An introduction to decentralized stochastic optimization with gradient tracking
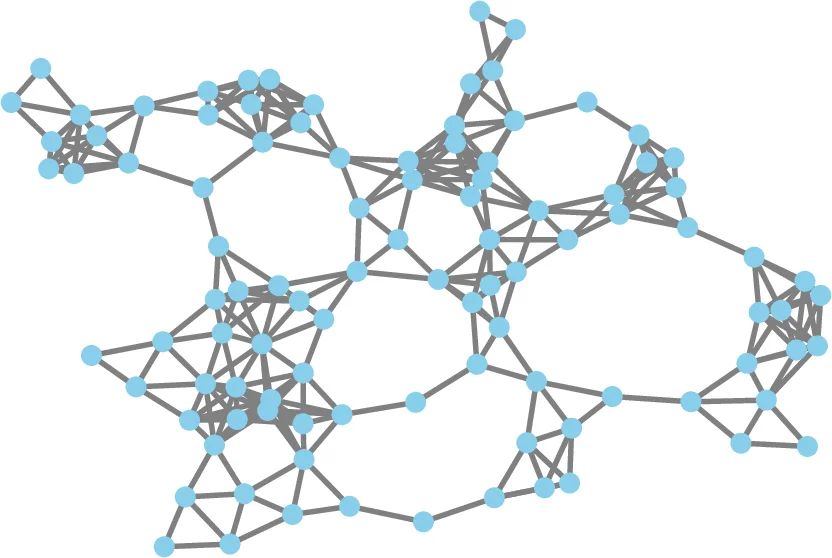
Decentralized solutions to finite-sum minimization are of significant importance in many signal processing, control, and machine learning applications. In such settings, the data is distributed over a network of arbitrarily-connected nodes and raw data sharing is prohibitive often due to communication or privacy constraints. In this article, we review decentralized stochastic first-order optimization methods and illustrate some recent improvements based on gradient tracking and variance reduction, focusing particularly on smooth and strongly-convex objective functions. We provide intuitive illustrations of the main technical ideas as well as applications of the algorithms in the context of decentralized training of machine learning models.
💡 Research Summary
This paper provides a comprehensive review of decentralized stochastic first‑order optimization methods, focusing on recent advances that combine gradient tracking with variance‑reduction techniques. The authors begin by recalling the classical empirical risk minimization (ERM) framework, where a model parameter vector θ∈ℝ^p is learned by minimizing the expected loss over a data distribution. Since the true distribution is rarely available, practitioners replace it with a finite‑sum empirical loss F(θ)= (1/N)∑{i=1}^N f_i(θ). For smooth and strongly‑convex functions (the class S{μ,L}), they discuss the basic stochastic gradient descent (SGD) algorithm, its convergence properties under constant and diminishing step‑sizes, and the limitations caused by gradient variance.
To overcome SGD’s variance issue, the paper surveys two popular variance‑reduction (VR) schemes: SAGA and SVRG. SAGA maintains a table of the most recent component gradients, forming an unbiased gradient estimator that progressively reduces variance. Under appropriate step‑size choices, SAGA achieves linear convergence with a complexity of O(max{N,κ})·log(1/ε), where κ=L/μ is the condition number. SVRG, on the other hand, periodically computes the full batch gradient and performs a fixed number of inner stochastic updates with a corrected gradient estimator. Its total cost is O((N+κ)·log(1/ε)), comparable to SAGA but with lower memory requirements. Both methods converge geometrically to the exact optimum, unlike plain SGD which only attains a neighborhood of the solution unless a diminishing step‑size is used.
The authors then transition to the decentralized setting. A network of n nodes is modeled as an undirected, connected graph G=(V,E) with a doubly‑stochastic weight matrix W. Each node i holds a private local empirical risk f_i(θ)= (1/m_i)∑{j=1}^{m_i} f{i,j}(θ). The global objective is F(θ)= (1/n)∑{i=1}^n f_i(θ). Because nodes can only exchange information with immediate neighbors, a consensus mechanism is required. The paper reviews average‑consensus, where each node updates its local copy via θ_i^{k+1}=∑{r∈N_i} w_{ir} θ_r^k, which converges geometrically to the average of the initial states at a rate determined by the second‑largest eigenvalue λ of W.
Building on consensus, Decentralized Gradient Descent (DGD) adds a local gradient correction: θ_i^{k+1}=∑{r∈N_i} w{ir} θ_r^k − α_k ∇f_i(θ_i^k). While DGD is simple, its convergence suffers from the same variance issues as SGD and requires diminishing step‑sizes for exact convergence, leading to slow progress.
To address this, the paper introduces gradient tracking (GT). Each node maintains an auxiliary variable y_i^k that tracks the average of all nodes’ gradients. The GT update is
y_i^{k+1}=∑{r∈N_i} w{ir} y_r^k + ∇f_i(θ_i^{k+1})−∇f_i(θ_i^k).
When combined with the consensus step, the pair (θ_i^k, y_i^k) evolves such that θ_i^k converges linearly to the global minimizer θ^* even with a constant step‑size, while y_i^k remains an accurate estimate of the full gradient. This mechanism effectively distributes the gradient information across the network without a central coordinator.
The authors then discuss how to fuse GT with variance‑reduction. Two representative algorithms are presented: decentralized SAGA‑GT and decentralized SVRG‑GT. In decentralized SAGA‑GT, each node stores its own gradient table and uses GT to correct the local stochastic gradient, achieving a total complexity of O(max{N,κ})·log(1/ε) with communication cost proportional to the spectral gap (1−λ). Decentralized SVRG‑GT performs periodic full‑gradient aggregations across the network, then runs inner GT‑corrected stochastic steps; its overall cost is O((N+κ)·log(1/ε)). Both methods retain the linear convergence guarantees of their centralized counterparts while operating under the communication constraints of the graph.
Extensive numerical experiments validate the theory. The authors test synthetic quadratic problems and real machine‑learning tasks such as logistic regression and deep neural network training on benchmark datasets. Gradient‑tracking‑based methods consistently outperform plain DSGD, often by a factor of 5–10 in iteration count, especially when the condition number κ is large (ill‑conditioned problems). Experiments on different topologies (ring, grid, random graphs) reveal that a smaller λ (i.e., better connectivity) accelerates convergence, confirming the role of the network’s spectral properties. Moreover, because raw data never leaves a node—only gradient and tracking information are exchanged—the proposed schemes provide inherent privacy benefits.
In conclusion, the paper positions gradient tracking as a pivotal tool for translating centralized stochastic optimization algorithms into fully decentralized versions. When combined with variance‑reduction, it yields algorithms that are both communication‑efficient and capable of high‑precision solutions for smooth, strongly‑convex problems. The authors suggest future research directions including extensions to non‑convex objectives, asynchronous updates, and integration with differential privacy or secure multiparty computation to further protect sensitive data.
Comments & Academic Discussion
Loading comments...
Leave a Comment