The Pitfall of Evaluating Performance on Emerging AI Accelerators
In recent years, domain-specific hardware has brought significant performance improvements in deep learning (DL). Both industry and academia only focus on throughput when evaluating these AI accelerators, which usually are custom ASICs deployed in datacenter to speed up the inference phase of DL workloads. Pursuing higher hardware throughput such as OPS (Operation Per Second) using various optimizations seems to be their main design target. However, they ignore the importance of accuracy in the DL nature. Motivated by this, this paper argue that a single throughput metric can not comprehensively reflect the real-world performance of AI accelerators. To reveal this pitfall, we evaluates several frequently-used optimizations on a typical AI accelerator and quantifies their impact on accuracy and throughout under representative DL inference workloads. Based on our experimental results, we find that some optimizations cause significant loss on accuracy in some workloads, although it can improves the throughout. Furthermore, our results show the importance of end-to-end evaluation in DL.
💡 Research Summary
The paper “The Pitfall of Evaluating Performance on Emerging AI Accelerators” challenges the prevailing practice of assessing AI‑specific ASIC accelerators solely by raw throughput metrics such as OPS, TOPS, or frames‑per‑second (FPS). While modern datacenter accelerators are indeed engineered to maximize hardware‑level throughput, the authors argue that this focus neglects a fundamental aspect of deep learning: inference accuracy. To substantiate this claim, they conduct a systematic experimental study on a representative custom ASIC called ACC‑1, which features four channels, each with eight compute cores and a DDR memory subsystem, and runs a Caffe‑based software stack.
The benchmark suite comprises twelve well‑known convolutional neural networks (CNNs) spanning AlexNet, VGG‑16/19, GoogLeNet, ResNet‑18/34/50/101/152, Inception‑V3, MobileNet, and SqueezeNet, all evaluated on the ImageNet dataset (and CIFAR‑10 for ResNet‑50). For each model the authors record three key figures: (1) hardware FPS (the raw compute throughput inside the accelerator), (2) end‑to‑end FPS (including host‑CPU data loading, PCIe transfer, and accelerator execution), and (3) TOP‑1 classification accuracy. Two widely used optimization techniques—INT8 quantization and weight pruning—are applied separately to each model, allowing a direct comparison between the baseline FP16 implementation and the optimized versions.
Key Findings
-
INT8 Quantization: Converting weights and activations from FP16 to 8‑bit integers reduces memory bandwidth and arithmetic intensity, yielding a 30‑40 % increase in hardware FPS across most models. However, TOP‑1 accuracy suffers a non‑trivial drop ranging from 0.6 % to 1.4 % depending on the network. Lightweight models such as GoogLeNet and MobileNet experience the largest degradation (≈1.3 %). Moreover, the end‑to‑end FPS does not always improve; for Inception‑V3 and SqueezeNet the additional data‑movement overhead caused by quantization actually reduces overall throughput. This demonstrates that higher hardware throughput does not automatically translate into higher system‑level performance.
-
Weight Pruning: Introducing sparsity into the weight tensors boosts hardware FPS proportionally to the sparsity level because the accelerator can skip zero‑valued operations. Yet, as sparsity rises, the host‑CPU must manage increasingly irregular data transfers, leading to load‑balancing bottlenecks that cap or even diminish end‑to‑end FPS. Accuracy remains stable up to moderate sparsity (≈50 %), but beyond roughly 70 % pruning the TOP‑1 score drops sharply, indicating a steep accuracy‑throughput trade‑off.
-
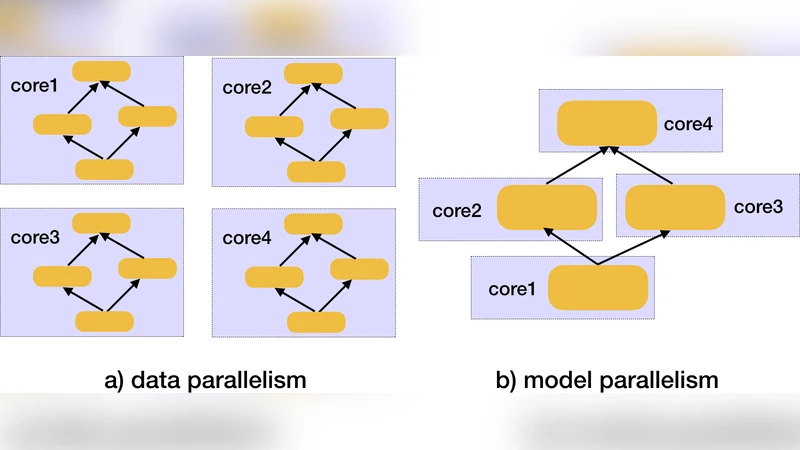
Parallelism and Pipelining: The paper briefly mentions data parallelism, model parallelism, and input‑pipeline techniques as additional levers for throughput. While these methods can further increase raw FPS, the study does not isolate their impact on accuracy, reinforcing the central message that any performance‑oriented optimization must be evaluated in the context of the full inference pipeline.
Methodological Contributions
- The authors distinguish between hardware FPS (pure compute speed) and end‑to‑end FPS (real‑world throughput including I/O), highlighting the importance of system‑level bottlenecks.
- They adopt TOP‑1 accuracy as a hard constraint, mirroring the practice of “time‑to‑accuracy” used in training benchmarks, and extend it to inference evaluation.
- By using a consistent software stack (customized Caffe) and identical workload configurations across all experiments, they ensure that observed differences stem from the optimization techniques themselves rather than implementation variance.
Limitations and Future Work
The study is confined to CNN‑based image classification workloads; the authors acknowledge that recurrent neural networks, transformers, and other modalities may exhibit different sensitivity to quantization and pruning. Cross‑platform validation (e.g., comparing ACC‑1 with GPUs, TPUs, or other ASICs) is also absent, limiting the generality of the conclusions. Finally, the reliance on publicly available pre‑trained models, which may not be fully optimized for the target hardware, introduces an uncontrolled variable that could affect both accuracy and throughput.
Implications
The paper’s findings have practical implications for both hardware designers and system architects. Designers should incorporate accuracy‑preserving constraints into the hardware‑level optimization flow, perhaps by providing mixed‑precision support or adaptive sparsity handling that mitigates host‑CPU bottlenecks. System architects must benchmark accelerators with end‑to‑end pipelines that include data loading, transfer, and scheduling overhead, rather than reporting only peak OPS or TOPS numbers.
Conclusion
In summary, the authors demonstrate that a single throughput metric is insufficient for evaluating emerging AI accelerators. INT8 quantization and weight pruning can indeed raise raw compute throughput, but they may also incur measurable accuracy loss and, paradoxically, reduce overall inference speed due to system‑level inefficiencies. The paper advocates for a holistic evaluation framework that jointly considers hardware throughput, end‑to‑end throughput, and accuracy constraints, thereby providing a more realistic picture of accelerator performance in real‑world deployments.
Comments & Academic Discussion
Loading comments...
Leave a Comment