ASCAI: Adaptive Sampling for acquiring Compact AI
This paper introduces ASCAI, a novel adaptive sampling methodology that can learn how to effectively compress Deep Neural Networks (DNNs) for accelerated inference on resource-constrained platforms. Modern DNN compression techniques comprise various …
Authors: Mojan Javaheripi, Mohammad Samragh, Tara Javidi
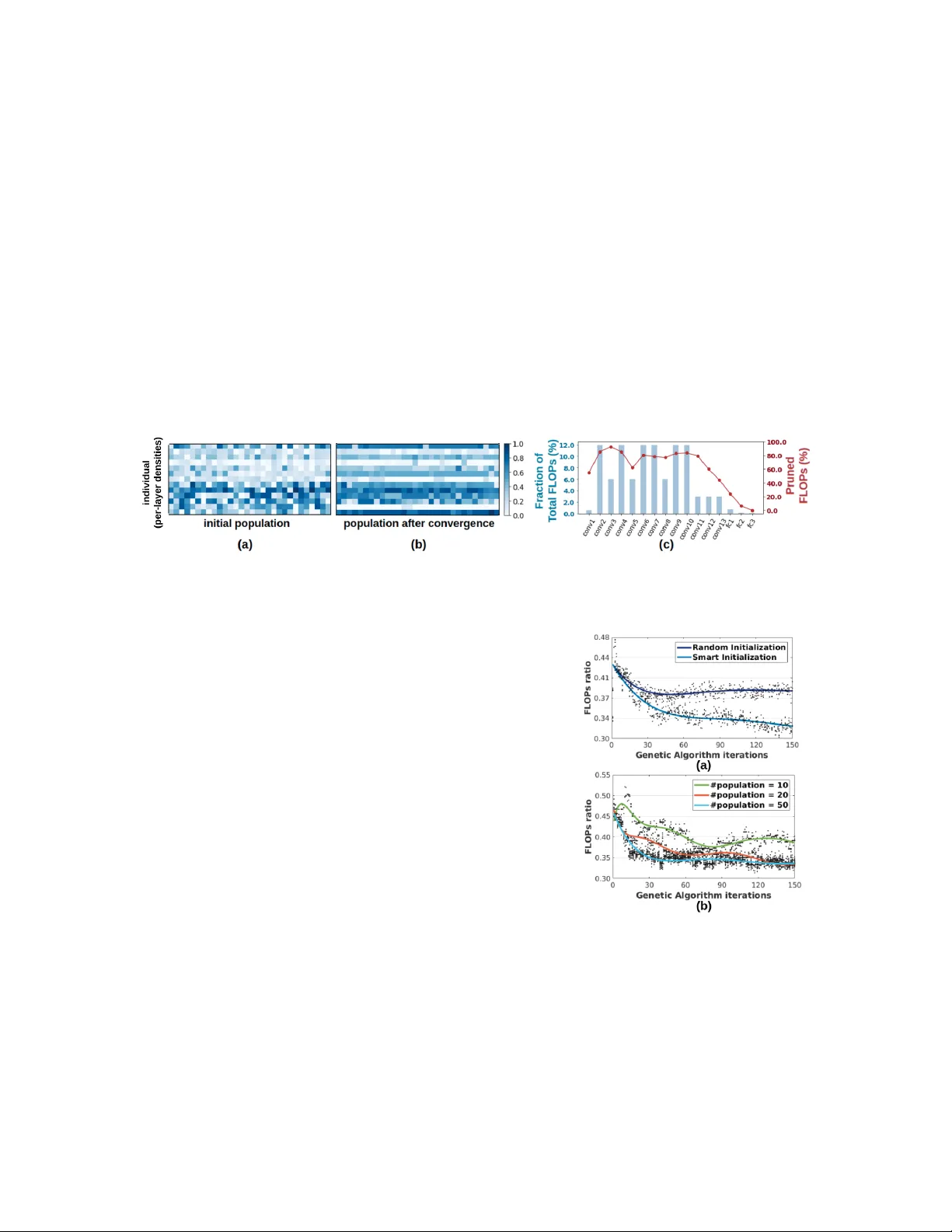
Appeared in ICML 2019, 6 th W orkshop on Automated Machine Learning ASCAI: Adaptiv e Sampling f or acquiring Compact AI Mojan Ja v aheripi and Mohammad Samragh and T ara J a vidi and F arinaz K oushanfar Department of Electrical and Computer Engineering, UC San Die go, USA { mojan, msamragh, tjavidi, farinaz } @ucsd.edu Abstract This paper introduces ASCAI, a no vel adapti ve sampling methodology that can learn ho w to ef fec- tiv ely compress Deep Neural Networks (DNNs) for accelerated inference on resource-constrained platforms. Modern DNN compression techniques comprise various hyperparameters that require per-layer customization to ensure high accurac y . Choosing such hyperparameters is cumbersome as the pertinent search space grows exponentially with the number of model layers. T o effecti v ely trav erse this large space, we de vise an intelligent sampling mechanism that adapts the sampling strategy using customized operations inspired by genetic algorithms. As a special case, we con- sider the space of model compression as a vector space. The adapti vely selected samples enable ASCAI to automatically learn how to tune per -layer compression hyperparameters to optimize the accuracy/model-size trade-of f. Our e xtensi ve e v aluations sho w that ASCAI outperforms rule-based and reinforcement learning methods in terms of compression rate and/or accuracy . 1. Introduction W ith the growing range of applications for Deep Neural Networks (DNNs) on embed- ded platforms, v arious DNN compression techniques hav e been de v eloped to enable ex- ecution of such models on resource-limited de vices. Some examples of DNN com- pression methods include pruning [Lin et al. (2018)], quantization [Zhou et al. (2016b); Ghasemzadeh et al. (2018)], nonlinear encoding [Han et al. (2015); Samragh et al. (2019b, 2017)], and tensor decomposition [Kim et al. (2015); Samragh et al. (2019a)]. Figure 1: Accurac y/FLOPs P areto fron- tiers for pruning a pre-trained VGG net- work on CIF AR-10. Our intelligent pol- icy achieves a better Pareto curv e com- pared to rule-based (uniform) pruning. Compression techniques require tailoring for each DNN architecture, which is generally realized by tuning certain hyperparameters at each layer . Fig. 1 illustrates the im- portance of intelligent hyperparameter selection for the example of pruning. In general, finding optimal hyper- parameters is quite challenging as the space of possibili- ties gro ws e xponentially with the number of DNN layers. Such large search-space renders manual or computerized greedy hyperparameter tuning algorithms sub-optimal or infeasible. Heuristics that compress one layer at a time ov erlook the existing inter-dependencies among layers. As such, an intelligent policy that globally tunes the per- tinent hyperparameters for all layers is highly desired. In this paper , we propose ASCAI, an adapti ve sampling methodology that automates hyperpa- rameter selection for DNN compression. Genetic algorithms are lev eraged to iterativ ely adapt the sampling strategy . W e devise a customized translator that encodes each compressed DNN as a fixed-length sample (vector) of the space, called an individual . W e then adapti vely sample from the pertinent v ector space with the goal of finding individuals that render higher compression rate and inference accuracy . Our algorithm initializes a random population of individuals and iterativ ely evolve s them to wards higher quality generations. T o assess the quality of individuals, we dev elop a scoring mechanism that captures the trade-off between model accuracy and computational complex- ity . ASCAI e v olution aims to encourage survi v al of indi viduals with high scores and elimination of the weak ones. T ow ards this goal, each ev olution iteration is modeled by a set of consecutive genetic operations. First, individuals with high scores are selected to generate a ne w population ( e valuation and selection ). Ne xt, the chosen individuals are combined and perturbed to produce children of similar quality ( cr osso ver and mutation ). The same procedure continues until con v ergence. 1 2. Background and Related W ork Preliminaries and K ey Insights. Recent research showcase the superiority of genetic algorithms to other exploration methods (e.g., reinforcement learning and random search) for large search- spaces [Xie and Y uille (2017)] due to their intriguing characteristics: (1) Genetic algorithms are inexpensi v e to implement as they do not rely on backpropagation. (2) They are highly parallelizable. (3) Genetic algorithms support a variety of scores and do not suf fer in settings with sparse/discrete re wards [Such et al. (2017)]. (4) Finally , these methods can adopt multiple DNN compression tasks. ... Sel ec t i o n + , Paren t 1, 2 Off s p ri n g Cr o s s -o v er Mu t at i o n T w eak ... Ev al u at i o n Sco r e: 0.01 0.2 0.55 Figure 2: Operations of genetic algorithms. A genetic algorithm works on a generation of in- dividual s. The core idea is to encourage creation of superior individuals and elimination of the infe- rior ones. T o this end, an iterativ e process (Fig. 2) e volv es the previous generation into a new , more competent population by performing a set of bio- inspired actions, i.e., selection , cr ossover , and muta- tion . During e valuation, individuals are assigned scores representing their quality ( fitness ). The se- lection step performs a sampling (with replacement) based on individuals’ fitness scores. Crossover and mutation create ne w indi viduals from existing ones. Related W ork. In the context of deep learning, genetic algorithms have been applied to Neural Architecture Search (N AS) [Xie and Y uille (2017); Real et al. (2017); Huang and W ang (2018)], where the goal is to build a neural network architecture. The objectiv e of N AS is generally achieving higher inference accurac y with no or little emphasis on the e xecution cost. Dif ferent from NAS, this paper focuses on learning hyperparameters for DNN customization, which simultaneously targets ex ecution cost and inference accuracy . Network compression has been studied in contemporary research [He et al. (2018a, 2017); W ang et al. (2017); Jiang et al. (2018); Li et al. (2016); Lin et al. (2017, 2018); Luo et al. (2017)]. These algorithms aim at eliminating redundancies from pre-trained network architectures to reduce computational complexity while preserving inference accuracy . Reinforcement Learning (RL) is proposed as an automated tool that searches for improved model compression quality [He et al. (2018b)]. Although ef fectiv e in finding near-optimal solutions, RL relies on gradient-based training, which can lead to a high computational burden and a slow con vergence. [Hu et al. (2018)] de velop a nov el pruning scheme that selects the pruned filters using genetic algorithms rather than magnitude-based or gradient-based approaches. Our work is dif ferent in that we aim to learn compression hyperparameters rather than the compression technique itself. As a result, ASCAI can be applied to generalized compression techniques. 3. ASCAI A pproach An overvie w of ASCAI methodology is shown in Fig. 3. A translation scheme represents each customized DNN using a v ector of per-layer hyperparameters (Sec. 3.1). The initial population is established using a random sampling scheme (Sec. 3.2). At each iteration, the ev aluation, selection, crossov er, and mutation operations (Sec. 3.3) are performed to update the population tow ards a ne w generation. By iterativ ely applying these operations, ASCAI finds near -optimal compression hyperparameters for a desired DNN. The rest of this section provides details on the search algorithm. V al id at i o n A cc u r ac y ... Po pu l at i o n Cr os s -o v er Mu tat e Sel ect Ev alu at e D e c o d e Mo del Si ze Nex t Gen er at i o n Com p r es sed DNN Gen et i c A l g o r i t h m Figure 3: ASCAI solution for DNN customization. 2 3.1 Genetic T ranslation Although our proposed approach is applicable to various DNN compression techniques, in this paper we direct our focus on four compression tasks: structured and non-structured Pruning [Li et al. (2016); He et al. (2017)], Singular V alue Decomposition [Zhou et al. (2016a)], and T ucker -2 approximation [Kim et al. (2015)]. T o construct the indi vidual vectors for our genetic algorithm, we append per-layer h yperparameters as described in the follo wing. Pruning. W e allocate a continuous value p ∈ [0 , 1] for each layer to represent the ratio of pruned v alues. For an L -layer DNN, each individual w ould be a vector v ∈ R L with elements v i ∈ [0 , 1] . SVD. W e apply SVD on weight parameters ( W ) of fully-connected layers ( W ∈ R m × n ) and point- wise con volutions ( W ∈ R m × n × 1 × 1 ). T o represent the approximation rank in each layer , we dis- cretize the possibilities into 64 v alues and encode them as follo ws: r ank ∈ { 1 ← R 64 , 2 ← 2 R 64 , . . . , 64 ← R } , R = min { m, n } T ucker -2. T ucker decomposition is a generalized form of low-rank approximation for arbitrary- shaped tensors. W e apply this method to 4-way weights in conv olutional layers, W ∈ R m × n × k × k . W e focus on T ucker -2 which only decomposes the tensor along m and n directions, i.e., output and input channels. For each layer , a tuple of approximation ranks ( rank m , r ank n ) should be pro vided. W e quantize the space of decomposition ranks to 8 bins per-w ay as follows: r ank m ∈{ 1 ← m 8 , 2 ← 2 m 8 , . . . , 8 ← m } , r ank n ∈ { 1 ← n 8 , 2 ← 2 n 8 , . . . , 8 ← n } When applying low-rank approximation, for a DNN that has a total of L 1 fully connected and point- wise con volutions ( 1 × 1 filters) and L 2 regular con volution layers ( k × k filters), the individual would be a vector of length L 1 + 2 L 2 that represent the encoded ranks described abov e. 3.2 W arm Initialization A na ¨ ıve initialization of indi viduals can result in a slow and sub-optimal con vergence. T o address this, we utilize warm population initialization to reduce search time by eliminating unnecessary ex- ploration of low-score regions, i.e., re gions at which the inference accuracy is low . Let us denote an indi vidual vector as v ∈ R L , the validation dataset as D = { ( x m , y m ) } M m =1 , and the corresponding classification accuracy as acc D | v . During initialization, we only accept randomly sampled ( i.i.d. ) indi viduals that satisfy an accurac y threshold: acc D | v > acc thr . T o this end, we find a threshold vector θ that specifies the maximum per-layer compression when all other layers are uncompressed. Belo w we explain ho w to obtain θ for continuous and discrete hyperparameters. Pruning. W e obtain a threshold vector θ ∈ R L with the i -th element θ i specifying the maximum pruning rate for the i -th layer such that the accuracy threshold acc thr is not violated: θ i = max { p } s.t. v j = ( p j = i 0 j 6 = i & acc D | v > acc thr (1) For each indi vidual v , the i -th element v i is sampled from a Normal distribution N ( θ i / 2 , θ i / 2) . Decomposition. The threshold vector θ represents per -layer minimum ranks that satisfy acc thr : θ i = min { r ank } s.t. v j = ( r ank j = i r ank max j 6 = i & acc D | v > acc thr (2) where r ank max corresponds to the non-decomposed layer parameters (see Sec. 3.1). Once θ is obtained, we uniformly sample v i from integers { θ i , θ i + 1 , . . . } . 3 3.3 Genetic Operations T o enable ef ficient exploration of the underlying search-space, we devise customized genetic oper - ations, namely , ev aluation, selection, crossover , and mutation. Below we describe each step. Evaluation. T o assess a population of individuals, we first decode them to their corresponding compressed DNN architectures; this is done by applying compression to each layer of the original DNN based on the corresponding hyperparameter in the indi vidual. W e de velop a customized scor - ing mechanism that reflects the acquired model’ s accuracy and compression rate. Giv en v alidation dataset, D = { ( x m , y m ) } M m =1 , the score of indi vidual v e v aluated on dataset D is: scor e ( v , D ) = ∆ FLOPS ( v ) PEN acc ( D | v ) (3) The numerator encourages reduction in model FLOPs while the denominator penalizes the decrease in model accurac y caused by compression. Here, ∆ FLOPS ( v ) represents the dif ference in FLOPS between the uncompressed DNN and the compressed model after applying v . PEN acc ( D | v ) is a measure for accuracy de gradation: PEN acc ( D | v ) = acc D | o − acc D | v + T ( acc D | v < acc thr ) × e acc thr − acc D | v (4) where acc D | o is the v alidation accuracy of the original (uncompressed) model, acc D | v is the accu- racy after applying compression with v , and T ( . ) returns the Boolean assessment of the provided inequality . T o pre vent undesirable drop of accuracy , we greatly diminish the score of indi viduals that cause lower accuracies than the set constraint, acc thr ; Having an accuracy constraint is crucial since the genetic algorithm will con ver ge to a model size of zero otherwise. T o ensure ef ficiency , we only use a small portion of the training samples as v alidation data. Selection. The selection stage in genetic algorithms attempts to choose high-quality individuals to generate the next population. Let us denote the population at the beginning of t -th iteration by P t = { v t n } N n =1 with fitness scores { s n } N n =1 obtained from Eq. 3. Following [Xie and Y uille (2017)], we normalize the scores as s n ← s n − s min P N n =1 ( s n − s min ) , where s min is the minimum score in current population. Subtraction of the minimum score ensures that the probability of selecting the weakest indi vidual is zero. The new population, P t +1 = { v t +1 n } N n =1 , is generated by non-uniform random sampling (with replacement) from the old population, P t . In this non-uniform sampling, the probability of selecting an indi vidual, v t n , is proportional to its score. This method eliminates weak indi viduals and passes the high-quality ones to the next generation. Crosso ver . Gi ven a selected population P t +1 , crossover generates two offsprings by operating on each pair of adjacent parent indi viduals { v t +1 2 k − 1 , v t +1 2 k } N 2 k =1 . W e use two parameters to control the degree of crossover operation: p cross determines the probability of applying crossover between two individuals, and p swap is the per-element swapping probability . Crossover allo ws superior indi viduals to e xchange their learned patterns and enables kno wledge transfer across the population. Mutation. Mutation randomly tweaks each individual in the population. Similar to crossover , we define two control parameters: p mutate is the probability that the indi vidual gets mutated and p tweak determines the per-element tweaking probability . Mutation allo ws exploration of the neighborhood of candidate points in the search-space. Each element of a continuous-valued indi vidual is mutated by adding a random value drawn from a zero-mean Normal distribution N (0 , 0 . 2) . Discrete-v alued indi viduals are mutated by randomly incrementing or decrementing v ector elements. The v alues are clipped to the v alid ranges after mutation. 4 4. Experiments W e provide extensi ve e valuations on CIF AR-10 and ImageNet benchmarks. The baseline netw orks are trained from scratch using PyT orch library . W e conduct experiments with non-structured prun- ing ( P n ), structured pruning ( P s ), decomposition ( D ), and combination of multiple compression methods ( D + P s ). T ab . 1 summarizes the results of ASCAI compressed networks and compares them with prior work that utilize pruning as the compression technique. For brevity , we compare ASCAI with best existing w orks and exclude other related w orks. T able 1: Comparison of ASCAI with state-of-the-art compression methods, namely CP [He et al. (2017)], AMC [He et al. (2018b)], SFP [He et al. (2018a)], FP [Li et al. (2016)], SSS [W ang et al. (2017)], GDP [Lin et al. (2018)], ThiNet [Luo et al. (2017)], and RNP [Lin et al. (2017)]. For ImageNet, we follo w common practice in prior work and compare our top-5 accurac y with them. Non-structured Pruning ( P n in T ab. 1). W e perform non-structured pruning on ResNet-50 trained on CIF AR-10. W e prune the parameters with lo west absolute v alue as in AMC [Han et al. (2015)], the state-of-the-art that utilizes RL for automated DNN compression. Similar to AMC, we do not perform fine-tuning on the compressed model in this e xperiment. As shown, ASCAI achie ves better accuracy with 1 . 33 × lower parameters. Structured Pruning ( P s in T ab. 1). W e implement structured pruning by adding masks after R eLU acti v ation layers. Follo wing [Molchanov et al. (2016)], we prune the acti vations in each layer based on the sum of absolute gradients at the ReLU output. W e base our comparisons on the number of operations per inference, i.e., FLOPs, compared to the uncompressed baseline. On CIF AR-10 networks, ASCAI achiev es on a verage 1 . 25 × lower FLOPs, while achieving similar classification accuracy compared to prior art. On VGG-16, ASCAI outperforms all heuristic methods and gi ves competing results with AMC [He et al. (2018b)]. Decomposition and Pruning ( D + P s in T ab . 1). T o un veil the full potential of our method, we allo w ASCAI to learn and combine multiple compression techniques, namely , structures pruning, SVD, and T ucker decomposition. W e also report the FLOPs reduction achiev ed by decomposition separately (sho wn by D in T ab. 1). Combining multiple techniques allo ws ASCAI to push the limits of compression. On V GG-16, ASCAI pushes the state-of-the-art FLOPs reduction from 5 × to 7 . 2 × with 0 . 3% higher accuracy . 5 4.1 Analysis and Discussion T o illustrate ASCAI methodology , we consider VGG architecture trained on ImageNet and com- pressed with structured (filter) pruning. The population is visualized at the initial step (Fig. 4-a) and after 50 iterations of genetic updating (Fig 4-b). Upon con ver gence, individuals strongly resem- ble one another and ha ve similarly high scores. ASCAI successfully learns expert-designed rules: first and last rows in Fig. 4-b (first conv olution and last fully-connected) are gi ven high densities to maintain inference accurac y . ASCAI performs whole-network compression by capturing the state of all layers in each genetic individual. As such, our algorithm can learn which configuration of hyperparameters least affects model accuracy and most reduces the ov erall FLOPs. T o show this capability , we present the per-layer FLOPs for V GG-16 network trained on ImageNet in Fig. 4-c. The bar for each layer sho ws the percentage of total FLOPs in the original model; the curve sho ws the percentage of pruned FLOPs in the compressed network. Different from prior art [Jiang et al. (2018)], ASCAI prunes the first con volutions more and relaxes pruning for late con volution and fully-connected layers as they ha ve a minor role in FLOPs. Figure 4: (a) Initialized population for structured pruning. (b) Population upon con vergence. Here, each row corresponds to a DNN layer and each column denotes an individual in the population. (c) Per-layer FLOPs (bar charts) and percentage of pruned FLOPs (curv e). 4.2 Ablation Study Figure 5: (a) Effect of initializa- tion. (b) Effect of population size. In this section, we study the ef fect of ASCAI components on algorithm con ver gence and final FLOPs/accurac y . F or bre vity , we only focus on structured pruning for CIF AR-10. W e show the trend lines as well as a fraction of individuals (black dots) across ASCAI iterations. Effect of Initialization. Fig. 5-a sho ws the ev olution of FLOPs ratio for two initialization policies, one with uni- formly random samples and one with our proposed initializa- tion scheme discussed in Sec. 3.2. As seen, naive initialization greatly harms the con vergence rate and final FLOPs. Effect of Population Size. Fig. 5-b presents the ef fect of pop- ulation size on ASCAI con ver gence. A higher number of in- di viduals results in a smoother conv ergence and lower final FLOPs. This effect saturates for a large enough population. 5. Conclusion This paper introduces ASCAI, a method to automate DNN compression using adapti ve sampling with genetic algorithms. Our algorithm learns ho w the compression hyperparameters should be set across layers to achiev e a better performance than models designed by human experts. The core idea behind ASCAI is to translate compression hyperparameters into a v ector of genes and explore the corresponding search-space using genetic operations. This approach allows ASCAI to be generic and applicable to any combination of post-processing DNN compression methods. 6 References Mohammad Ghasemzadeh, Mohammad Samragh, and Farinaz K oushanfar . Rebnet: Residual binarized neural network. In 2018 IEEE 26th Annual International Symposium on F ield- Pr ogrammable Custom Computing Mac hines (FCCM) , pages 57–64. IEEE, 2018. Song Han, Huizi Mao, and W illiam J Dally . Deep compression: Compressing deep neural netw orks with pruning, trained quantization and huf fman coding. arXiv pr eprint arXiv:1510.00149 , 2015. Y ang He, Guoliang Kang, Xuanyi Dong, Y anwei Fu, and Y i Y ang. Soft filter pruning for accelerat- ing deep con volutional neural networks. arXiv pr eprint arXiv:1808.06866 , 2018a. Y ihui He, Xiangyu Zhang, and Jian Sun. Channel pruning for accelerating very deep neural net- works. In International Conference on Computer V ision (ICCV) , volume 2, 2017. Y ihui He, Ji Lin, Zhijian Liu, Hanrui W ang, Li-Jia Li, and Song Han. Amc: Automl for model compression and acceleration on mobile de vices. In Pr oceedings of the Eur opean Conference on Computer V ision (ECCV) , pages 784–800, 2018b. Y iming Hu, Siyang Sun, Jianquan Li, Xingang W ang, and Qingyi Gu. A novel channel pruning method for deep neural network compression. arXiv preprint , 2018. Zehao Huang and Naiyan W ang. Data-driv en sparse structure selection for deep neural networks. In Pr oceedings of the Eur opean Confer ence on Computer V ision (ECCV) , pages 304–320, 2018. Chunhui Jiang, Guiying Li, Chao Qian, and K e T ang. Efficient dnn neuron pruning by minimizing layer-wise nonlinear reconstruction error . In IJCAI , pages 2–2, 2018. Y ong-Deok Kim, Eunhyeok Park, Sungjoo Y oo, T aelim Choi, Lu Y ang, and Dongjun Shin. Com- pression of deep con volutional neural networks for fast and low po wer mobile applications. arXiv pr eprint arXiv:1511.06530 , 2015. Hao Li, Asim Kadav , Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for ef ficient con vnets. arXiv preprint , 2016. Ji Lin, Y ongming Rao, Jiwen Lu, and Jie Zhou. Runtime neural pruning. In Advances in Neural Information Pr ocessing Systems , pages 2181–2191, 2017. Shaohui Lin, Rongrong Ji, Y uchao Li, Y ongjian W u, Feiyue Huang, and Baochang Zhang. Accel- erating con volutional netw orks via global & dynamic filter pruning. In IJCAI , pages 2425–2432, 2018. Jian-Hao Luo, Jianxin W u, and W eiyao Lin. Thinet: A filter le vel pruning method for deep neural network compression. In Pr oceedings of the IEEE international confer ence on computer vision , pages 5058–5066, 2017. Pa vlo Molchanov , Stephen T yree, T ero Karras, T imo Aila, and Jan Kautz. Pruning con volutional neural networks for resource ef ficient transfer learning. arXiv pr eprint arXiv:1611.06440 , 3, 2016. Esteban Real, Sherry Moore, Andrew Selle, Saurabh Saxena, Y utaka Leon Suematsu, Jie T an, Quoc V Le, and Alex ey Kurakin. Large-scale ev olution of image classifiers. In Pr oceedings of the 34th International Confer ence on Machine Learning-V olume 70 , pages 2902–2911. JMLR. org, 2017. 7 Mohammad Samragh, Mohammad Ghasemzadeh, and Farinaz K oushanfar . Customizing neural net- works for ef ficient fpga implementation. In F ield-Pr ogrammable Custom Computing Machines (FCCM), 2017 IEEE 25th Annual International Symposium on , pages 85–92. IEEE, 2017. Mohammad Samragh, Mojan Jav aheripi, and Farinaz K oushanfar . Autorank: Automated rank se- lection for ef fecti ve neural netw ork customization. ML-for-Systems workshop at the 46th Inter - national Symposium on Computer Ar chitectur e (ISCA) , 2019a. Mohammad Samragh, Mojan Jav aheripi, and F arinaz K oushanfar . Codex: Bit-flexible encoding for streaming-based fpga acceleration of dnns. arXiv pr eprint arXiv:1901.05582 , 2019b. Felipe Petroski Such, V ashisht Madhav an, Edoardo Conti, Joel Lehman, K enneth O Stanley , and Jef f Clune. Deep neuroe volution: Genetic algorithms are a competitiv e alternati ve for training deep neural networks for reinforcement learning. arXiv preprint , 2017. Huan W ang, Qiming Zhang, Y uehai W ang, and Haoji Hu. Structured probabilistic pruning for con volutional neural network acceleration. arXiv pr eprint arXiv:1709.06994 , 2017. Lingxi Xie and Alan Y uille. Genetic cnn. arXiv preprint , 2017. Hao Zhou, Jose M Alvarez, and F atih Porikli. Less is more: T ow ards compact cnns. In Eur opean Confer ence on Computer V ision , pages 662–677. Springer, 2016a. Shuchang Zhou, Y uxin W u, Zekun Ni, Xinyu Zhou, He W en, and Y uheng Zou. Dorefa-net: T rain- ing lo w bitwidth con volutional neural networks with low bitwidth gradients. arXiv pr eprint arXiv:1606.06160 , 2016b. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment