Rebuttal to Berger et al., TOPLAS 2019
Berger et al., published in TOPLAS 2019, is a critique of our 2014 FSE conference abstract and its archival version, the 2017 CACM paper: A Large-Scale Study of Programming Languages and Code Quality in Github. In their paper Berger et al. make academic claims about the veracity of our work. Here, we respond to their technical and scientific critiques aimed at our work, attempting to stick with scientific discourse. We find that Berger et al. largely replicated our results, and agree with us in their conclusion: that the effects (in a statistical sense) found in the data are small, and should be taken with caution, and that it is possible that an absence of effect is the correct interpretation. Thus, our CACM paper’s conclusions still hold, even more so now that they have been reproduced, and our paper is eminently citable.
💡 Research Summary
The paper is a point‑by‑point rebuttal to the 2019 TOPLAS article “On the Impact of Programming Languages on Code Quality: A Reproduction Study,” which criticized the authors’ earlier work on programming languages and bug proneness. The authors clarify that their 2017 CACM journal article supersedes the 2014 FSE conference version and that the journal version already incorporated many improvements, including corrected TypeScript identification and additional control variables.
The rebuttal first emphasizes that the original study did control for project size, number of commits, age, and number of developers by including log‑transformed variables in the regression models (Table 6 of CACM). Therefore, the claim that size differences were ignored is factually incorrect.
Next, the authors address the accusation of “uncontrolled effects.” They argue that while no empirical study can control every possible factor, they deliberately controlled for the most influential covariates known in software‑engineering research, following standard practice in fields such as public health and economics.
Regarding duplicated commits (<2 % of the data), the authors note that such a small proportion cannot materially bias the results, especially since no evidence is presented that duplicated commits are systematically more or less buggy.
The missing‑data criticism (up to 80 % for Perl) is explained as a consequence of using only primary file extensions from GitHub Linguist. For Perl many projects use the secondary “.pm” extension, which was excluded to avoid type‑I errors. Consequently, only Perl shows a large apparent loss; all other languages have missing‑data rates below 15 %. The authors argue this does not threaten the validity of the findings.
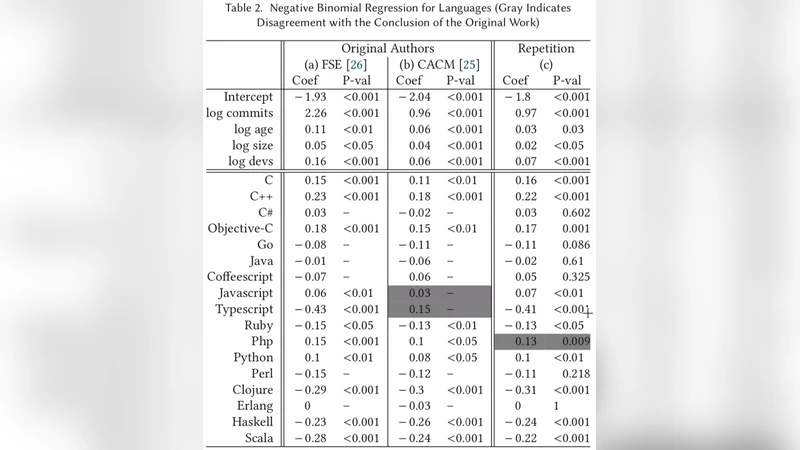
On language‑identification errors, the authors admit a TypeScript mis‑classification in the original FSE paper, but they corrected it promptly and used the corrected data in the CACM version. TOPLAS, however, compared its results to the outdated FSE version, which the authors view as a selective citation. The V8 JavaScript case is defended by noting that test‑file modifications are a legitimate part of maintenance work; only about 22 % of V8 JavaScript commits are pure test additions, and many real bugs are fixed by adding lines only.
Statistical methodology is a central point of contention. The authors state that CACM applied a False Discovery Rate (FDR) correction, which balances Type‑I and Type‑II errors appropriately for a study with many hypotheses. TOPLAS instead applied a Bonferroni correction, which is overly conservative and would render almost all effects non‑significant. Moreover, TOPLAS compared regression coefficients across models that have different predictor sets (e.g., splitting a “static/strong” category into two separate variables). Such cross‑model coefficient comparison is statistically unsound and can lead to ecological fallacy or Simpson’s paradox.
The authors also highlight that TOPLAS’s “repetition” section actually performed a “reanalysis” for RQ1 only, using newly gathered data and a different language classification. For RQ2–RQ4, TOPLAS’s results align with the original findings: functional languages show a slight (statistically significant) reduction in bug proneness, and domain does not correlate with defect rates. Hence, the claim that the original study is “beyond repair” is contradicted by the fact that TOPLAS independently reproduced the same qualitative conclusions.
In summary, the rebuttal argues that: (1) the original study’s methodology was sound and already accounted for major confounders; (2) data issues raised by TOPLAS are either negligible or stem from methodological choices that were deliberately conservative; (3) statistical criticisms are based on an inappropriate use of Bonferroni correction and on comparing incomparable regression models; (4) TOPLAS’s replication actually confirms the original results, despite its narrative suggesting otherwise. Consequently, the authors maintain that the conclusions of the CACM 2017 paper—programming language effects on bug proneness are small, statistically modest, and should be interpreted with caution—remain valid and the paper is fully citable.
Comments & Academic Discussion
Loading comments...
Leave a Comment