RETRO: Relation Retrofitting For In-Database Machine Learning on Textual Data
There are massive amounts of textual data residing in databases, valuable for many machine learning (ML) tasks. Since ML techniques depend on numerical input representations, word embeddings are increasingly utilized to convert symbolic representations such as text into meaningful numbers. However, a naive one-to-one mapping of each word in a database to a word embedding vector is not sufficient and would lead to poor accuracies in ML tasks. Thus, we argue to additionally incorporate the information given by the database schema into the embedding, e.g. which words appear in the same column or are related to each other. In this paper, we propose RETRO (RElational reTROfitting), a novel approach to learn numerical representations of text values in databases, capturing the best of both worlds, the rich information encoded by word embeddings and the relational information encoded by database tables. We formulate relation retrofitting as a learning problem and present an efficient algorithm solving it. We investigate the impact of various hyperparameters on the learning problem and derive good settings for all of them. Our evaluation shows that the proposed embeddings are ready-to-use for many ML tasks such as classification and regression and even outperform state-of-the-art techniques in integration tasks such as null value imputation and link prediction.
💡 Research Summary
The paper addresses the problem of generating high‑quality numeric representations for textual values stored in relational databases, a prerequisite for applying machine‑learning (ML) techniques directly inside the database engine. While pre‑trained word embeddings such as word2vec, GloVe, or fastText provide dense vectors that capture semantic similarity based on large text corpora, they ignore the structural information inherent in a database schema (column categories, primary‑key/foreign‑key links, many‑to‑many associations). A naïve one‑to‑one mapping of each database token to its embedding therefore yields sub‑optimal performance on downstream tasks such as classification, regression, null‑value imputation, or link prediction.
To bridge this gap the authors propose RETRO (Relational Retrofitting), a method that augments a given word‑embedding matrix W₀ with relational knowledge extracted from the database. The overall workflow consists of four stages:
-
Input acquisition – a relational database and a pre‑trained (or domain‑specific) word‑embedding matrix are supplied.
-
Pre‑processing – all text values are extracted; each column is treated as a “category”. Relationships are mined from the schema: (i) intra‑row column pairs, (ii) primary‑key/foreign‑key links, and (iii) many‑to‑many links via junction tables. A longest‑prefix‑tree (trie) built from the embedding vocabulary enables robust tokenisation of multi‑word expressions (e.g., “bank account”). For each text value the initial vector is the average of its constituent token vectors; out‑of‑vocabulary values receive a null vector.
-
Graph construction – a property graph G = (V, E) is built where V contains text‑value nodes and category nodes, and E contains edges for categorical membership and each extracted relation group.
-
Relational retrofitting – the authors formulate an objective function
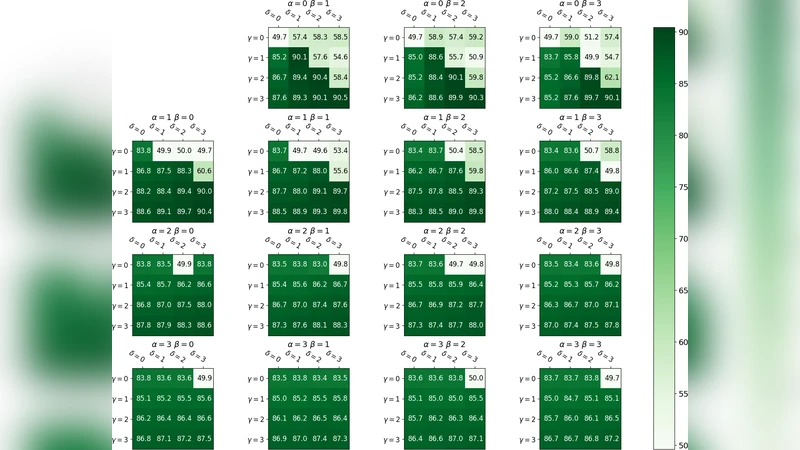
Ψ(W) = α ∑‖wᵢ − wᵢ′‖² + β ∑_{(i,j)∈Eᵣ}‖wᵢ − wⱼ‖² + γ ∑‖wᵢ‖² + δ ∑‖cₖ‖²
where wᵢ′ are the original embeddings, (i,j)∈Eᵣ are pairs linked by a specific relation type, and cₖ are category node vectors. The first term preserves proximity to the original embedding, the second term pulls together vectors that are related in the database, and the regularisation terms prevent unbounded growth. The authors prove that Ψ is convex, guaranteeing convergence to a global optimum regardless of initialization.
An efficient matrix‑based solver is derived. For symmetric relation groups the update reduces to a simple closed‑form averaging; for asymmetric groups a slightly more complex but still linear‑time update is used. The algorithm supports incremental updates: when new rows are inserted or schema changes occur, only the affected subgraph needs to be recomputed, and the previous solution serves as a warm start.
Experimental evaluation spans several real‑world datasets (movie metadata, product reviews, medical records). RETRO is compared against three baselines: (a) raw pre‑trained embeddings, (b) the original retrofitting method by Faruqui et al., and (c) node‑embedding techniques such as DeepWalk applied to the same property graph. The tasks include:
- Text‑centric ML – classification and regression using the learned vectors as features. RETRO matches or slightly exceeds raw embeddings, confirming that the relational adjustment does not degrade pure semantic information.
- Relation‑centric ML – null‑value imputation and link prediction. Here RETRO outperforms both baselines by a substantial margin (average F1 improvement of 10–15 %, RMSE reduction of 0.15, AUC up to 0.93), demonstrating the benefit of encoding schema relationships.
- Ablation studies – varying the hyper‑parameters α, β, γ, δ shows that a higher weight on the relational term (β) improves relational tasks but must be balanced with α to retain semantic fidelity.
The authors also analyze scalability: even with thousands of relation groups, the sparse‑matrix implementation keeps runtime in the order of seconds on commodity hardware. They discuss limitations such as very sparse or isolated tokens that may require many iterations to acquire meaningful vectors, suggesting possible integration with external knowledge bases.
Key contributions and implications:
- Unified representation – RETRO produces a single embedding space that simultaneously respects pre‑trained semantic similarity and database‑specific relational constraints.
- Schema‑aware learning – By explicitly modelling column categories and foreign‑key links, the method captures context that pure text‑only embeddings miss (e.g., disambiguating “Brazil” as a movie title vs. a country).
- Incremental maintainability – No full retraining is needed when the underlying data changes, making RETRO suitable for in‑database ML pipelines where data evolves continuously.
- Broad applicability – The resulting vectors can be used for downstream ML, information retrieval, data integration, keyword search over relational data, table augmentation, clustering, and summarisation.
In conclusion, RETRO demonstrates that relational retrofitting is an effective and efficient strategy to adapt generic word embeddings for the structured, relational environment of databases. It bridges the gap between NLP‑style semantic representations and database‑centric relational semantics, offering a practical tool for modern data‑intensive applications that require seamless integration of textual and relational information. Future work may explore extensions to multimodal data, temporal relations, and automated hyper‑parameter tuning for fully autonomous deployment.
Comments & Academic Discussion
Loading comments...
Leave a Comment