Lookahead Optimizer: k steps forward, 1 step back
The vast majority of successful deep neural networks are trained using variants of stochastic gradient descent (SGD) algorithms. Recent attempts to improve SGD can be broadly categorized into two approaches: (1) adaptive learning rate schemes, such as AdaGrad and Adam, and (2) accelerated schemes, such as heavy-ball and Nesterov momentum. In this paper, we propose a new optimization algorithm, Lookahead, that is orthogonal to these previous approaches and iteratively updates two sets of weights. Intuitively, the algorithm chooses a search direction by looking ahead at the sequence of fast weights generated by another optimizer. We show that Lookahead improves the learning stability and lowers the variance of its inner optimizer with negligible computation and memory cost. We empirically demonstrate Lookahead can significantly improve the performance of SGD and Adam, even with their default hyperparameter settings on ImageNet, CIFAR-10/100, neural machine translation, and Penn Treebank.
💡 Research Summary
The paper introduces Lookahead, a novel optimization framework that operates orthogonally to existing methods such as adaptive learning‑rate schemes (AdaGrad, Adam) and acceleration techniques (heavy‑ball, Nesterov momentum). Lookahead maintains two sets of parameters: fast weights (θ) and slow weights (φ). In each outer iteration, the fast weights are initialized from the current slow weights and updated k times using any standard inner optimizer A (e.g., SGD, Adam). After these k inner‑loop updates, the slow weights are moved toward the final fast weights by a linear interpolation controlled by a step‑size α: φ←φ+α(θ_k−φ). The fast weights are then reset to the updated slow weights, and the process repeats.
The authors provide a theoretical analysis based on a noisy quadratic model L̂(x)=½(x−c)ᵀA(x−c) with c∼N(0,Σ). Assuming the same learning rate γ for both SGD and Lookahead (with SGD as the inner optimizer), they derive closed‑form expressions for the steady‑state variance of the iterates. Lookahead’s variance fixed point V*_LA is strictly smaller than SGD’s V*_SGD for any α∈(0,1), because it includes an additional damping factor α and powers of (I−γA). Consequently, Lookahead achieves a lower asymptotic risk under identical learning‑rate settings. Simulations further show that, when hyper‑parameters are chosen to reach the same steady‑state risk, Lookahead converges more quickly than SGD across a broad range of α values.
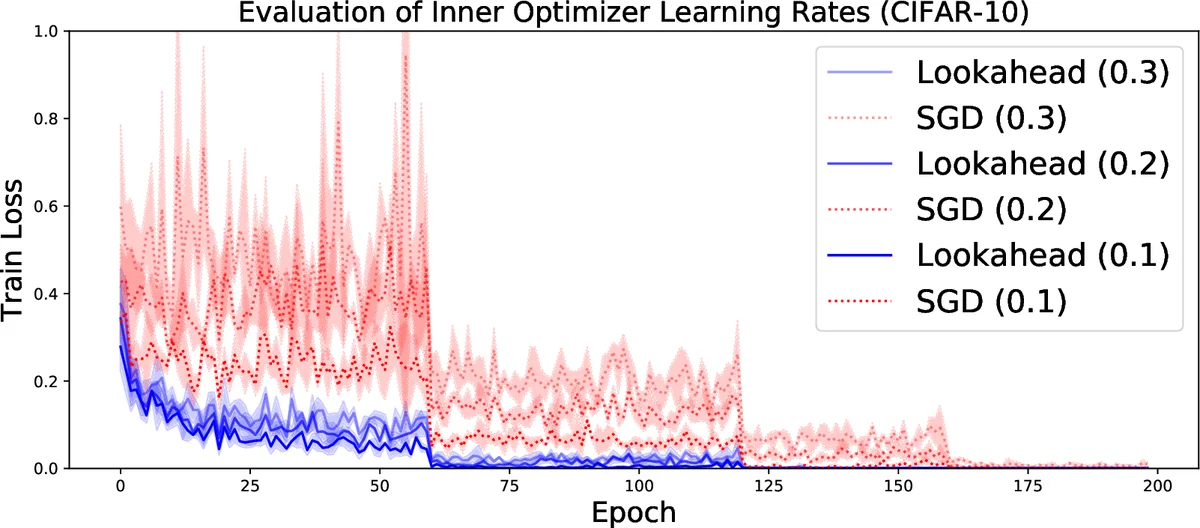
Empirically, the method is evaluated on a wide spectrum of tasks: image classification (CIFAR‑10/100, ImageNet) with ResNet‑18/32/50/152, language modeling on Penn Treebank with LSTMs, and neural machine translation on WMT 2014 English‑German using Transformers. Across all experiments, wrapping standard optimizers with Lookahead (default k≈5–10, α≈0.5) yields faster convergence and often higher final performance. For instance, on CIFAR‑10 with ResNet‑18, Lookahead‑wrapped Adam reaches 95.27 % accuracy versus 94.84 % for vanilla Adam. Moreover, Lookahead exhibits reduced sensitivity to learning‑rate and weight‑decay hyper‑parameters, diminishing the need for extensive tuning.
From a computational standpoint, Lookahead adds only a constant overhead: one extra copy of the model parameters and simple arithmetic operations performed once per outer loop. The overhead scales as O((k+1)/k) relative to the inner optimizer, making it negligible even in large‑scale distributed training.
The paper situates Lookahead among related work. Unlike Stochastic Weight Averaging (SWA), which averages checkpoints only after training, Lookahead performs continual averaging during training. It differs from Reptile, which targets meta‑learning across tasks, and from Katyusha or Anderson acceleration, which require variance‑reduction corrections or storage of many inner iterates. Lookahead’s simplicity—single interpolation after k steps—offers a practical advantage.
In summary, Lookahead provides a lightweight, theoretically grounded, and empirically validated mechanism to reduce gradient noise, stabilize training, and accelerate convergence when combined with any existing optimizer. Its minimal memory and compute footprint, together with robustness to hyper‑parameter choices, make it an attractive addition to the deep‑learning practitioner’s toolbox.
Comments & Academic Discussion
Loading comments...
Leave a Comment