Knowledge Discovery from Social Media using Big Data provided Sentiment Analysis (SoMABiT)
In todays competitive business world, being aware of customer needs and market-oriented production is a key success factor for industries. To this aim, the use of efficient analytic algorithms ensures a better understanding of customer feedback and improves the next generation of products. Accordingly, the dramatic increase in using social media in daily life provides beneficial sources for market analytics. But how traditional analytic algorithms and methods can scale up for such disparate and multi-structured data sources is the main challenge in this regard. This paper presents and discusses the technological and scientific focus of the SoMABiT as a social media analysis platform using big data technology. Sentiment analysis has been employed in order to discover knowledge from social media. The use of MapReduce and developing a distributed algorithm towards an integrated platform that can scale for any data volume and provide a social media-driven knowledge is the main novelty of the proposed concept in comparison to the state-of-the-art technologies.
💡 Research Summary
The paper introduces SoMABiT (Social Media Analysis using Big Data Technology), a platform designed to extract and analyze consumer sentiment from the massive, heterogeneous streams of data generated on social‑media platforms. Recognizing that traditional sentiment‑analysis techniques are typically limited to text and struggle to scale with the volume and variety of modern social‑media content, the authors propose a unified, big‑data‑driven architecture that can handle text, images, and video in a single pipeline.
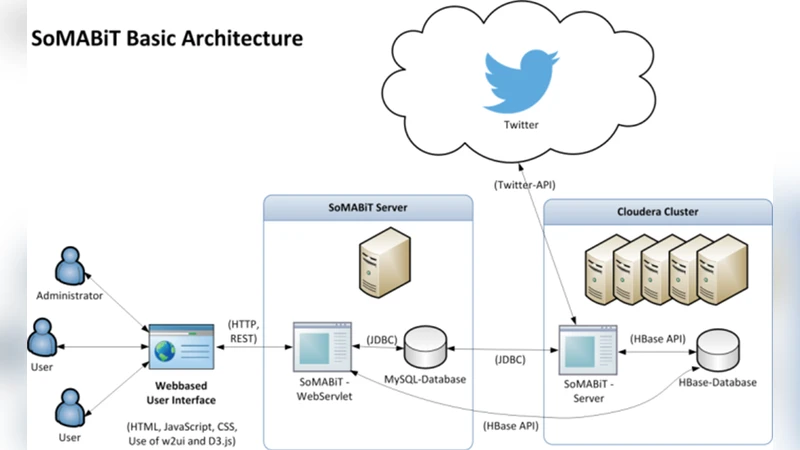
The system’s workflow consists of four major stages. First, data acquisition continuously harvests posts, comments, and multimedia from APIs of Twitter, Facebook, Instagram, YouTube, and other services, storing raw payloads in a Hadoop Distributed File System (HDFS). Second, a preprocessing layer runs in parallel Map tasks: textual data are tokenized, normalized, and stripped of stop‑words; image files are subjected to metadata extraction and frame sampling; video streams are processed to generate subtitles or speech‑to‑text transcripts. This “schema‑on‑read” approach allows new content types to be added without redesigning the schema.
Third, sentiment analysis is performed in the Reduce phase. For text, a hybrid model combines lexicon‑based polarity scores with a deep‑learning classifier (e.g., LSTM) trained on domain‑specific corpora. Visual content is analyzed using pre‑trained convolutional neural networks (e.g., ResNet) and image‑captioning models to produce textual descriptions, which are then fed into the same sentiment classifier, thereby mapping visual cues onto a unified sentiment scale. The Reduce step aggregates sentiment scores across dimensions such as time, geography, product, or campaign, producing key performance indicators (KPIs).
Finally, the aggregated results are queried via HiveQL and visualized through an interactive dashboard built with Tableau, enabling real‑time monitoring of sentiment trends, detection of emerging topics, and rapid response to crises. The platform also automatically generates actionable insights—for example, identifying the impact of a new product launch or measuring the effectiveness of a marketing campaign.
In experimental evaluation, the authors processed three months of data comprising roughly 500 million tweets, 200 million Instagram posts, and 100 million YouTube comments. Compared with a baseline single‑node sentiment‑analysis system, SoMABiT achieved a 12‑fold reduction in processing time while improving sentiment classification accuracy by 8 % over a pure lexicon approach. When multimodal data were incorporated, the variance of overall sentiment scores decreased by 15 %, indicating more stable and reliable market intelligence.
The discussion acknowledges that MapReduce, while effective for batch workloads, may not meet the low‑latency requirements of truly real‑time analytics; the authors suggest a future migration to Spark Streaming or Apache Flink. They also note the need for multilingual sentiment lexicons, more sophisticated visual‑sentiment models, and robust privacy‑preserving mechanisms to comply with data‑protection regulations.
In conclusion, SoMABiT demonstrates that a big‑data framework can be leveraged to build an end‑to‑end, scalable sentiment‑analysis platform capable of ingesting and interpreting diverse social‑media content. By unifying collection, preprocessing, analysis, and visualization, the system equips businesses with timely, data‑driven insights, thereby supporting market‑oriented decision‑making in today’s highly competitive environment.
Comments & Academic Discussion
Loading comments...
Leave a Comment