MaskedNet: The First Hardware Inference Engine Aiming Power Side-Channel Protection
Differential Power Analysis (DPA) has been an active area of research for the past two decades to study the attacks for extracting secret information from cryptographic implementations through power measurements and their defenses. Unfortunately, the research on power side-channels have so far predominantly focused on analyzing implementations of ciphers such as AES, DES, RSA, and recently post-quantum cryptography primitives (e.g., lattices). Meanwhile, machine-learning, and in particular deep-learning applications are becoming ubiquitous with several scenarios where the Machine Learning Models are Intellectual Properties requiring confidentiality. Expanding side-channel analysis to Machine Learning Model extraction, however, is largely unexplored. This paper expands the DPA framework to neural-network classifiers. First, it shows DPA attacks during inference to extract the secret model parameters such as weights and biases of a neural network. Second, it proposes the $\textit{first countermeasures}$ against these attacks by augmenting $\textit{masking}$. The resulting design uses novel masked components such as masked adder trees for fully-connected layers and masked Rectifier Linear Units for activation functions. On a SAKURA-X FPGA board, experiments show that the first-order DPA attacks on the unprotected implementation can succeed with only 200 traces and our protection respectively increases the latency and area-cost by 2.8x and 2.3x.
💡 Research Summary
The paper “MaskedNet: The First Hardware Inference Engine Aiming Power Side‑Channel Protection” extends differential power analysis (DPA), a technique long used against cryptographic implementations, to the domain of neural‑network inference. The authors focus on a Binarized Neural Network (BNN) that operates on binary weights and activations, implemented on a Xilinx SAKURA‑X FPGA to classify MNIST digits using three fully‑connected hidden layers of 1,024 neurons each. The hardware employs a deeply pipelined adder tree (depth 10) to compute up to 1,024 parallel partial sums, followed by a binary activation (sign function).
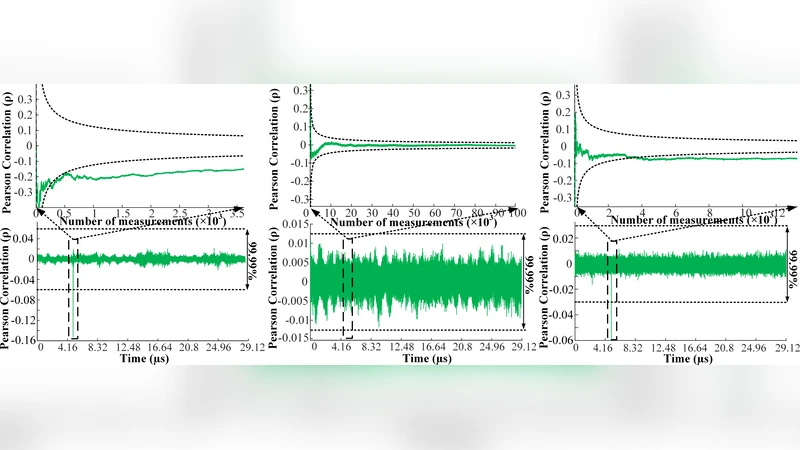
The attack model assumes an adversary with physical or remote access who can capture power traces while the device processes known inputs. By targeting the registers inside the adder pipeline—where the Hamming distance between successive cycles dominates power consumption—the attacker builds a hypothesis for each possible 4‑bit weight combination (16 possibilities). Using a cycle‑accurate Hamming‑distance simulator, the authors correlate the simulated power model with measured traces via Pearson correlation. With as few as 200 traces (≈45 k traces for high confidence), the correct weight hypothesis exceeds a 99.99 % confidence threshold, allowing full reconstruction of all weights, biases, and even activation thresholds. The attack works without needing the inference output, making it more powerful than many theoretical model‑extraction attacks.
To counter this vulnerability, the authors adapt the masking technique from cryptography to neural‑network arithmetic. Each secret value (weight, bias, intermediate sum) is split into two random shares; a fresh random mask is XOR‑ed (or added) to each share before any arithmetic operation. They design masked adder trees that operate on shared values while preserving the mask’s randomness, and a masked binary activation unit that removes the mask only after the non‑linear step. The masking is performed at the algorithmic level, ensuring that any first‑order DPA (which exploits linear leakage) sees only random noise. The design also minimizes mask‑refresh logic to keep overhead reasonable.
Experimental results on the FPGA show that the masked implementation completely suppresses the correlation peaks: even with 200 traces the attacker cannot distinguish the correct weight hypothesis. However, the security comes at a cost: latency increases by 2.8× and the area (LUTs and flip‑flops) grows by 2.3× compared with the unprotected baseline. The authors argue that this trade‑off is acceptable for edge devices where model confidentiality is critical, especially given that the BNN can be fully realized on-chip without external memory accesses, eliminating other side‑channel vectors.
The paper positions itself relative to prior work by noting that while many studies have examined physical side‑channels for cryptographic primitives, and some have theoretically explored model extraction, this is the first to demonstrate a practical power‑side‑channel attack on a parallel neural‑network accelerator and to propose a concrete hardware‑level mitigation. The contribution includes (1) a concrete DPA attack that extracts binary weights and biases from a real FPGA implementation, (2) the first masking‑based countermeasure tailored to neural‑network operations, and (3) a quantitative evaluation of security versus performance overhead. This work opens a new research direction for protecting machine‑learning intellectual property against physical attacks and suggests that techniques from cryptographic side‑channel hardening can be successfully adapted to the emerging field of secure AI hardware.
Comments & Academic Discussion
Loading comments...
Leave a Comment