Interactive Supercomputing on 40,000 Cores for Machine Learning and Data Analysis
Interactive massively parallel computations are critical for machine learning and data analysis. These computations are a staple of the MIT Lincoln Laboratory Supercomputing Center (LLSC) and has required the LLSC to develop unique interactive supercomputing capabilities. Scaling interactive machine learning frameworks, such as TensorFlow, and data analysis environments, such as MATLAB/Octave, to tens of thousands of cores presents many technical challenges - in particular, rapidly dispatching many tasks through a scheduler, such as Slurm, and starting many instances of applications with thousands of dependencies. Careful tuning of launches and prepositioning of applications overcome these challenges and allow the launching of thousands of tasks in seconds on a 40,000-core supercomputer. Specifically, this work demonstrates launching 32,000 TensorFlow processes in 4 seconds and launching 262,000 Octave processes in 40 seconds. These capabilities allow researchers to rapidly explore novel machine learning architecture and data analysis algorithms.
💡 Research Summary
The paper presents a comprehensive engineering effort to enable truly interactive supercomputing on a 40,000‑core TX‑Green system at MIT Lincoln Laboratory’s Supercomputing Center (LLSC). Traditional batch‑oriented job scheduling introduces latency of minutes to hours, which is unacceptable for interactive machine‑learning (ML) and data‑analysis workflows that require rapid prototyping, hyper‑parameter tuning, and real‑time data streaming. To overcome this, the authors adopt an “immediate scheduling” mode in Slurm, imposing per‑user resource limits to prevent scheduler flooding while allowing jobs to start as soon as they are submitted.
The hardware platform consists of 648 Intel Xeon Phi 7210 nodes, each providing 64 physical cores (256 hyper‑threads) and 192 GB of RAM, interconnected via 10 GbE and OmniPath. Initial attempts to launch MATLAB/Octave jobs across 40,000 cores suffered from 30‑ to 60‑minute start‑up times due to massive I/O contention on the central Lustre file system. The authors address this bottleneck through four coordinated strategies: (1) pre‑positioning complete software stacks (multiple MATLAB versions, Octave, Anaconda Python with TensorFlow, Caffe, PyTorch) on the local SSD of every compute node, eliminating remote file‑system reads; (2) creating a lightweight “MATLAB‑lite” build that omits the internal Java VM, dramatically reducing initialization overhead; (3) redesigning the launch mechanism so that a single scheduler‑issued process per node spawns all required application instances locally, thereby cutting down on per‑process launch latency; and (4) fine‑tuning Slurm parameters such as queue evaluation interval and depth to ensure rapid job admission.
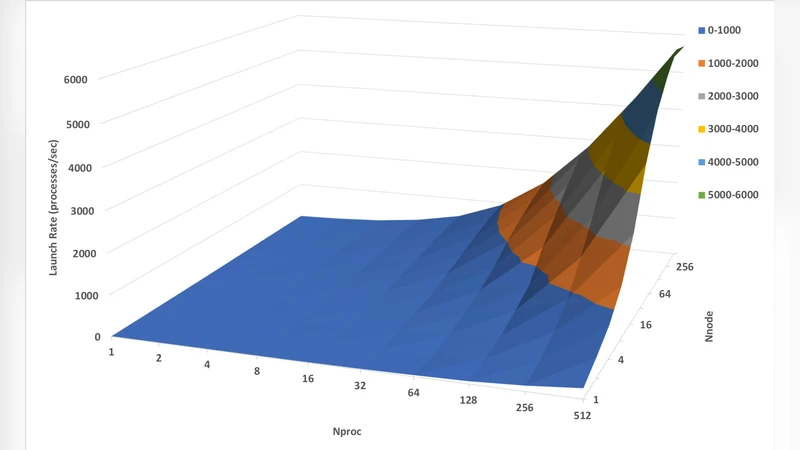
Performance measurements show that these optimizations enable the launch of 32,000 TensorFlow processes in under 4 seconds, effectively starting 5,120 independent deep‑learning models simultaneously on 512 Xeon Phi nodes. For MATLAB/Octave, the system can start 262,000 processes in 40 seconds, corresponding to roughly 6,500 launches per second. Log‑log scaling plots reveal near‑linear growth of launch time with core count, but the absolute times remain under 10 seconds for 32,000‑core workloads, satisfying the interactive latency requirements of modern ML research.
The authors discuss the trade‑offs between synchronous parallel jobs (using srun) and job arrays: while srun offers the fastest start‑up, resources remain allocated until all processes finish; job arrays release resources as each task completes, improving overall system utilization without sacrificing launch speed. By allocating whole nodes and spawning per‑core processes locally, the solution balances both latency and resource efficiency.
In conclusion, the paper demonstrates that with careful scheduler configuration, aggressive pre‑deployment of software, and lightweight launch agents, a large‑scale HPC system can support interactive, on‑demand execution of thousands of ML and data‑analysis jobs in seconds. This capability transforms the experimental workflow for researchers, enabling rapid iteration, real‑time analytics, and large‑scale hyper‑parameter sweeps that were previously impractical on supercomputers. The techniques described are broadly applicable to other HPC environments seeking to bridge the gap between batch‑oriented HPC and the interactive demands of contemporary AI and data science workloads.
Comments & Academic Discussion
Loading comments...
Leave a Comment