Explainable Reinforcement Learning Through a Causal Lens
Prevalent theories in cognitive science propose that humans understand and represent the knowledge of the world through causal relationships. In making sense of the world, we build causal models in our mind to encode cause-effect relations of events and use these to explain why new events happen. In this paper, we use causal models to derive causal explanations of behaviour of reinforcement learning agents. We present an approach that learns a structural causal model during reinforcement learning and encodes causal relationships between variables of interest. This model is then used to generate explanations of behaviour based on counterfactual analysis of the causal model. We report on a study with 120 participants who observe agents playing a real-time strategy game (Starcraft II) and then receive explanations of the agents’ behaviour. We investigated: 1) participants’ understanding gained by explanations through task prediction; 2) explanation satisfaction and 3) trust. Our results show that causal model explanations perform better on these measures compared to two other baseline explanation models.
💡 Research Summary
The paper “Explainable Reinforcement Learning Through a Causal Lens” proposes a novel framework that integrates structural causal models (SCMs) into model‑free reinforcement learning (RL) to generate human‑understandable explanations for an agent’s actions. Drawing on cognitive‑science evidence that people reason about the world using causal relationships, the authors extend the standard Markov Decision Process (MDP) formalism with an “action influence model.” In this model, each state variable is associated with a set of structural equations—one for each possible action—so that the causal effect of any action on any variable can be learned alongside the policy.
The learning phase simultaneously optimizes the policy (using standard RL algorithms) and fits the parameters of the causal equations from observed (state, action, next‑state) transitions. Experiments on six benchmark RL domains with six different algorithms (e.g., DQN, PPO, A2C) show that the causal model can be learned with negligible impact on the agent’s performance, confirming that accurate causal estimates are compatible with high‑quality policies.
Explanation generation proceeds in three stages. First, the causal graph is constructed, identifying for each action a “head node” (the immediate state variables directly affected) and “reward nodes” (sink nodes with no outgoing edges). Second, the learned structural equations are used to instantiate the graph for a particular state, yielding a complete causal chain from the chosen action through intermediate variables to eventual rewards. Third, explanations are extracted from this chain. The authors define three types of explanations:
- Complete Explanation – the full causal chain (action → all intermediate variables → reward).
- Minimally Complete Explanation – a concise version that includes only the head node and the immediate predecessors of the reward nodes, thereby reducing cognitive load while preserving the essential “cause‑and‑goal” information.
- Contrastive Explanation – for “Why‑not” questions, a counterfactual instantiation is simulated: the model forward‑propagates the structural equations under the hypothetical action to obtain the “optimal” predecessor values that would have led to that action. The minimally complete explanations for the actual action and the counterfactual action are then compared, and only the differing variables are presented. This follows the psychological “difference condition” for contrastive explanations.
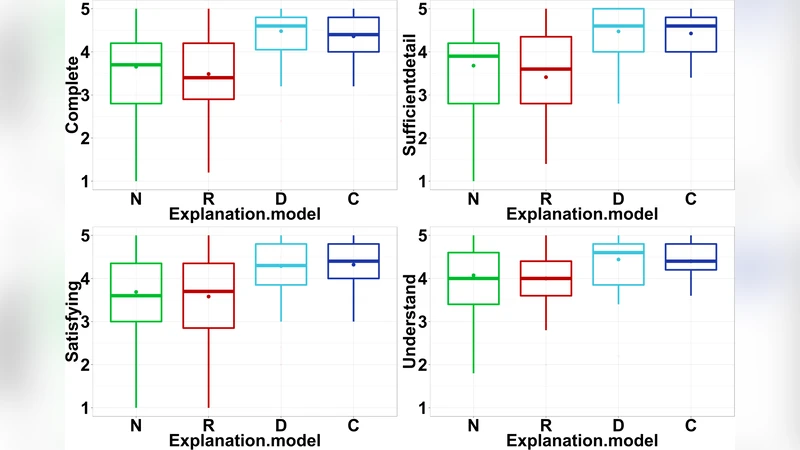
To evaluate the approach with real users, the authors built a simplified StarCraft II scenario with four possible actions (build supply depot, build barracks, train offensive unit, attack) and nine state variables (worker count, supply, barracks count, enemy location, ally unit count, health, location, destroyed units, destroyed buildings). They trained RL agents using the action‑influence model and then conducted a between‑subjects study with 120 participants who observed the agents playing the game. Each participant received explanations generated by one of three methods: the proposed causal model, a baseline that selects “relevant” variables from factored MDPs, and a baseline that uses template‑based minimal explanations.
Three outcome measures were collected: (1) Task prediction accuracy – participants’ ability to predict the agent’s next action after seeing an explanation; (2) Explanation satisfaction – Likert‑scale ratings of clarity, usefulness, and completeness; (3) Trust – participants’ reported trust in the agent. Results showed that explanations derived from the causal model significantly improved task prediction accuracy and satisfaction compared with both baselines. Trust scores were higher but not statistically different, suggesting that additional factors beyond explanation content influence trust formation.
The paper’s contributions are threefold: (i) a formal definition of the action influence model that embeds causal reasoning into RL without degrading performance; (ii) a systematic method for generating “why” and “why‑not” explanations that are both minimally complete and contrastive, grounded in causal graph traversal; (iii) an empirical user study demonstrating that these explanations enhance human understanding of complex RL agents in a realistic game environment.
Overall, this work bridges the gap between explainable AI (XAI) and reinforcement learning by providing a principled, cognitively aligned explanation mechanism. By leveraging causal and counterfactual reasoning, it offers explanations that match how people naturally think about cause and effect, making the behavior of otherwise opaque RL agents accessible to non‑expert users. The approach has promising implications for safety‑critical domains, human‑in‑the‑loop decision making, and any application where transparent RL policies are required.
Comments & Academic Discussion
Loading comments...
Leave a Comment