Emergent Structures and Lifetime Structure Evolution in Artificial Neural Networks
Motivated by the flexibility of biological neural networks whose connectivity structure changes significantly during their lifetime, we introduce the Unstructured Recursive Network (URN) and demonstrate that it can exhibit similar flexibility during training via gradient descent. We show empirically that many of the different neural network structures commonly used in practice today (including fully connected, locally connected and residual networks of different depths and widths) can emerge dynamically from the same URN. These different structures can be derived using gradient descent on a single general loss function where the structure of the data and the relative strengths of various regulator terms determine the structure of the emergent network. We show that this loss function and the regulators arise naturally when considering the symmetries of the network as well as the geometric properties of the input data.
💡 Research Summary
The paper introduces the Unstructured Recursive Network (URN), a minimalist neural architecture designed to emulate the lifelong structural plasticity observed in biological neural networks. Unlike conventional artificial neural networks (ANNs) that require a fixed architecture defined a priori, the URN starts with a completely unstructured weight matrix and a large pool of neurons, and lets the training process itself sculpt the effective topology.
Core formulation
- The URN maintains a vector N of length S, representing all neurons. The first din entries embed the input sample, the remaining entries are initially zero.
- A single dense weight matrix W (size S×S) and bias vector b are shared across I recursive update steps:
N^{(l+1)} = φ( W·N^{(l)} + b ), for l = 0,…,I‑1,
where φ is a non‑linear activation (e.g., ReLU). - After the I‑th iteration, the last dout components of N^{(I)} are read as the network output.
Loss function and regularizers
The authors augment the standard cross‑entropy loss with two L1‑type penalties:
- Weight sparsity (c_W·|W|) encourages many entries of W to become exactly zero.
- Neuron activity sparsity (c_N·∑_l |N^{(l)}|) pushes the network to deactivate unnecessary neurons at each iteration.
These regularizers are crucial: with sufficiently high coefficients, the optimization drives the system toward a minimal set of active neurons and connections, effectively “pruning” the original unstructured graph into a recognizable architecture.
Emergence of feed‑forward MLPs
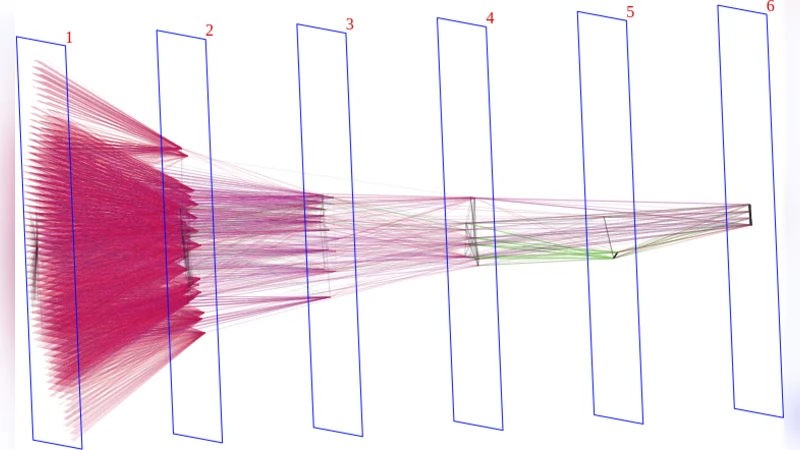
In a synthetic binary classification task (two concentric 10‑D spherical shells), the authors train a URN with S=5000 neurons and I=4 iterations. Using c_W=5×10⁻⁷ and c_N=2×10⁻⁵, the model reaches 100 % test accuracy while the number of active neurons collapses to ≈120. Visualizing the final weight matrix reveals a block‑sub‑diagonal pattern identical to a three‑layer fully‑connected MLP (input → hidden₁ → hidden₂ → hidden₃ → output). The number of effective layers matches the number of recursive steps I, confirming the hypothesis that each iteration corresponds to one logical layer when the network settles into a feed‑forward configuration.
Residual connections for dynamic depth
To allow the network to use fewer than I layers, the authors modify the update rule for output neurons to accumulate their values across iterations (a residual output scheme). This enables the network to “stop” updating the output after L ≤ I steps, effectively selecting a shallower depth when the task is simple. Experiments show that on the same spherical‑shell data, the residual‑output URN learns a single hidden layer despite I=4, because the dataset becomes linearly separable after one transformation. Conversely, on a more challenging CIFAR‑10 classification, the network utilizes the full depth (L=I), illustrating that the learned depth adapts to task difficulty.
Input‑driven locality via metric regularization
When the input possesses spatial structure (e.g., images), the authors embed the 2‑D pixel grid into the larger neuron space and define a product metric d_{ij} that combines planar distance with a perpendicular “z” dimension. They then add a synaptic‑length regularizer:
c_len·∑{i<j} |W{ij}|·d_{ij}^γ,
penalizing long‑range connections. Training a URN on monochrome CIFAR‑10 with this regularizer yields a clear locally‑connected pattern: forward weights predominantly link neurons at increasing z‑levels (akin to depth), while lateral and backward connections are heavily suppressed. Even without extensive hyper‑parameter tuning, this configuration improves test accuracy by ~10 % over a version with only weight/activity sparsity.
Discussion and future directions
The authors acknowledge that, so far, the emergent structures are primarily feed‑forward. Open questions include: under what conditions recurrent architectures appear; how to incorporate weight sharing to recover true convolutional networks; and a rigorous theoretical explanation for the bias toward feed‑forward solutions. They propose a lifelong‑learning scenario called Never‑Ending Structure Accumulation (NESA), where a URN is trained sequentially on a curriculum of increasingly difficult tasks. Preliminary results suggest that the network automatically deepens as tasks become harder, mirroring biological development.
Significance
The URN demonstrates that a single, highly over‑parameterized recursive system, guided only by a loss function and sparsity‑inducing regularizers, can self‑organize into a wide variety of useful architectures—fully‑connected MLPs, locally‑connected networks, and depth‑adaptive residual models—without any explicit architectural engineering. This points toward a paradigm where the burden of network design is shifted from manual architecture search to the design of appropriate regularizers and training curricula, potentially reducing engineering effort and bringing artificial learning systems closer to the adaptive flexibility of biological brains.
Comments & Academic Discussion
Loading comments...
Leave a Comment