Machine Learning Testing: Survey, Landscapes and Horizons
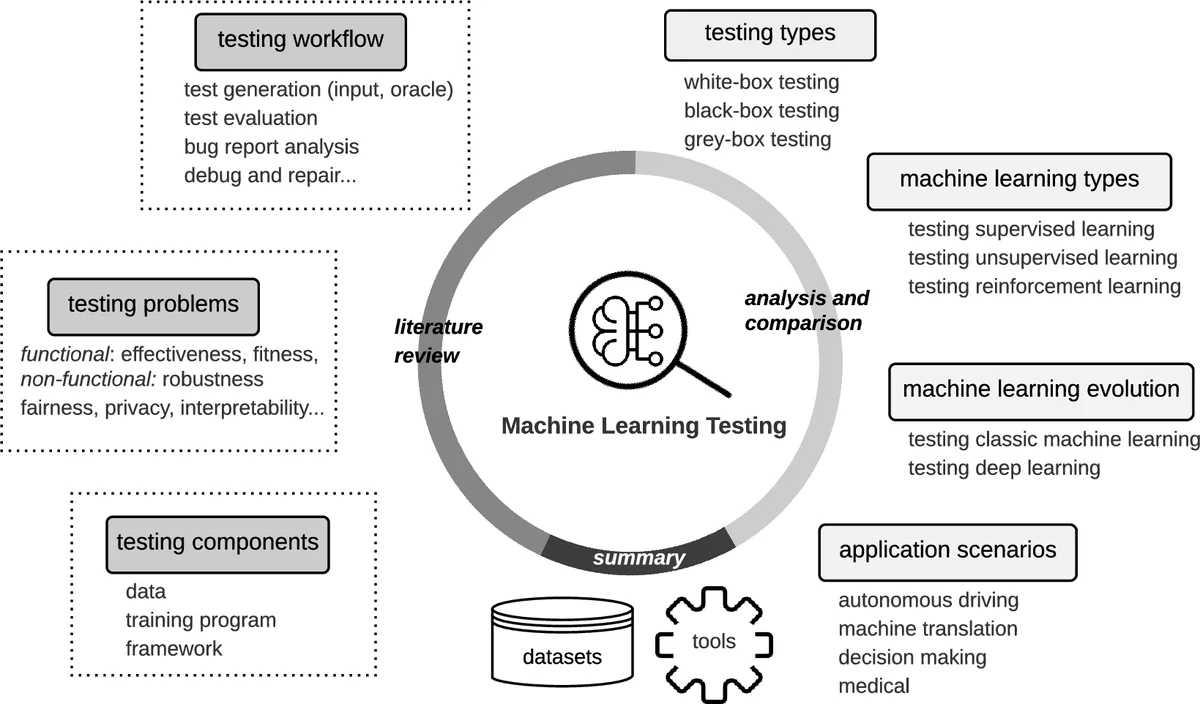
This paper provides a comprehensive survey of Machine Learning Testing (ML testing) research. It covers 144 papers on testing properties (e.g., correctness, robustness, and fairness), testing components (e.g., the data, learning program, and framework), testing workflow (e.g., test generation and test evaluation), and application scenarios (e.g., autonomous driving, machine translation). The paper also analyses trends concerning datasets, research trends, and research focus, concluding with research challenges and promising research directions in ML testing.
💡 Research Summary
This paper presents a comprehensive survey of research on Machine Learning Testing (ML testing), covering 144 papers published between 2007 and June 2019. The authors organize the literature along four orthogonal dimensions: (1) testing properties (what to test), (2) testing components (where to test), (3) testing workflow (how to test), and (4) application scenarios (where the techniques are applied).
Testing properties include correctness (accuracy), robustness, fairness, interpretability, privacy, and efficiency. The analysis shows a strong skew toward correctness and robustness—93 of the 144 papers focus on these two aspects—while fairness receives moderate attention and interpretability, privacy, and efficiency are investigated in only a handful of studies.
Testing components are broken down into three layers: the data (training, validation, test sets), the learning program (model definition, training algorithm, hyper‑parameter tuning), and the framework/library (TensorFlow, PyTorch, Scikit‑learn, etc.). The survey highlights that most bugs arise from interactions among these layers, and that error propagation can mask the true fault source, pushing testing challenges from unit‑level to integration‑ and system‑level.
The testing workflow is described as a four‑step pipeline: test input generation, oracle identification, adequacy evaluation, and bug triage. Input generation techniques range from perturbation‑based and mutation‑based methods to generative‑model driven synthesis; representative tools include DeepXplore, TensorFuzz, DeepTest, and Themis. Oracle identification is identified as the “oracle problem” because many ML tasks lack a known correct answer. The surveyed works address this by differential testing, metamorphic testing, and statistical oracles derived from ensembles. Adequacy evaluation uses metrics such as neuron coverage, activation pattern diversity, error rates, and safety‑critical thresholds. Bug triage involves fault localization across data, model, and framework, and may feed into debugging or automated repair pipelines.
Application scenarios span safety‑critical and high‑impact domains: autonomous driving, machine translation, natural language inference, medical diagnosis, and more. Each scenario brings domain‑specific constraints (e.g., real‑time response, regulatory compliance) that shape the choice of test criteria and datasets.
Trend analysis reveals a rapid growth phase: 85 % of the surveyed papers appeared after 2016, indicating that ML testing has emerged as a distinct research community. However, the distribution of effort is heavily imbalanced. Supervised learning dominates (≈120 papers), while unsupervised learning (2 % of papers) and reinforcement learning (≈1 %) receive scant attention. Moreover, most studies target correctness and robustness; only a few address interpretability, privacy, or efficiency. The authors also note a reliance on a limited set of public datasets (e.g., MNIST, CIFAR‑10, ImageNet) and a small collection of open‑source tools, suggesting a need for broader benchmark suites and standardized evaluation protocols.
The paper identifies several open challenges:
- Oracle Problem – Designing reliable oracles for tasks without ground truth, possibly via metamorphic relations, differential testing, or learned statistical models.
- Integration‑Level Fault Propagation – Understanding how errors in data, model, or framework interact and amplify, requiring system‑level testing and fault‑masking analysis.
- Continuous Learning and Drift – Maintaining test adequacy as models evolve with new data, demanding automated regression testing and drift detection mechanisms.
- Scalability and Test Prioritization – Generating and executing test suites for large deep networks without prohibitive cost, calling for test reduction, prioritization, and reinforcement‑learning‑based test generation.
- Non‑Supervised and Reinforcement Learning – Developing testing criteria and tools tailored to unsupervised clustering, representation learning, and RL policies, which lack explicit labels.
- Non‑Functional Properties – Formalizing metrics and test methods for fairness, privacy, interpretability, and efficiency, and integrating them into multi‑objective testing frameworks.
Future research directions proposed include:
- Building dedicated benchmarks and test suites for unsupervised and reinforcement learning.
- Leveraging meta‑learning and generative models to automate oracle creation and test input synthesis.
- Designing multi‑objective testing frameworks that simultaneously assess correctness, robustness, fairness, privacy, and efficiency.
- Developing standardized APIs and open‑source ecosystems that abstract over different ML frameworks, enabling cross‑platform testing.
- Applying reinforcement learning or evolutionary algorithms for test case prioritization and reduction.
- Integrating testing tightly with debugging and automated repair pipelines to close the loop from bug detection to model improvement.
In summary, the survey maps the current landscape of ML testing, highlights its concentration on supervised learning and correctness/robustness, and outlines a research agenda aimed at expanding coverage to under‑explored learning paradigms, non‑functional properties, and scalable, automated testing infrastructures. This roadmap is intended to guide both software engineering researchers and ML practitioners toward more trustworthy, reliable, and ethically sound machine learning systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment