Recognizing Images with at most one Spike per Neuron
In order to port the performance of trained artificial neural networks (ANNs) to spiking neural networks (SNNs), which can be implemented in neuromorphic hardware with a drastically reduced energy consumption, an efficient ANN to SNN conversion is ne…
Authors: Christoph St"ockl, Wolfgang Maass
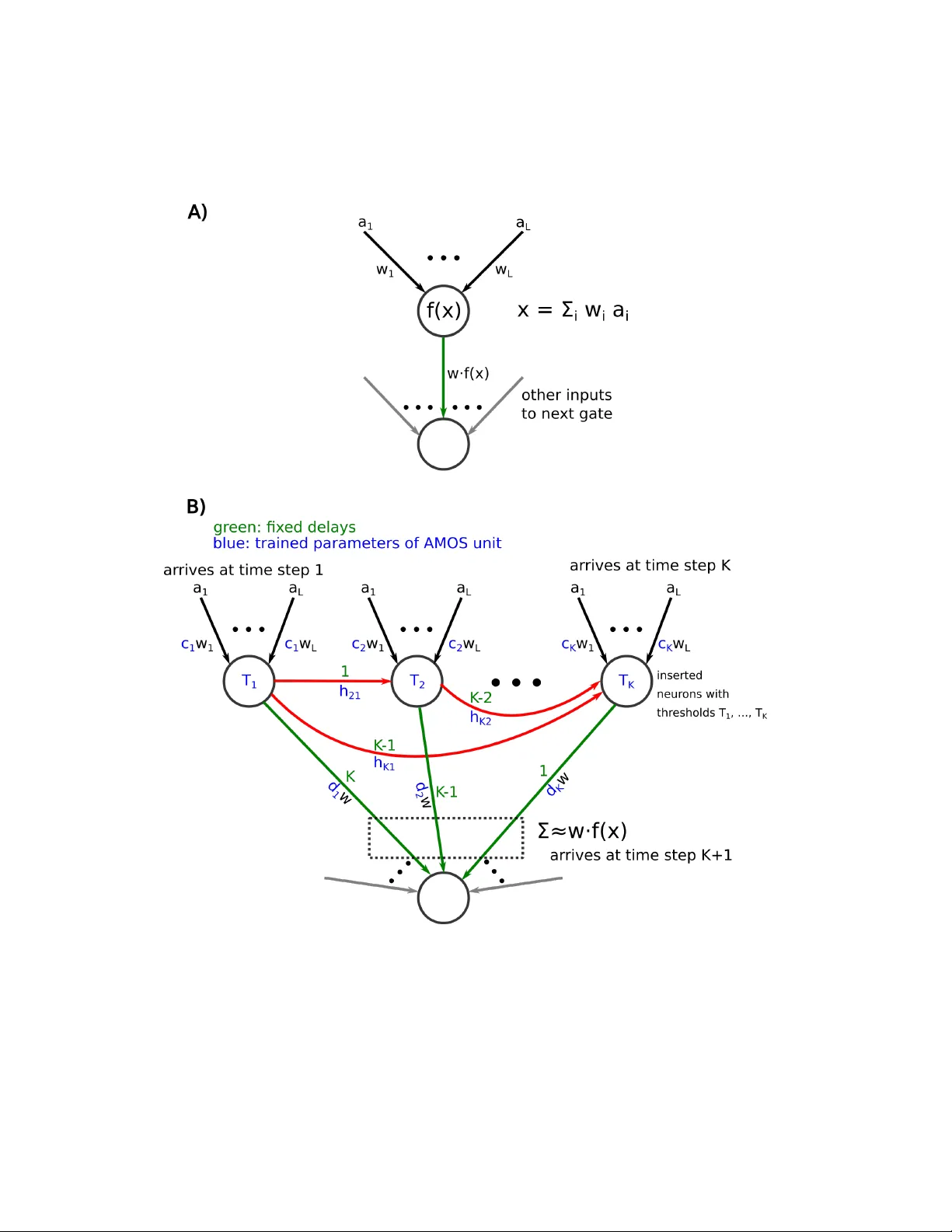
Recognizing Images with at most one Spik e p er Neuron Christoph St¨ oc kl 1 , W olfgang Maass 1 , ∗ Jan uary 22, 2020 1 Institute of Theoretical Computer Science, Graz Univ ersity of T echnology , Inffeldgasse 16b, Graz, Austria ∗ T o whom corresp ondence should b e addressed; E-mail: maass@igi.tugraz.at. Abstract In order to p ort the p erformance of trained artificial neural net works (ANNs) to spiking neural net works (SNNs), whic h can b e implemen ted in neuromorphic hard- w are with a drastically reduced energy consumption, an efficient ANN to SNN con- v ersion is needed. Previous con version schemes fo cused on the representation of the analog output of a rectified linear (ReLU) gate in the ANN b y the firing rate of a spiking neuron. But this is not p ossible for other commonly used ANN gates, and it reduces the throughput ev en for ReLU gates. W e introduce a new con version metho d where a gate in the ANN, which can basically be of any t yp e, is em ulated by a small circuit of spiking neurons, with At Most One Spike (AMOS) p er neuron. W e sho w that this AMOS conv ersion improv es the accuracy of SNNs for ImageNet from 74.60% to 80.97%, thereby bringing it within reac h of the best a v ailable ANN accu- racy (85.0%). The T op5 accuracy of SNNs is raised to 95.82%, getting even closer to the b est T op5 p erformance of 97.2% for ANNs. In addition, AMOS conv ersion impro ves latency and throughput of spik e-based image classification by sev eral orders of magnitude. Hence these results suggest that SNNs pro vide a viable direction for dev eloping highly energy efficien t hardware for AI that com bines high p erformance with versatilit y of applications. In tro duction Spiking neural netw orks (SNNs) are among the leading candidates to solv e one of the ma- jor imp ediments of more widespread uses of mo dern AI: The energy consumption of the v ery large artificial neural netw orks (ANNs) that are needed. These ANNs need to b e large, since they need to hav e a sufficiently large n um b er of parameters in order to absorb enough information from the h uge data sets on which they are trained, such as the 1.2 million images of ImageNet2012. Inference on these large ANNs is p o wer h ungry 1 (Garc ´ ıa-Mart ´ ın et al., 2019), which imp edes their deploymen t in mobile devices or au- tonomous vehicles. Spiking neurons ha ve b een in the fo cus of recent w ork on nov el com- puting hardw are for AI with a drastically reduced energy budget, because the gian t SNN in the brain –consisting of about 100 billion neurons– consumes just 20W (Ling, 2001). Most spiking neuron mo dels that are considered in neuromorphic hardware are in fact inspired b y neurons in the brain. Their output is a train of stereotypical electrical pulses –called spik es. Hence their output is very different from the analog n umbers that an ANN neuron pro duces as output. But whereas large ANNs, trained with ever more sophisticated learning algorithms on gian t data sets, approach –and sometimes exceed– h uman p erformance in several categories of in telligence, the p erformance of SNNs is lagging b ehind. One strategy for closing this gap is to design an ANN-to-SNN conv ersion that enables us to p ort the p erformance of a trained ANN in to an SNN. The most common –and so far b est p erforming—con version metho d was based on the idea of (firing-) rate co ding, where the analog output of an ANN unit is em ulated by the firing rate of a spiking neuron (Rueck auer et al., 2017). This metho d can readily b e used for ANN units that are based on the ReLU (rectified linear) activ ation function. It has pro duced impressiv e results for professional b enchmark tasks suc h as ImageNet, but a significant gap to the accuracy , latency , and throughput of ANN solutions has thw arted its practical application. Problems with the timing and precision of resulting firing rates on higher lev els of the resulting SNNs ha v e been cited as p ossible reasons for the loss in accuracy of the SNN. In addition, the transmission of an analog v alue through a firing rate requires a fairly large num b er of time steps –typically in the order of 100, whic h reduces b oth latency and throughput for inference. An additional imp edimen t for a rate-based ANN-to-SNN con v ersion emerged more recen tly in the form of b etter performing ANNs such as Efficien tNet (T an and Le, 2019). They employ the Swish function as activ ation function, defined b y x · sigmoid( x ), whic h con tains more complex non linearities than the ReLU function. F urthermore, the Swish function also pro duces negativ e v alues that can not b e readily enco ded by the – necessarily non-negativ e – firing rate of a spiking neuron. W e in tro duce a new ANN-to-SNN conv ersion metho d that we call AMOS con version b ecause it requires A t-Most-One-Spike (AMOS) per neuron. This metho d is obviously very differen t from rate-based conv ersions, and structurally more similar to temp oral co ding, where the delay of a single spik e is used to enco de an analog v alue. How ever temp oral co ding has turned out to b e difficult to implemen t in a noise-robust and efficien t man- ner in neuromorphic hardware. This arises from the difficulty to implement delays with sufficien tly high precision without sacrificing latency or throughput of the SNN, and the difficult y to design spiking neurons that can efficien tly process suc h temporal code (Maass and Natschl¨ ager, 1998), (Thorp e et al., 2001), (Ruec k auer et al., 2017), (Kheradpisheh and Masquelier, 2019). In contrast, AMOS co ding requires just on the order of log N differen t delays for transmitting integers b etw een 1 to N. F urthermore, these delays can b e arranged in a data-indep endent manner that supp orts pipelining, so that a new image can b e pro cessed by the SNN at every time step. W e show that even the simplest type of spiking neuron, the McCullo ch Pitts neuron 2 or threshold gate (McCulloch and Pitts, 1943) can efficiently compute with AMOS co des. Th us no temp oral integration of information is needed for the spiking neuron mo del in order to efficiently emulate inference by ANNs. This simple version of a spiking neuron had previously already been used for image classification b y SNNs in hardware (Esser et al., 2016). W e will describe in the first subsection of Results the design of an AMOS unit that replaces the gate of an ANN –with basically an y activ ation function—in this new ANN- to-SNN conv ersion. W e then show that this conv ersion pro duces an SNN that carries out inference for classifying images from the full ImageNet2012 dataset with drastically impro ved accuracy , latency , and throughput. Whereas the design of the AMOS unit for the con version of ANN-neurons with the Swic h function requires training of its parameters, one can design an AMOS unit for the sp ecial case of the ReLU activ ation function explicitly: It reduces in this sp ecial case to an analog-to-digital conv ersion via binary co ding. This will b e made explicit in the last subsection of Results. 1 Results 1.1 Arc hitecture of the AMOS unit W e present in Fig. 1B the arc hitecture of an AMOS unit –consisting of K spiking neurons– that approximates a generic ANN gate with activ ation function f shown in Fig. 1A. Besides fixed delays (sho wn in green) the AMOS unit con tains weigh t co efficients c 1 , ..., c K , d 1 , ..., d K , h ij for i, j ∈ { 1 , . . . , K } , and thresholds T 1 , ..., T K (sho wn in blue). The case that the activ ation function f of an ANN gate outputs p ositive and negative n umbers is of particular imp ortance in view of the Swish function (see Fig. 5) that was in tro duced in (Zoph and Le, 2018) and used as activ ation function in EfficientNet (T an and Le, 2019). It is defined by Swish( x ) = x · 1 1 + e − x . (1) Neuron i in the AMOS unit outputs z i = Θ( c i · x − H i − T i ) , (2) where Θ is the Hea viside activ ation function defined by Θ( x ) = ( 0 , if x < 0 1 , if x ≥ 0 , (3) the co efficien t c i and the threshold T i are trained parameters, and H i is an inhibitory input defined b y H i = i − 1 X j =1 h ij z j (4) 3 Figure 1: Ar chite ctur e of an AMOS unit, c onsisting of K spiking neur ons. A) An ANN gate with activation function f that is to b e emulate d by the AMOS unit. B) The AMOS unit r e c eives the same inputs a 1 , . . . , a L , duplic ate d K times. It outputs after K + 1 time steps an appr oximation of the value w f ( x ) which the ANN gate sends to subse quent gates. 4 Figure 2: AMOS appr oximation of a function f ( x, y ) with two input values x, y , e.g. x · y with trained negative weigh ts h ij . The output y of the AMOS unit, which is fed into subsequen t AMOS units that emulate subsequen t gates to which the ANN that it em ulates is connected (only one subsequent gate is sho wn for simplicity in Fig. 1), can b e written as y = K X i =1 w d i z j , (5) where the d i are additional trained weigh ts of the AMOS unit, and w is the w eigh t of the corresp onding connection from the ANN gate in Fig. 1A to the next ANN gate. Thus the computational function of the en tire AMOS unit can b e expressed as AMOS( x ) = y = K X i =1 w · d i · Θ( c i · x − H i − T i ) . (6) F or the case of functions f ( x, y ) with t wo input v alues x and y , one just needs to replace the motif of Fig. 1A in Fig. 1 b y the motif indicated in Fig. 2B. This c hanges equation 2 to: z i = Θ( c i · x + c 0 i · x 0 − H i − T i ) (7) 5 1.2 Appro ximation of some common ANN gates b y AMOS units In the case of the ReLU activ ation function no training of the parameters of the AMOS unit from Fig. 1B is needed. If one defines its thresholds T j b y 2 K − j and weigh ts d j , c j , h ij b y c j = 1 , d j = 2 K − j , h ij = 2 K − j , an AMOS unit with K neurons pro duces an approxima- tion ReLU( x ) of the activ ation function ReLU(x) that deviates for x from 0 by at most α 2 − K for an approximation in the interv al from −∞ to α , for an y α ∈ R . The resulting appro ximation is plotted in Fig. 3. F or the case of other gate functions f we train the additional weigh ts and thresholds of the AMOS unit through bac kpropagation, using a triangle-shap ed pseudo-deriv ativ e in place of the non-existing deriv ative of the Hea viside function. Results of such appro xima- tions are plotted in Fig. 4 - 6 for the case of the sigmoid function, Swish function, and m ultiplication. Note that the AMOS unit can b e used in a pip elined manner, pro cessing K different inputs x in its K time steps. Hence the resulting SNN can be used in a pip elined manner, pro cessing a new netw ork input at each time step. Hence its throughput is m uc h b etter than that of SNNs that result from rate-based ANN-to-SNN conv ersions, such as for example (Ruec k auer et al., 2017; Sengupta et al., 2019). The n um b er of neurons in the net work is increased through the AMOS conv ersion by some factor. How ev er a hardware implemen tation can reuse AMOS units for multiple time steps (since all AMOS units hav e the same in ternal parameters), thereb y reducing the required size of the net work at the cost of a corresp onding reduction of the throughput. Figure 3: AMOS appr oximation of the R eLu function, K = 10 , (r e d: tar get function, blue: AMOS appr oximation) 6 Figure 4: AMOS appr oximation of the sigmoid function, K = 8 (r e d: tar get function, blue: AMOS appr oximation) Figure 5: AMOS appr oximation of the Swish function, K = 12 , (r e d: tar get function, blue: AMOS appr oximation) 7 Figure 6: Appr oximation err or of the tr aine d AMOS unit for multiplic ation with K = 40 (MSF = 0.0102). 1.3 Application of the AMOS con version to image classification with SNNs The ImageNet data set (Russak ovsky et al., 2015) has b ecome the most p opular b enc hmark for image classification in mac hine learning (w e are using here the ImageNet2012 version). This data set consists of 1 . 281 . 167 training images and 50 . 000 test images (b oth RGB images of different sized), that are lab eled by 1000 different categories. Classifying imaged from ImageNet is a nontrivial task even for a h uman, since this data set contains for example 59 categories for birds of different sp ecies and gender (V an Horn et al., 2015). This may explain why a relaxed p erformance measurement, where one records whether the target class is among the top 5 classifications that are prop osed b y the neural net work (”T op5”), is typically m uch higher. A new record in ANN p erformance for the classification of images from the ImageNet 2012 dataset w as ac hieved by (T an and Le, 2019). They introduced a new ANN family called Efficien tNet, that ac hieved 84.4%. With a modified training pro cedure it can ac hieve 85% accuracy (Cubuk et al., 2019). The parameters of the trained netw ork are publicly a v ailable ∗ . This accuracy w as achiev ed by the EfficientNet-B7 mo del that has 66M parameters. Besides a new scaling metho d for balancing net work depth, width, and image resolution, they also in tro duced the Swish function as activ ation function, instead of ReLU. The Swish function emerged from automatic searc h for b etter p erforming activ ation functions (Zoph and Le, 2018). Other nonlinearities that are used in Efficien tNet are sigmoids and m ultipli- cation. These o ccur in ”Squeeze and Excitation La y ers” (Hu et al., 2018) of EfficientNet, ∗ h ttps://storage.go ogleapis.com/cloud-tpu-c heckpoints/efficien tnet/randaug/efficientnet-b7- randaug.tar.gz 8 see Fig. 7. The main building blo c k of the EfficientNet architecture is the mobile inv erted b ottlenec k (Sandler et al., 2018), which uses depthwise separable con v olutions. This type of con v olutional la yer uses neurons with linear activ ation functions. Although it would certainly b e p ossible to appro ximate linear functions using AMOS conv ersion, w e simply collapsed linear la y ers into the generation of the weigh ted sums that form the inputs to the next la yers. W e ev aluated the classification p erformance of the SNN that results from an application of the AMOS conv ersion describ ed in the previous section to Efficien tNet-B7. The resulting SNN ac hiev ed a classification p erformance of 80 . 97%, and 95 . 82% for T op5; see T able 1. The v alues for K used in the AMOS conv ersion are listed in T able 3 . Mo del # params ANN SNN # la yers # neurons # spikes Efficien tNet-B7 66M 85% (97.2%) 80.97% (95.82%) 4605 3110M 1799M ResNet50 26M 75.22% (92.4%) 75.10% (92.36%) 500 96M 14M T able 1: Performanc e r esults for ANNs and the SNNs, that r esult fr om their AMOS c on- version on ImageNet. T op5 ac cur acy is given in p ar entheses. #layers and #neur ons r efer to the SNN version of the network. Spike numb ers r efer to infer enc e for a sample test image. Note that the resulting SNNs ha v e an optimal throughput, since they can classify a new image at each time step. SNNs that result from a rate-based ANN con version need up to 3000 time steps for reaching maxim um accuracy , hence their throughput is b y a corresp onding factor smaller. The n um b er of parameters is increased by the AMOS con version only b y a small additiv e term (see T able 3), since all AMOS units of the same t yp e use the same parameters. The accuracy of 75.22% for the ANN version of ResNet50 in T able 1 resulted from training a v ariant of ResNet50 where max po oling was replaced b y av erage p o oling, using the h yp erparameters giv en in the T ensorFlo w rep ository . This accuracy is close to the b est published p erformance of 76% for ResNet50 ANNs (T an and Le, 2019, T able 2). Apart from max-p o oling, ResNets use neither Swish nor sigmoid or multiplication as nonlinearities, just ReLU. This explains why the application of the AMOS con version to ResNet yields SNNs whose T op1 and T op5 performance is almost indistinguishable from the ANN v ersion. Note also that the resulting SNNs are only sparsely activ e, an activity regime that enhances the energy efficiency of some hardw are implementations. The b est previous p erformance of an SNN on ImageNet was achiev ed b y conv erting an Inception-v3 mo del (Szegedy et al., 2016) with a rate-based conv ersion scheme (Ruec k auer et al., 2017). The rep orted test accuracy of the resulting SNN w as 74.6%, where 550 time steps were used to simulate the mo del. Hence already the application of AMOS conv ersion to ResNet50 impro ves this result with regard to accuracy , and esp ecially with regard to throughput. The AMOS con v ersion of Efficien tNet-B7 yields an additional 5 . 87% accuracy impro vemen t. 9 Mo del ANN SNN # neurons # spik es ResNet50 92.99% 92.42% 4.751.369 647.245 ResNet20 91.58% 91.45% 1.884.160 261.779 ResNet14 90.49% 90.39% 1.310.720 190.107 ResNet8 87.22% 87.05% 737.280 103.753 T able 2: SNN p erformanc es on CIF AR10 that r esult fr om AMOS c onversions of R esNet mo dels of differ ent depths. (using K = 10 in the AMOS units) #neur ons r efers to the SNN version. 1.4 Results for the classification of images from the CIF AR10 data set The results for the ANN versions of ResNet that are given in T able 2 are the outcome of training them with the hyperparameters giv en in the T ensorFlow mo dels repository . They are v ery close to the best results reported in the literature. The b est ResNet on CIF AR10 is the ResNet110, where a test accuracy of 93.57% has b een rep orted (He et al., 2016). Our ResNet50 achiev es 92.99%, whic h is v ery close to the p erformance of the ResNet56 with 93.03%. Spiking v ersions of ResNet20 ha v e already been explored (Sengupta et al., 2019). Using a rate-based conv ersion sc heme a p erformance of 87.46% was rep orted. Compared to these results, AMOS con v ersion yields a higher accuracy , while also using significan tly few er time steps, thereb y reducing latency for inference. In addition, the throughput is reduced from a rather lo w v alue to the theoretically ideal v alue of one image p er time step. 1.5 T rade-off b et ween latency and net work size of the SNNs It is w ell-known that the extraction of bits from a w eigh ted sum, as well as m ultiplication of binary n umbers, can be carried out b y threshold circuits –hence also b y SNNs– with a small n umber of lay ers –t ypically 2 or 3– that do es not dep end on the bit length of the binary n umbers inv olved, ho w ever at the cost of increasing the num b er of neurons to a low-degree p olynomial of this bit length. A recen t summary of such results is provided in section 3 of (Parekh et al., 2018). Hence one can replace the basic architectures of the AMOS units from Fig. 1 and 2 b y the more shallo w arc hitectures that emplo y a larger num b er of spiking neurons. In order to mak e the resulting circuits applicable to larger input domains, one can train their parameters, similarly as for the basic architectures. Hence there exists a trade-off b etw een the n umber of lay ers (latency) and the size of the SNN that can b e ac hieved through an AMOS con version, and several p oin ts on this trade-off curve can b e reac hed through these mo dified AMOS con versions. 10 2 Metho ds 2.1 Squeeze and Excitation in EfficientNet Figure 7: Squeeze and Excitation Lay er 2.2 Num b er of parameters of AMOS units Appro ximation Num b er of parameters Sigmoid (K=8) 52 ReLU (K= 10) 75 Swish (K=12) 102 Mult (K= 40) 940 T able 3: Number of parameters in the AMOS units that are used in this article Discussion W e hav e introduced a new metho d for conv erting ANNs to SNNs. Since the resulting SNN uses for inference at most one spik e (AMOS) p er neuron, AMOS conv ersion can b e seen as 11 dual to the familiar rate-based conv ersion, since it uses space – i.e., more neurons – rather than time for replacing analog v alues by spik es. This conv ersion significan tly improv es accuracy , latency , and esp ecially the throughput of the resulting SNN. F urthermore, since AMOS conv ersion can b e applied to virtually any t yp e of ANN gate, it demonstrates for the first time that SNNs are universal computing devices from the p ersp ectiv e of mo dern ANN-based machine learning and AI. F or the classification of natural images, it raises the accuracy of SNNs for the full ImageNet 2012 dataset to 80.97% – and to 95.82% for T op5 – thereby bringing it into the range of the b est ANN and human p erformance. This was ac hieved b y conv erting Efficien tNets, a recently proposed v arian t of ANNs that employ the Swish function as neural activ ation function, for which a rate-based con v ersion to SNNs is imp ossible. The resulting SNNs that achiev e high p erformance are – like their ANN coun terparts – very large. But one can sacrifice some of their accuracy by starting with a smaller ANN, or by reducing their p erfect throughput of one image p er step and reuse gates of a smaller SNN with online reconfigurable connections and parameters. Note that reuse of neurons would b e more problematic for rate-based SNN computations, since each spiking neuron is o ccupied there during a fairly large and somewhat unpredictable num b er of time steps when em ulating a computation step of an ANN gate. In contrast, AMOS con version pro vides a tight b ound on the num b er of time steps during which a spiking neuron is o ccupied. Hence it can also b e used for con verting recurren tly connected ANNs to SNNs. Altogether the prop osed metho d for generating highly p erformant SNNs offers an op- p ortunit y to combine the computationally more efficient and functionally more p ow erful training of ANNs with the sup erior energy-efficiency of SNNs for inference. Note that one can also use the AMOS-con verted SNN as initialization for subsequent direct training of the SNN for a more sp ecific task. Altogether our results suggest that spik e-based hard- w are may gain an edge in the comp etition for the dev elopmen t of drastically more energy efficien t hardw are for AI applications b y com bining energy efficiency and competitive p er- formance with a versatilit y that optimized hardware for specific ANNs –suc h as a sp ecific t yp e of con volutional neural net works— cannot offer. Ac kno wledgemen ts W e would like to thank F ranz Scherr for helpful discussions. This research was partially supp orted b y the Human Brain Pro ject of the Europ ean Union (Grant agreement num b er 785907). References Cubuk, E. D., Zoph, B., Shlens, J., and Le, Q. V. (2019). RandAugmen t: Practical data augmen tation with no separate search. arXiv.or g:1909.13719 . Esser, S. K., Merolla, P . A., Arth ur, J. V., Cassidy , A. S., Appuswam y , R., Andreopoulos, 12 A., Berg, D. J., McKinstry , J. L., Melano, T., Barc h, D. R., Di Nolfo, C., Datta, P ., Amir, A., T aba, B., Flickner, M. D., and Modha, D. S. (2016). Conv olutional net works for fast, energy-efficien t neuromorphic computing. Pr o c e e dings of the National A c ademy of Scienc es of the Unite d States of A meric a , 113(41):11441–11446. Garc ´ ıa-Mart ´ ın, E., Ro drigues, C. F., Riley , G., and Grahn, H. (2019). Estimation of energy consumption in mac hine learning. Journal of Par al lel and Distribute d Computing , 134:75–88. He, K., Zhang, X., Ren, S., and Sun, J. (2016). Deep residual learning for image recognition. Pr o c e e dings of the IEEE Computer So ciety Confer enc e on Computer Vision and Pattern R e c o gnition , 2016-Decem:770–778. Hu, J., Shen, L., and Sun, G. (2018). Squeeze-and-Excitation Netw orks. Pr o c e e dings of the IEEE Computer So ciety Confer enc e on Computer Vision and Pattern R e c o gnition , pages 7132–7141. Kheradpisheh, S. R. and Masquelier, T. (2019). S4NN: temp oral backpropagation for spiking neural net works with one spik e p er neuron. Ling, J. (2001). https://hypertextbook.com/facts/2001/JacquelineLing.shtml . Maass, W. and Natschl¨ ager, T. (1998). Em ulation of hopfield net works with spiking neurons in temp oral co ding. In Computational Neur oscienc e , pages 221–226. Springer. McCullo c h, W. and Pitts, W. (1943). A logical calculus of the ideas immanent in nervous activit y . In: Bul letin of Mathematic al Biophysics, Bd. 5 , page 115–133. P arekh, O. D., Phillips, C. A., James, C. D., and Aimone, J. B. (2018). Constant-depth and sub cubic-size threshold circuits for matrix multiplication. T echnical report, Sandia National Lab.(SNL-NM), Albuquerque, NM (United States). Ruec k auer, B., Lungu, I. A., Hu, Y., Pfeiffer, M., and Liu, S. C. (2017). Con version of con tinuous-v alued deep netw orks to efficient even t-driv en netw orks for image classifica- tion. F r ontiers in Neur oscienc e , 11(DEC):1–12. Russak ovsky , O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., Huang, Z., Karpathy , A., Khosla, A., Bernstein, M., Berg, A. C., and F ei-F ei, L. (2015). ImageNet Large Scale Visual Recognition Challenge. International Journal of Computer Vision , 115(3):211– 252. Sandler, M., Ho ward, A., Zh u, M., Zhmoginov, A., and Chen, L. C. (2018). MobileNetV2: In verted Residuals and Linear Bottlenec ks. Pr o c e e dings of the IEEE Computer So ciety Confer enc e on Computer Vision and Pattern R e c o gnition , pages 4510–4520. 13 Sengupta, A., Y e, Y., W ang, R., Liu, C., and Roy , K. (2019). Going Deep er in Spik- ing Neural Netw orks: V GG and Residual Architectures. F r ontiers in Neur oscienc e , 13(1998):1–16. Szegedy , C., V anhouc k e, V., Ioffe, S., Shlens, J., and W o jna, Z. (2016). Rethinking the Inception Architecture for Computer Vision. Pr o c e e dings of the IEEE Computer So ciety Confer enc e on Computer Vision and Pattern R e c o gnition , 2016-Decem:2818–2826. T an, M. and Le, Q. V. (2019). EfficientNet: Rethinking Mo del Scaling for Con v olutional Neural Net works. Thorp e, S., Delorme, A., and Rullen, R. (2001). Spik e-based strategies for rapid pro cess- ing. Neur al networks : the official journal of the International Neur al Network So ciety , 14:715–25. V an Horn, G., Branson, S., F arrell, R., Hab er, S., Barry , J., Ip eirotis, P ., P erona, P ., and Belongie, S. (2015). Building a bird recognition app and large scale dataset with citizen scien tists: The fine print in fine-grained dataset collection. In Pr o c e e dings of the IEEE Confer enc e on Computer Vision and Pattern R e c o gnition , pages 595–604. Zoph, B. and Le, Q. V. (2018). Searc hing for activ ation functions. 6th International Confer enc e on L e arning R epr esentations, ICLR 2018 - Workshop T r ack Pr o c e e dings , pages 1–13. 14
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment