Machine learning in acoustics: theory and applications
Acoustic data provide scientific and engineering insights in fields ranging from biology and communications to ocean and Earth science. We survey the recent advances and transformative potential of machine learning (ML), including deep learning, in the field of acoustics. ML is a broad family of techniques, which are often based in statistics, for automatically detecting and utilizing patterns in data. Relative to conventional acoustics and signal processing, ML is data-driven. Given sufficient training data, ML can discover complex relationships between features and desired labels or actions, or between features themselves. With large volumes of training data, ML can discover models describing complex acoustic phenomena such as human speech and reverberation. ML in acoustics is rapidly developing with compelling results and significant future promise. We first introduce ML, then highlight ML developments in four acoustics research areas: source localization in speech processing, source localization in ocean acoustics, bioacoustics, and environmental sounds in everyday scenes.
💡 Research Summary
The paper “Machine learning in acoustics: theory and applications” provides a comprehensive review of how machine learning (ML), especially deep learning (DL), is reshaping acoustic research across a wide range of domains. It begins by highlighting the ubiquity of acoustic data in biology, communications, oceanography, and Earth science, and points out that traditional physics‑based models, while interpretable, often struggle with large‑scale, noisy, or highly reverberant datasets. In contrast, data‑driven ML can automatically discover complex, nonlinear relationships given sufficient training data, offering a complementary or alternative pathway to conventional signal‑processing techniques.
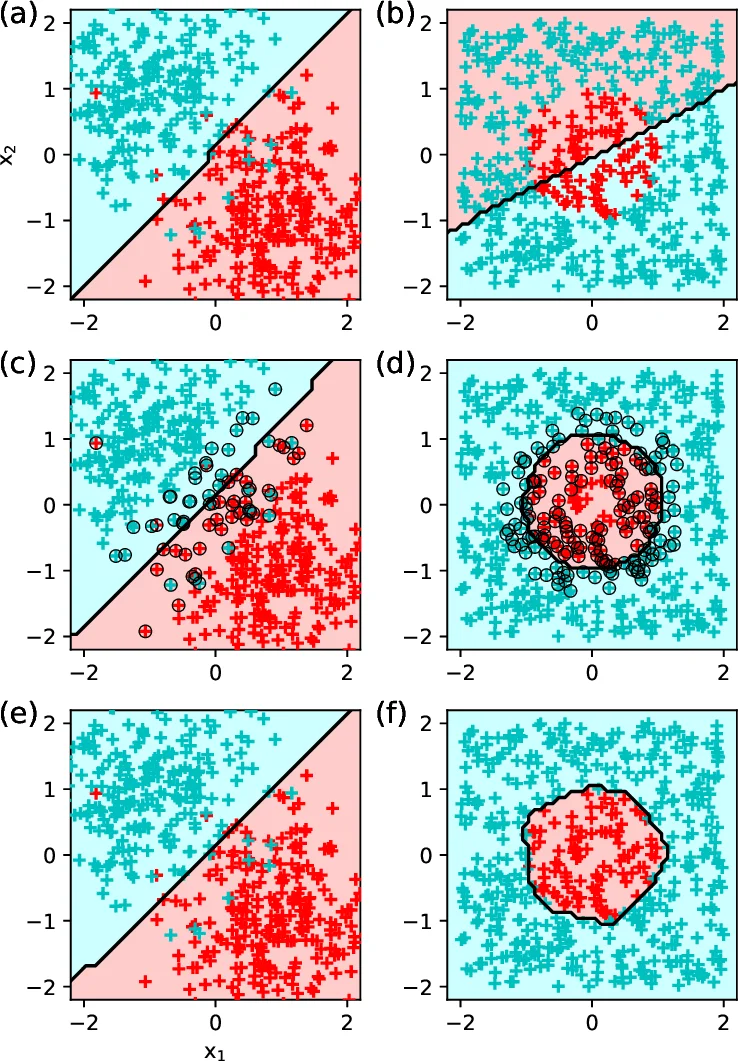
The authors first lay out the fundamental concepts of ML. They define the problem as learning a mapping (y = f(x) + \epsilon) from input features (x) (e.g., spectral coefficients, raw waveforms) to desired outputs (y) (e.g., source location, class label). Supervised learning, which relies on labeled input‑output pairs, encompasses linear regression, support‑vector machines, and neural networks. Unsupervised learning, which seeks structure without explicit labels, includes classic methods such as PCA, K‑means, and Gaussian mixture models, as well as newer techniques like t‑SNE, dictionary learning, and deep autoencoders. The paper stresses that unsupervised representations can be fed into supervised pipelines to improve performance.
A central theme is model generalization. The authors discuss capacity versus data complexity, illustrating over‑fitting and under‑fitting with a polynomial‑regression example (Figure 2). They explain how cross‑validation, separate validation sets, and hyper‑parameter tuning are essential to balance bias and variance. The no‑free‑lunch theorem is invoked to remind readers that a model optimized for one task may perform poorly on another, underscoring the importance of task‑specific design.
The deep‑learning section introduces multilayer perceptrons, convolutional neural networks (CNNs), and recurrent neural networks (RNNs/LSTMs). CNNs excel at processing spectrogram‑like 2‑D representations of sound, while RNNs capture temporal dependencies in speech or animal calls. The authors acknowledge the “black‑box” nature of deep models, the large data requirements, and the difficulty of interpreting learned features, but argue that the performance gains often outweigh these drawbacks.
Four application areas are examined in depth:
-
Speaker localization in reverberant environments – Multi‑microphone arrays combined with CNN‑based direction‑of‑arrival (DOA) estimators outperform traditional time‑difference‑of‑arrival methods, especially under high reverberation and noise.
-
Source localization in ocean acoustics – The variable sound‑speed profile and multipath propagation in the ocean are addressed with CNNs trained on simulated acoustic fields and fine‑tuned on limited real data, achieving higher positional accuracy than matched‑field processing.
-
Bioacoustics – Species identification and behavioral analysis benefit from CNN‑RNN hybrids that ingest spectrograms and model sequential patterns. Transfer learning and semi‑supervised techniques mitigate the scarcity of labeled animal calls.
-
Environmental sounds in everyday scenes – Urban sound classification and scene understanding use deep segmentation networks that simultaneously detect, label, and localize sound events, enabling multi‑task learning for both detection and context inference.
Throughout, the authors advocate for hybrid models that fuse physical insight with data‑driven learning. By embedding physics‑based constraints into loss functions or using model‑based feature extraction as a preprocessing step, one can retain interpretability while leveraging the expressive power of ML.
The paper concludes by outlining future research directions: self‑supervised learning to reduce labeling effort, model compression for real‑time deployment, Bayesian deep learning for uncertainty quantification, and multimodal integration of acoustic data with visual or environmental sensors. Overall, the review demonstrates that ML and DL have already delivered substantial performance improvements in acoustic tasks and hold promise for solving many of the remaining challenges in the field.
Comments & Academic Discussion
Loading comments...
Leave a Comment