Deep Denoising for Hearing Aid Applications
Reduction of unwanted environmental noises is an important feature of today’s hearing aids (HA), which is why noise reduction is nowadays included in almost every commercially available device. The majority of these algorithms, however, is restricted to the reduction of stationary noises. In this work, we propose a denoising approach based on a three hidden layer fully connected deep learning network that aims to predict a Wiener filtering gain with an asymmetric input context, enabling real-time applications with high constraints on signal delay. The approach is employing a hearing instrument-grade filter bank and complies with typical hearing aid demands, such as low latency and on-line processing. It can further be well integrated with other algorithms in an existing HA signal processing chain. We can show on a database of real world noise signals that our algorithm is able to outperform a state of the art baseline approach, both using objective metrics and subject tests.
💡 Research Summary
This paper addresses the challenge of providing effective noise reduction for hearing aids (HAs) while meeting the stringent latency and computational constraints inherent to these devices. Traditional HA noise‑reduction algorithms are largely limited to stationary noises and often rely on directional microphones, which restrict the user’s freedom of head orientation and are unsuitable for deep‑insertion devices. To overcome these limitations, the authors propose a deep‑learning‑based approach that predicts Wiener‑filter gains directly from a short‑time spectral representation of the noisy signal, using a three‑hidden‑layer fully connected neural network (FC‑DNN).
The signal processing chain begins with a 48‑channel uniform polyphase analysis filter bank (AFB) specifically designed for HA applications. The noisy mixture, clean speech, and noise are each transformed into the time‑frequency domain, after which the log‑power spectrum is computed and normalized on a per‑frequency basis using only the data available within a short buffer. This normalization eliminates the need for global statistics, enabling true online processing.
A key innovation is the use of an asymmetric temporal context: the network receives up to 200 ms of past frames (τ₁) and only 2 ms of future frames (τ₂). This design respects the overall latency budget of 8 ms (≈6 ms consumed by the analysis/synthesis filter banks), while still providing sufficient contextual information for the DNN to learn speech dynamics. Experiments showed that performance gains saturate when τ₁ reaches 200–300 ms, aligning with the typical syllabic rate of speech (~4 Hz).
The DNN architecture consists of three hidden layers with 2048 ReLU‑activated neurons each, followed by a linear output layer that predicts a 48‑dimensional gain vector G_w for each frame. The predicted gains are applied multiplicatively to the noisy spectral bins, and the enhanced signal is reconstructed via the synthesis filter bank (SFB). This gain‑based approach integrates seamlessly with other HA processing blocks such as automatic gain control, and can be interpreted as a form of known‑operator learning.
Training data were collected in real‑world environments across Europe using HA‑grade microphones placed in a receiver‑in‑the‑canal (RIC) shell. A total of 49 non‑stationary noise recordings were mixed with 260 German sentences from the EUROM database, upsampled to 24 kHz. To increase variability, up to four noises were combined with random offsets, and SNRs ranging from –10 dB to 20 dB were uniformly sampled. The dataset was split at the utterance level to avoid speaker or noise overlap between training, validation, and test sets. The network was trained on an Nvidia Titan Xp GPU using TensorFlow and the Adam optimizer (initial learning rate 1e‑5) for ten epochs.
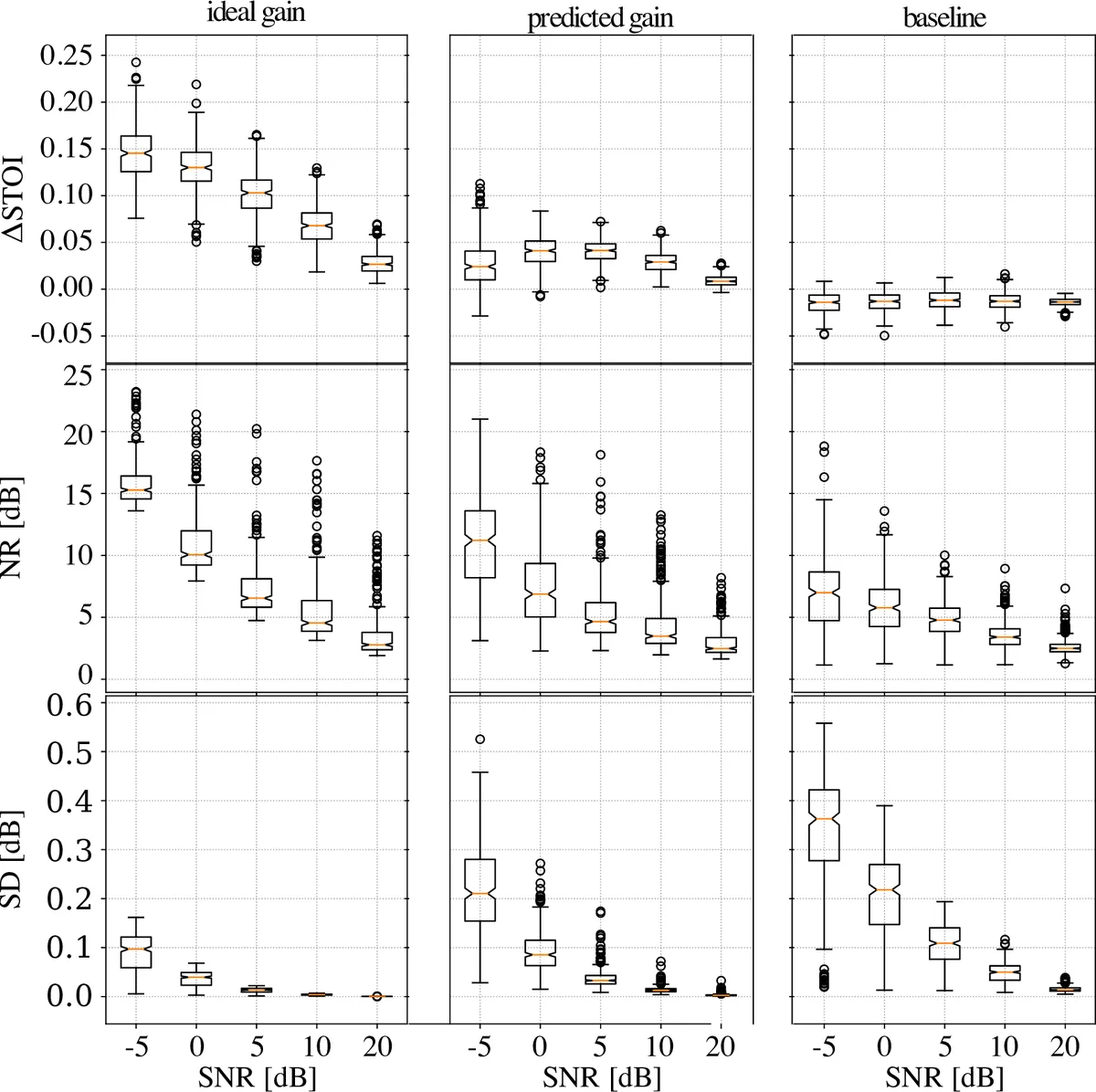
Performance was evaluated using both objective and subjective metrics. Objective measures included the short‑term objective intelligibility (STOI) index, noise‑reduction (NR) and speech‑distortion (SD) scores as defined by Chen et al. In low‑SNR conditions the DNN’s ΔSTOI was near zero, but for SNRs typical of real environments (0 dB and above) it achieved improvements of 0.05–0.15 STOI points over a state‑of‑the‑art recursive minimum‑tracking baseline. Moreover, the DNN attained roughly 2 dB greater NR while keeping SD below 0.5 dB, indicating a more favorable trade‑off between noise suppression and speech fidelity.
Subjective evaluation employed a MUSHRA (Multi‑Stimulus test with Hidden Reference and Anchor) protocol with 20 participants, all experienced audio engineers. For each of four SNR conditions (–5, 0, 5, 10 dB) four 12‑second excerpts were processed by the baseline, an ideal Wiener filter (reference), the DNN, and an anchor (poorly tuned minimum‑statistics estimator). Listeners rated perceived audio quality on a 0‑100 scale. The DNN consistently outperformed the baseline, achieving median scores between 70 and 85, and in the 5 dB and 10 dB conditions reached scores comparable to the ideal Wiener reference, demonstrating a “ceiling effect.”
The authors conclude that a relatively simple fully connected DNN, when combined with a carefully designed asymmetric temporal context and HA‑specific filter bank, can deliver real‑time noise reduction that surpasses existing commercial algorithms both objectively and subjectively. Limitations include the fixed 48‑channel filter bank and the lack of validation on low‑power embedded hardware, as well as the geographic concentration of noise recordings. Future work is suggested to explore lightweight convolutional or recurrent architectures, broader multilingual and environmental datasets, and full hardware implementation studies to confirm power and latency budgets in actual hearing‑aid devices.
Comments & Academic Discussion
Loading comments...
Leave a Comment