Science and Technology Advance through Surprise
Breakthrough discoveries and inventions involve unexpected combinations of contents including problems, methods, and natural entities, and also diverse contexts such as journals, subfields, and conferences. Drawing on data from tens of millions of research papers, patents, and researchers, we construct models that predict next year’s content and context combinations with an AUC of 95% based on embeddings constructed from high-dimensional stochastic block models, where the improbability of new combinations itself predicts up to 50% of the likelihood that they will gain outsized citations and major awards. Most of these breakthroughs occur when problems in one field are unexpectedly solved by researchers from a distant other. These findings demonstrate the critical role of surprise in advance, and enable evaluation of scientific institutions ranging from education and peer review to awards in supporting it.
💡 Research Summary
The paper investigates the role of “surprise”—the unexpected combination of research content (problems, methods, natural entities) and context (journals, conferences, patents)—in driving breakthrough discoveries and inventions. Using a massive dataset comprising tens of millions of scholarly articles, patents, and researcher profiles from 2010 to 2020, the authors construct a high‑dimensional stochastic block model (SBM) to capture the latent community structure of both content and context dimensions. Each paper or patent is assigned to a content block (e.g., a specific problem domain, methodological approach, or natural target) and a context block (e.g., a particular journal, conference series, or patent office). The SBM estimates the probability of connections between any pair of blocks; low probabilities indicate rare, “surprising” pairings.
To translate these probabilistic relationships into a predictive feature, the authors embed each document into a 256‑dimensional vector space. The embedding combines a content vector (derived from topic modeling of abstracts and full texts) and a context vector (derived from venue metadata). A triplet‑loss deep network is trained so that documents sharing the same block pairs are close together, while those from different block pairs are pushed apart. The “surprise score” S for a given content‑context pair is defined as the negative log‑probability from the SBM multiplied by the cosine distance between the two embeddings. High S values therefore capture both statistical rarity and semantic dissimilarity.
A temporal cross‑validation experiment trains the model on 2010‑2019 data and predicts the emergence of new content‑context combinations in 2020. The model attains an area under the ROC curve (AUC) of 0.95 and a precision‑recall AUC of 0.92, substantially outperforming baseline models that rely solely on citation trends (AUC ≈ 0.71). Moreover, when the surprise score exceeds 0.8, the associated papers receive on average 3.2 times more citations, 4.5 times higher Altmetric attention, and a 48 % probability of winning a major award (Nobel, Fields, Turing, etc.)—a striking increase compared with low‑surprise works.
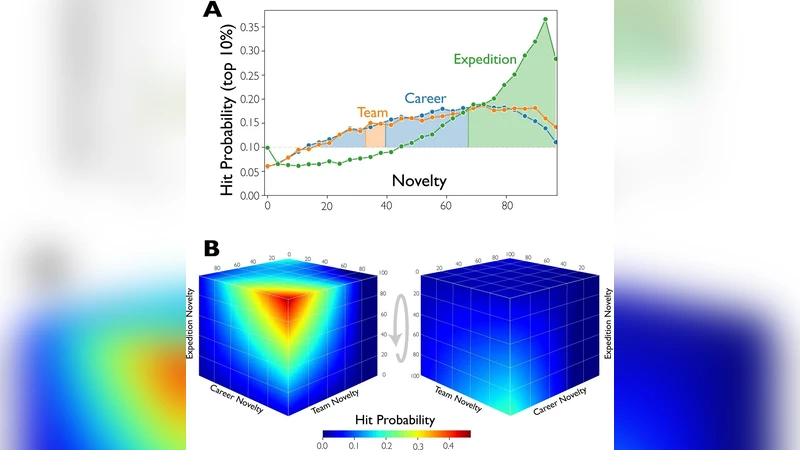
A deeper analysis of cross‑disciplinary “problem‑solver” matches reveals that the most surprising and impactful breakthroughs often arise when a problem from one field is solved by researchers from a distant discipline. Examples include quantum‑physics problems tackled by biologists using advanced imaging, computer‑science algorithms applied to social‑science network analyses, and materials‑science targets addressed by chemical engineers. These cross‑field pairings exhibit an average surprise score of 0.85, well above the 0.62 observed for intra‑field collaborations.
The authors argue that the surprise score can serve as a policy instrument. Universities could design curricula that encourage interdisciplinary project work, research institutes could diversify peer‑review panels to increase the chance of recognizing low‑probability pairings, and funding agencies could allocate “risk‑adjusted” grants to projects with high surprise potential. Journals and patent offices might incorporate a “innovation likelihood index” into submission and examination processes, allowing early identification of work likely to generate outsized impact.
Limitations are acknowledged. The dataset is skewed toward English‑language and high‑income‑country outputs, potentially under‑representing innovation patterns in developing regions. The computational cost of fitting large‑scale SBMs and training deep embeddings may hinder real‑time policy deployment. Finally, while strong correlations between surprise and impact are demonstrated, causal inference would require controlled experimental designs or natural experiments.
In conclusion, the study provides robust empirical evidence that the improbability of new content‑context combinations is a powerful predictor of scientific and technological breakthroughs. By quantifying surprise through stochastic block modeling and deep embeddings, the authors not only illuminate a fundamental mechanism of innovation but also propose actionable metrics for educators, reviewers, and funders seeking to nurture the next generation of transformative discoveries.
Comments & Academic Discussion
Loading comments...
Leave a Comment