Zero-shot task adaptation by homoiconic meta-mapping
How can deep learning systems flexibly reuse their knowledge? Toward this goal, we propose a new class of challenges, and a class of architectures that can solve them. The challenges are meta-mappings, which involve systematically transforming task behaviors to adapt to new tasks zero-shot. The key to achieving these challenges is representing the task being performed in such a way that this task representation is itself transformable. We therefore draw inspiration from functional programming and recent work in meta-learning to propose a class of Homoiconic Meta-Mapping (HoMM) approaches that represent data points and tasks in a shared latent space, and learn to infer transformations of that space. HoMM approaches can be applied to any type of machine learning task. We demonstrate the utility of this perspective by exhibiting zero-shot remapping of behavior to adapt to new tasks.
💡 Research Summary
The paper introduces a new class of challenges called meta‑mappings, which are functions that take a task representation as input and output a transformed task representation. Humans routinely adapt to new tasks by re‑interpreting or modifying their existing task knowledge (e.g., switching from “win” to “lose” in a game) without seeing any new examples. Existing zero‑shot learning approaches typically generate a brand‑new representation for a new task from a description, discarding much of the previously learned knowledge. To emulate human‑like flexibility, the authors propose Homoiconic Meta‑Mapping (HoMM) architectures that embed data points, tasks, and meta‑mappings in a single shared latent space Z. Because tasks are represented as points in the same space as data, the same meta‑learning machinery can be used both to learn a task from examples and to transform an existing task representation into a new one.
The HoMM architecture consists of four components: (1) domain‑specific encoders/decoders (I, O, T) that map raw inputs, outputs, and targets into Z; (2) a meta‑network M that collapses a set of (input‑Z, target‑Z) pairs into a single function embedding z_f; (3) a hyper‑network H that maps a function embedding to the parameters of a downstream transformation network F; and (4) the transformation network F itself, which operates on probe inputs in Z. For ordinary meta‑learning, M and H are trained so that, given a few example pairs for a new function, the system can generate a functional predictor that correctly maps unseen probe inputs to outputs. This is essentially a modern meta‑learning pipeline (similar to MAML or Proto‑Net) but with the crucial twist that the function embedding lives in the same space as ordinary data points.
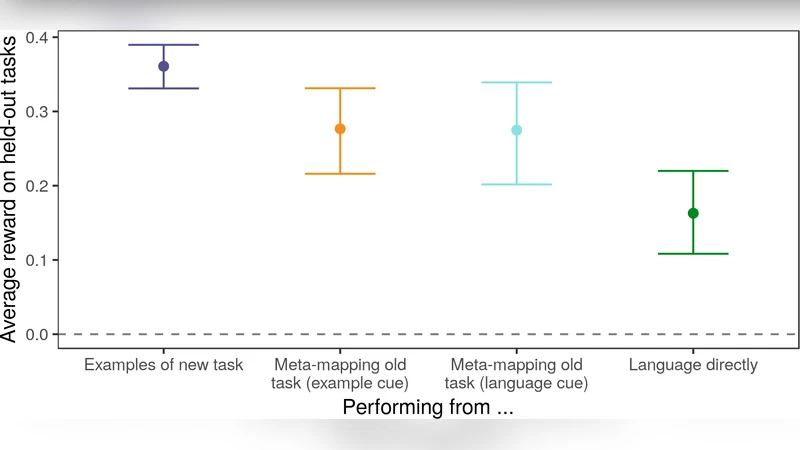
Meta‑mapping extends this idea one level higher: a task embedding can be treated as data and fed through the same M‑H‑F pipeline to produce a new task embedding. For example, to turn a “win at game 1” embedding into a “lose at game 1” embedding, the system first learns a meta‑mapping embedding z_meta from examples of win/lose pairs for other games. Then a transformation F_{z_meta} (parameterized by H(z_meta)) is applied to the original game 1 embedding, yielding a guessed “lose” embedding. The quality of this transformed embedding is evaluated by descending back to the lower level: the new embedding is fed to H to instantiate a policy network, which is then tested on the actual game. Because the transformation occurs entirely in latent space, the new task can be performed zero‑shot, i.e., without any direct training data for that specific task.
The authors validate HoMM on two domains. In the multivariate polynomial domain, the system must learn degree‑≤2 polynomials in four variables from a handful of (x, p(x)) examples. Basic meta‑learning successfully generalizes to unseen polynomials with high sample efficiency. Meta‑mappings such as scaling by a constant, squaring, or permuting input variables are learned from a set of example transformations, and the model can apply these to novel polynomials it has never seen, achieving accurate predictions without additional data. In the card‑game domain, the model learns strategies for a variety of games (e.g., poker, blackjack). After training on win‑strategies for several games, a meta‑mapping that converts “win” to “lose” is learned from win/lose pairs of other games. When applied to a held‑out game, the transformed “lose” embedding produces a policy that indeed loses at a rate far above the baseline of simply re‑using the most similar trained win‑policy. This demonstrates that HoMM captures structural relationships between tasks rather than merely memorizing the nearest example.
Key advantages of HoMM are parameter parsimony and generality. The same meta‑network M and hyper‑network H are reused for both basic tasks and meta‑mappings, so no extra parameters are required to gain the additional flexibility. By swapping only the input/output encoders, the framework can be applied to vision, language, reinforcement learning, or any modality. Limitations include the need for a sufficiently diverse set of meta‑mapping examples during training; transformations far outside the training distribution may still require fine‑tuning. Moreover, the current experiments focus on relatively simple, mostly linear or low‑order nonlinear transformations; extending the approach to more complex logical or sequential transformations remains an open challenge.
Future directions suggested by the authors include (1) mapping natural‑language instructions directly to meta‑mapping embeddings, enabling instruction‑following behavior; (2) learning chains of meta‑mappings to handle compound task adaptations; and (3) theoretical analysis of the minimal number of meta‑mapping examples needed for reliable zero‑shot transfer. Overall, the paper provides a compelling demonstration that treating tasks as first‑class citizens in a shared latent space—mirroring the homoiconic principle from programming—allows deep learning systems to reuse and transform knowledge in a way that more closely resembles human cognitive flexibility.
Comments & Academic Discussion
Loading comments...
Leave a Comment