The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
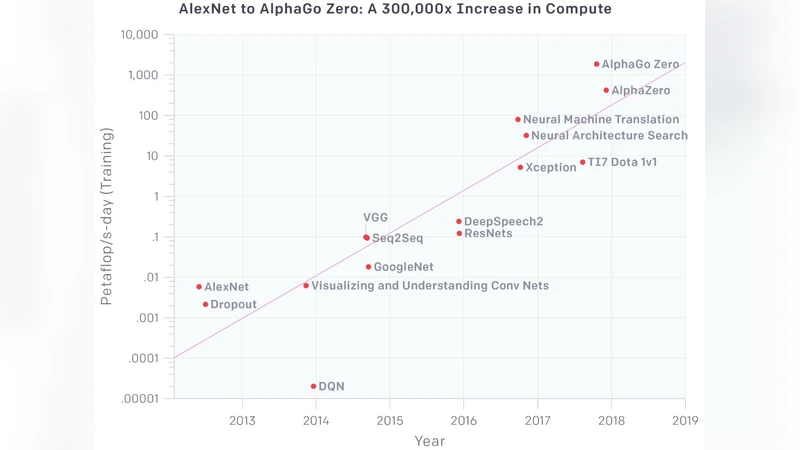
The past decade has seen a remarkable series of advances in machine learning, and in particular deep learning approaches based on artificial neural networks, to improve our abilities to build more accurate systems across a broad range of areas, including computer vision, speech recognition, language translation, and natural language understanding tasks. This paper is a companion paper to a keynote talk at the 2020 International Solid-State Circuits Conference (ISSCC) discussing some of the advances in machine learning, and their implications on the kinds of computational devices we need to build, especially in the post-Moore’s Law-era. It also discusses some of the ways that machine learning may also be able to help with some aspects of the circuit design process. Finally, it provides a sketch of at least one interesting direction towards much larger-scale multi-task models that are sparsely activated and employ much more dynamic, example- and task-based routing than the machine learning models of today.
💡 Research Summary
The paper, written as a companion to a 2020 ISSCC keynote, surveys the dramatic advances in deep learning over the past decade and examines how these advances reshape computer architecture and chip design, especially as we move beyond the era of Moore’s Law. It begins by documenting the unprecedented growth in model size and capability—vision systems now rival human accuracy, speech recognizers achieve near‑human word error rates, and language models can generate coherent text and perform complex reasoning. This progress comes at a cost: billions to trillions of parameters, petaflops of compute, and terabytes of memory bandwidth, which strain traditional CPUs and even GPUs that were originally built for graphics workloads.
To meet these demands, the industry has turned to specialized hardware. Application‑specific integrated circuits (ASICs) such as Google’s TPU, data‑flow architectures, and emerging neuromorphic chips tightly couple compute units with on‑chip memory, dramatically reducing data movement and improving energy‑per‑operation. The paper emphasizes that these designs are not merely faster versions of existing processors; they embody a new design philosophy that treats memory, interconnect, and compute as a unified substrate.
A central technical insight is the shift toward sparsity and dynamic routing. Current deep networks are dense—every neuron fires for every input—yet most inference tasks only need a small subset of the network. By activating only the relevant sub‑network (sparse activation) and routing inputs through task‑specific pathways (dynamic routing), hardware can cut arithmetic operations and memory accesses by an order of magnitude or more. Realizing this requires hardware support for conditional execution, variable‑length pipelines, and fast address translation, as well as new instruction‑set extensions and compiler techniques that can generate sparsity‑aware code.
Beyond hardware, the authors explore how machine learning can assist the design process itself. Deep models trained on historical design data can predict power, timing, and layout quality, while reinforcement‑learning agents can automate placement, routing, and even generate novel floor‑plan topologies. This “ML‑for‑EDA” loop promises to shorten design cycles, reduce human error, and enable more aggressive optimization of system‑on‑chip (SoC) blocks.
Finally, the paper sketches a forward‑looking research direction: large‑scale multi‑task models that are sparsely activated and dynamically routed on a per‑example basis. Such models would maintain a massive shared knowledge base but instantiate only the task‑relevant pathways for each input, dramatically lowering the average compute and memory footprint. Hardware that can interpret a runtime routing table and power‑gate unused units would make it feasible to host many diverse AI services on a single chip without the prohibitive cost of fully dense models.
In summary, the deep‑learning revolution forces a re‑evaluation of traditional computing paradigms. Post‑Moore’s Law architectures must embrace sparsity, dynamic dataflow, and tight compute‑memory integration, while leveraging AI to automate and accelerate the chip design workflow. Together, these trends point toward a future where a single, highly configurable silicon substrate can efficiently serve a wide spectrum of AI workloads, delivering unprecedented performance and energy efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment