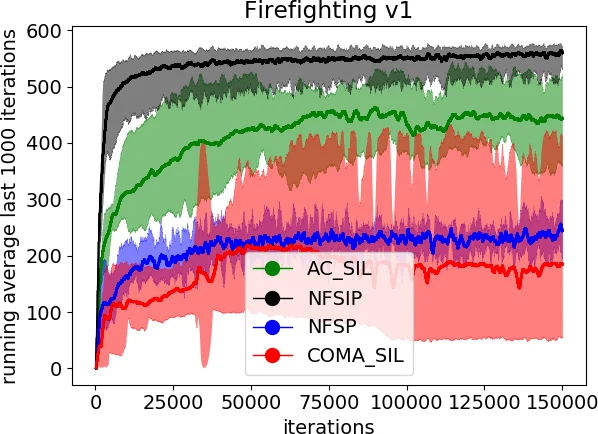
To solve these intertwined issues, the authors extend Neural Fictitious Self‑Play (NFSP)—a scalable approximation of fictitious play that combines a Deep Q‑Network (DQN) for approximate best‑response learning with a supervised‑learning network for the average policy—by adding a self‑imitation mechanism. The resulting algorithm, Neural Fictitious Self‑Imitation Play (NFSIP), introduces several novel components:
-
Experience Prioritisation Based on Social Welfare – After each episode, if the cumulative reward of the whole team (social welfare) exceeds the best‑so‑far threshold, the episode’s trajectory is stored in a prioritized self‑imitation buffer (M_SI) together with its cumulative per‑step rewards. This ensures that only genuinely useful “good” experiences are replayed.
-
Learning from All Buffers – Standard NFSP updates are retained: the DQN (Q‑network) is trained on a replay buffer of all transitions (M_RL) using the usual Bellman loss, while the average‑policy network (π) is trained on a buffer of past best‑response actions (M_SL) via a negative‑log‑likelihood loss.
-
Self‑Imitation Loop – At the end of each episode, the algorithm samples from M_SI and updates both Q‑ and π‑networks only when the current Q‑estimate under‑predicts the stored cumulative reward. The loss incorporates a positive‑part term (
Comments & Academic Discussion
Loading comments...
Leave a Comment