Impact of Fully Connected Layers on Performance of Convolutional Neural Networks for Image Classification
The Convolutional Neural Networks (CNNs), in domains like computer vision, mostly reduced the need for handcrafted features due to its ability to learn the problem-specific features from the raw input data. However, the selection of dataset-specific CNN architecture, which mostly performed by either experience or expertise is a time-consuming and error-prone process. To automate the process of learning a CNN architecture, this paper attempts at finding the relationship between Fully Connected (FC) layers with some of the characteristics of the datasets. The CNN architectures, and recently datasets also, are categorized as deep, shallow, wide, etc. This paper tries to formalize these terms along with answering the following questions. (i) What is the impact of deeper/shallow architectures on the performance of the CNN w.r.t. FC layers?, (ii) How the deeper/wider datasets influence the performance of CNN w.r.t. FC layers?, and (iii) Which kind of architecture (deeper/ shallower) is better suitable for which kind of (deeper/ wider) datasets. To address these findings, we have performed experiments with three CNN architectures having different depths. The experiments are conducted by varying the number of FC layers. We used four widely used datasets including CIFAR-10, CIFAR-100, Tiny ImageNet, and CRCHistoPhenotypes to justify our findings in the context of the image classification problem. The source code of this research is available at https://github.com/shabbeersh/Impact-of-FC-layers.
💡 Research Summary
This paper investigates how the number and size of fully‑connected (FC) layers affect the classification performance of convolutional neural networks (CNNs) across datasets with different characteristics. The authors pose three research questions: (i) how does the depth of a CNN (shallow vs. deep) interact with the number of FC layers in terms of accuracy; (ii) how do dataset properties—specifically “deep” datasets (many classes, high semantic complexity) versus “wide” datasets (high resolution, many diverse samples)—moderate this interaction; and (iii) which combination of network depth and FC‑layer configuration is optimal for a given dataset type.
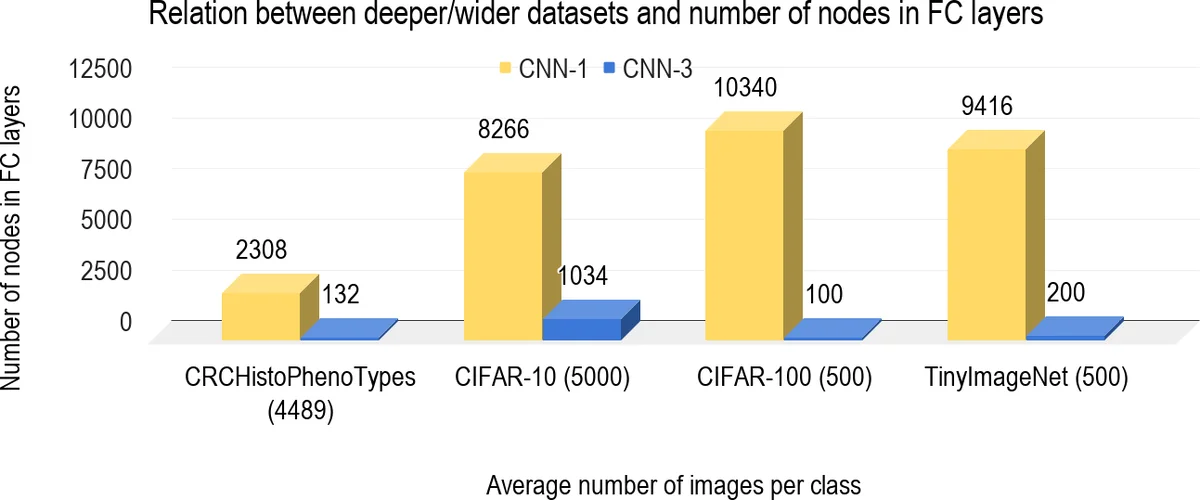
To answer these questions, three CNN architectures are built: CNN‑1 (a lightweight AlexNet‑style network with five convolutional layers and a single output FC layer), CNN‑2 (a VGG‑style network with ten convolutional layers and one output FC layer), and CNN‑3 (a CIFAR‑VGG‑style network with sixteen convolutional layers and one output FC layer). For each architecture, the authors systematically vary the number of additional FC layers from zero up to four, inserting a ReLU activation, batch normalization, and dropout after each added FC layer. The experiments are conducted on four widely used image‑classification datasets: CIFAR‑10 (10 classes, low complexity), CIFAR‑100 (100 classes, high semantic depth), Tiny ImageNet (200 classes, higher resolution, “wide”), and CRCHistoPhenotypes (medical histology images, four classes but complex texture).
Training follows a uniform protocol: stochastic gradient descent with momentum 0.9, an initial learning rate of 0.1 halved every 20 epochs, total of 250 epochs, and standard data augmentations (rotations, horizontal and vertical flips). Classification accuracy on a held‑out test set is the primary evaluation metric; the authors also report total trainable parameters to illustrate the contribution of FC layers.
Key findings:
-
Shallow networks (CNN‑1) benefit most from adding FC layers. Accuracy improves by 3–5 percentage points when 2–3 FC layers are added, especially on “wide” datasets like Tiny ImageNet where the convolutional backbone alone cannot capture the full spatial context. However, each added FC layer dramatically increases the parameter count (often exceeding 80 % of total parameters) and can lead to over‑fitting if dropout or regularization is insufficient.
-
Medium‑depth networks (CNN‑2) show diminishing returns. One extra FC layer yields modest gains on CIFAR‑100 and Tiny ImageNet, but adding more than two FC layers offers no benefit and can degrade performance due to excessive model capacity and training instability.
-
Deep networks (CNN‑3) achieve high accuracy with the minimal FC configuration (only the final output layer). Adding any extra FC layers either does not improve or slightly harms performance while inflating memory and compute requirements. This suggests that a sufficiently deep convolutional stack already learns rich, discriminative representations, making additional dense layers redundant.
Dataset‑specific trends emerge:
- CIFAR‑10 (few classes, low complexity) favors shallow CNN‑1 with 2–3 FC layers.
- CIFAR‑100 (many classes, high semantic depth) is best served by the medium‑depth CNN‑2 with a single FC layer; the deep CNN‑3 performs comparably without extra FC layers.
- Tiny ImageNet (high resolution, many classes) benefits most from shallow CNN‑1 equipped with three FC layers, confirming that FC layers can compensate for limited convolutional depth when spatial resolution is high.
- CRCHistoPhenotypes (medical images with subtle texture) achieves optimal results with CNN‑2 plus one FC layer, indicating that moderate convolutional depth combined with a modest dense component balances feature extraction and classification power for complex but low‑class‑count data.
The authors interpret these results through the lens of “dataset depth vs. network depth” synergy. When a dataset is “deep” (many classes, high intra‑class variability), deep convolutional stacks are more effective, and dense layers should be kept minimal to avoid over‑parameterization. Conversely, for “wide” datasets (large image size, diverse visual patterns but fewer classes), shallow convolutional backbones need extra FC layers to perform the final high‑dimensional mapping.
A practical implication is highlighted for resource‑constrained environments: because FC layers dominate the parameter budget (up to 90 % in AlexNet‑style models), designing deep convolutional backbones with few or no FC layers yields lightweight models suitable for mobile or embedded deployment without sacrificing accuracy on “deep” datasets.
The paper concludes by releasing all code on GitHub for reproducibility and suggests future work to replace dense layers with parameter‑efficient alternatives such as global average pooling, 1×1 convolutions, or attention mechanisms, aiming to retain performance while further reducing model size.
Comments & Academic Discussion
Loading comments...
Leave a Comment