Robustness properties of Facebooks ResNeXt WSL models
We investigate the robustness properties of ResNeXt class image recognition models trained with billion scale weakly supervised data (ResNeXt WSL models). These models, recently made public by Facebook AI, were trained with ~1B images from Instagram and fine-tuned on ImageNet. We show that these models display an unprecedented degree of robustness against common image corruptions and perturbations, as measured by the ImageNet-C and ImageNet-P benchmarks. They also achieve substantially improved accuracies on the recently introduced “natural adversarial examples” benchmark (ImageNet-A). The largest of the released models, in particular, achieves state-of-the-art results on ImageNet-C, ImageNet-P, and ImageNet-A by a large margin. The gains on ImageNet-C, ImageNet-P, and ImageNet-A far outpace the gains on ImageNet validation accuracy, suggesting the former as more useful benchmarks to measure further progress in image recognition. Remarkably, the ResNeXt WSL models even achieve a limited degree of adversarial robustness against state-of-the-art white-box attacks (10-step PGD attacks). However, in contrast to adversarially trained models, the robustness of the ResNeXt WSL models rapidly declines with the number of PGD steps, suggesting that these models do not achieve genuine adversarial robustness. Visualization of the learned features also confirms this conclusion. Finally, we show that although the ResNeXt WSL models are more shape-biased than comparable ImageNet-trained models in a shape-texture cue conflict experiment, they still remain much more texture-biased than humans, suggesting that they share some of the underlying characteristics of ImageNet-trained models that make this benchmark challenging.
💡 Research Summary
This paper conducts a thorough investigation of the robustness properties of ResNeXt‑101 models that were pre‑trained on roughly one billion Instagram images using weak supervision (WSL) and subsequently fine‑tuned on ImageNet. Five models are examined: a baseline ImageNet‑trained ResNeXt‑101 (32×8d) and four WSL variants with increasing bottleneck widths (8, 16, 32, 48), the largest containing about 829 M parameters.
The authors evaluate three families of robustness benchmarks. First, ImageNet‑C (common corruptions) and ImageNet‑P (perturbation sequences) are used to measure resistance to 15 corruption types at five severity levels and to 10 temporal perturbations, respectively. Metrics include mean corruption error (mCE), relative mCE, mean flip rate (mFR) and mean top‑5 distance (mT5D). Across all metrics, the WSL models dramatically outperform the baseline; the biggest model (32×48d) achieves mCE = 45.7 (vs. 66.6), rel. mCE = 61.8 (vs. 91.1), mFR = 27.8 (vs. 46.1) and mT5D = 52.9 (vs. 70.5). These gains far exceed the modest 3–5 % increase in clean ImageNet top‑1 accuracy, suggesting that robustness to realistic corruptions is a more discriminative measure of progress than raw accuracy.
Second, the authors test performance on ImageNet‑A, a curated set of 7,500 “natural adversarial” images that fool standard ImageNet classifiers. The WSL models achieve substantially higher accuracies than the baseline, confirming that large‑scale weakly supervised pre‑training yields representations that are less over‑reliant on texture, background, or color cues.
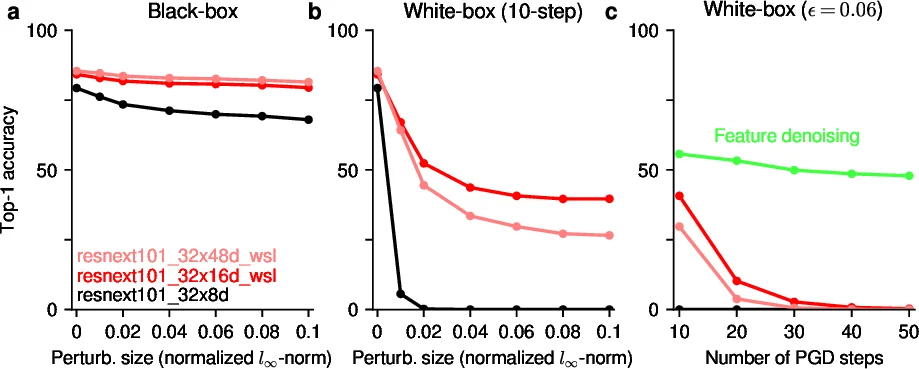
Third, adversarial robustness is examined via black‑box and white‑box projected gradient descent (PGD) attacks. In a black‑box scenario, attacks against a separate ResNeXt‑50 model succeed with <10 % top‑1 accuracy even for ε = 0.01. When the generated adversarial examples are transferred to the five ResNeXt‑101 models, the WSL variants retain higher accuracies (up to ~40 % for the 32×16d model) compared to the baseline (≈0 %). In a white‑box setting, 10‑step PGD (ε = 0.06) yields 30–40 % accuracy for the best WSL model, outperforming many adversarially trained networks. However, when the number of PGD steps is increased to 50 (same ε), accuracy collapses to near zero, indicating that the observed robustness is not genuine adversarial robustness but rather a by‑product of reduced sensitivity to small perturbations.
To probe the nature of the learned features, the authors generate “maximizing images” for units in the penultimate layer using PGD optimization. Unlike truly robust models, which produce semantically meaningful visualizations, the WSL models generate noisy, less interpretable patterns, aligning with the earlier finding that they lack true adversarial robustness.
Finally, a shape‑texture cue‑conflict experiment (Geirhos et al., 2019) reveals that WSL models are modestly more shape‑biased than the ImageNet‑trained baseline, yet they remain heavily texture‑biased relative to human perception. This suggests that merely scaling up data size does not eradicate the texture bias inherent in standard supervised training.
Overall, the study demonstrates that massive weakly supervised pre‑training dramatically improves robustness to common corruptions, perturbations, and natural adversarial examples, while offering only limited, non‑scalable adversarial robustness. The authors argue that robustness benchmarks such as ImageNet‑C, ImageNet‑P, and ImageNet‑A may serve as more informative metrics for future progress than clean ImageNet accuracy alone. The work also highlights that achieving human‑like shape bias and true adversarial immunity likely requires additional methodological innovations beyond data scaling.
Comments & Academic Discussion
Loading comments...
Leave a Comment