Unfairness towards subjective opinions in Machine Learning
Despite the high interest for Machine Learning (ML) in academia and industry, many issues related to the application of ML to real-life problems are yet to be addressed. Here we put forward one limitation which arises from a lack of adaptation of ML …
Authors: Agathe Balayn, Aless, ro Bozzon
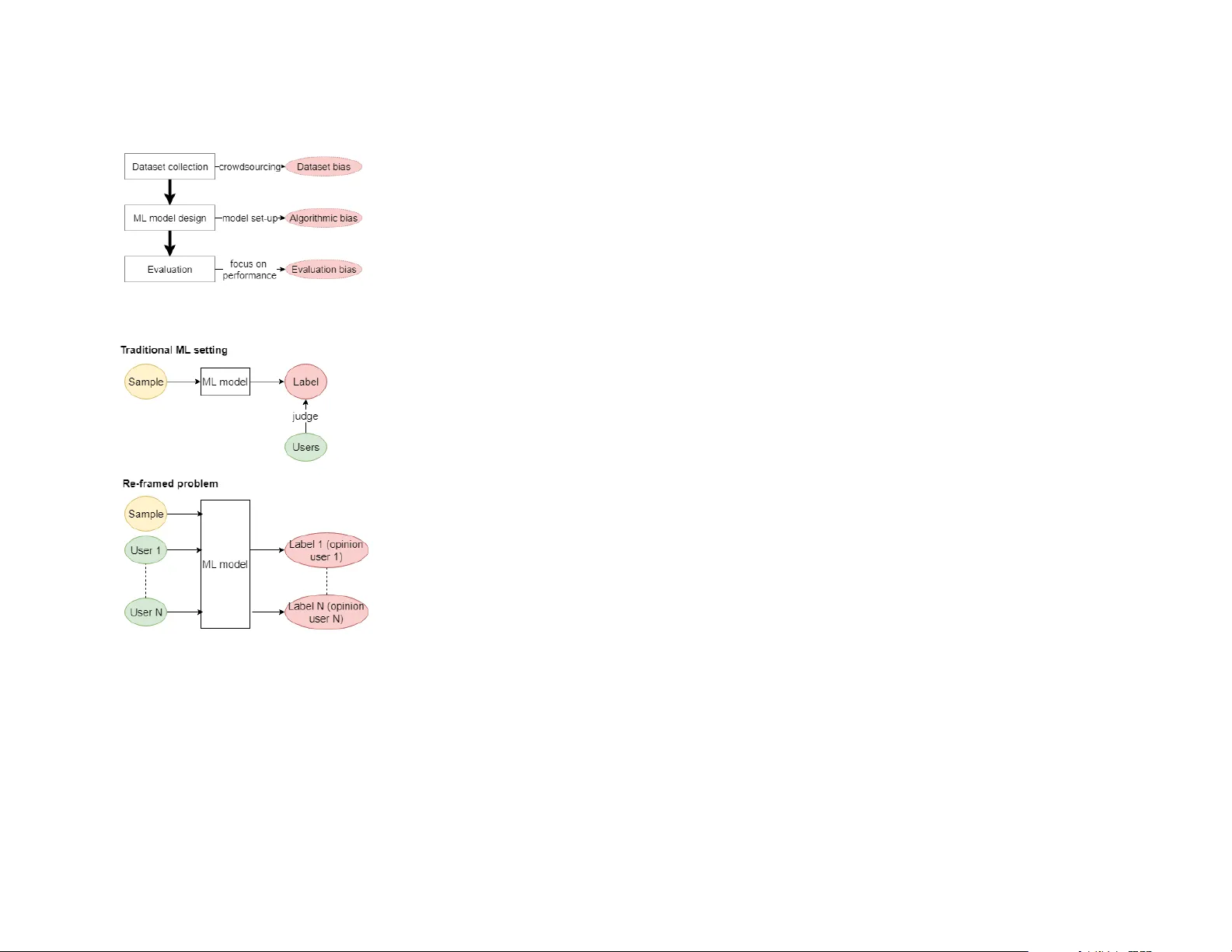
Unfairness towar ds subjective opinions in Machine Learning Agathe Balayn A.M.A.Balayn@tudel.nl Del University of T echnology , IBM Center for Advanced Studies Alessandro Bozzon a.bozzon@tudel.nl T U Del, W eb Information Systems Del, the Netherlands Zoltán Szlávik zoltan.szlavik@nl.ibm.com IBM Center for Advanced Studies Amsterdam, the Netherlands ABSTRA CT Despite the high interest for Machine Learning (ML) in academia and industry , many issues related to the application of ML to real-life problems are y et to be addressed. Here we put forward one limitation which arises from a lack of adaptation of ML models and datasets to specific applications. W e formalise a new notion of unfairness as exclusion of opinions. W e propose ways to quantify this unfairness, and aid understanding its causes thr ough visualisation. These insights into the functioning of ML-based systems hint at methods to mitigate unfairness. INTRODUCTION KEYWORDS Machine Learning, unfairness, subje ctivity , bias, toxicity prediction Machine Learning (ML) is increasingly employ ed in real-life applications. Originally used to classify various types of samples based on objective labels, it is now also employed for classification tasks of subjective labels (see sidebar) [ 15 , 19 ]. In such tasks, samples can not be associated with clear unique ground truth lab els since the pr operty to be assessed (and predicted) is subjective , and might therefor e Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commer cial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must b e honored. For all other uses, contact the owner /author(s). CHI HCML Perspectives ’19, May 04, 2019, Glasgow © 2019 Copyright held by the owner/author( s). Unfairness towards subjective opinions in Machine Learning CHI HCML Perspectives ’19, May 04, 2019, Glasgow be subject to biases or dierences in perception and interpretation from each individual assessor of Examples of objective classification tasks: • digit recognition from images [14], • human activity recognition from videos [12], • spam filtering from text [1]. Subjective classification tasks: • violence of a video segment [17], • aesthetic of an image [4], • sentiment of a sentence [20], • toxicity of a sentence [23]. Opinion diversity in subjective tasks: T able 1 (below ) illustrates the div ersity of anno- tators’ opinions on toxicity , which would b e ig- nored in a traditional single-label dataset. 61% of the samples in the dataset bear disagree- ments for binary annotations, and even more for a 5-point Likert scale. T able 1: Example samples and annotations of an ML dataset for the task of predicting sentence toxicity (T: toxic, NT: non-toxic). sample annotations Is there perhaps enough newswor- thy information to make an article about the Bundy family as a whole, that the various family members can be redirected to? Or do es that violate a guideline I’m not aware of ? N T(100%) What shit u talk to me, communist rat? T(100%) Please relate the ozone hole to in- creases in cancer , and provide fig- ures. Otherwise, this article will be biased toward the environmentalist anti-CFC point of view instead of being neutral. T(20%) N T(80%) The article is true, the Israeli policies are killing Arab children. T(50%) N T(50%) the dataset. W e argue that this shi of focus has a p otential negative impact on the end-users of the applications whose opinions/perspectives might not b e refle cted by the system when they have not been captured in the data or/and in the model’s outputs. Specifically , we claim that the traditional way of conceiving ML-based systems is not adapted to the cases of subjective classifications, and that it leads to unfairness towards certain end-users but also to potential dangers towards society as a whole. Although the impact concerns end-users, w e use interchangeably assessors and end-users since we measure its magnitude based on the assessors’ data used as a pro xy for the end-users’ data that are not available in the dataset. The issue concerning dierences b etween the assessors and end-users populations is relevant, but not within the scope of this work. ML models usually output a single label p er input representing a single opinion (oen the majority one) or the averaged opinion (in case of numerical labels) which might not correspond to any individual. Outpuing this label (or its distribution) might not be suicient depending on the application. First, it conducts to ignoring part of the users’ opinions in potentially dierent proportions. That makes certain users’ experience of the system less valued than for others and can b e perceived as unfairness towards these end-users whose opinions might never be show cased. Second, always ignoring certain opinions, mostly from the minority , and accounting for specific opinion trends contribute to the reinforcement of filter bubbles on the W eb. This is an emergent danger for societies [6]. W e name this issue unfairness as a notion of opinion exclusion and define it as an inequality of inclusion of the opinions of the users in the outputs of the ML system . W e put forward that, by resolving it, it would be p ossible to minimise potential negative eects coming from the applications of the systems both on a user and society level. In the following, we propose an initial strategy to evaluate and mitigate this unfairness, that we expose through the example of an ML model trained to predict whether a sentence is toxic or not. Y et the work is applicable to any subjective classification task. CAUSES OF UNF AIRNESS ALONG THE ML PIPELINE Looking deeper into the traditional ML pipeline, we identified three elements which contribute to causing unfairness, that all have to be addressed (Figure 1). Algorithmic bias: ML research tackling the classification of subjective properties simply considers that the task can be repr esented using unique binary labels ignoring the subjectivity [ 4 , 20 ] sometimes removing the data with the most disagreement, and aggregating the rest. So lab els are also em- ployed [ 18 , 23 ] to account for the opinion diversity but this does not enable to identify the opinion of each individual. Only one paper [ 5 ] has considered the opinions of dierent categories of p opulation (male and female) but it was shown that there is also disagreement within the categories. W e suggest the whole problem to be re-framed in order to address unfairness. Here we do not wish to output one label for one sample, but one label for an input being the data sample and the spe cific user of the Unfairness towards subjective opinions in Machine Learning CHI HCML Perspectives ’19, May 04, 2019, Glasgow application (Figure 2). In this way , the creators of the application would have access to the opinion Figure 1: The sources of unfairness in the traditional ML pipeline. Figure 2: Traditional ML task and re- framed problem. In the re-framed problem, we advocate for out- puing one label for each input tuple consisting of a sample and an end-user . During the train- ing phase, this corresponds to tuples of samples and assessors. of each individual user and they could adapt the decision making process within the system not only to the data sample but to the user as well. For instance in social media, wher e one w ould wish to filter out toxic sentences, for each end-user we w ould not hide information that they , individually , might not see as non-toxic, but they would be protected from what they individually might perceive as toxic (e .g. in cases where a child and an adult do not have the same perception of sentence toxicity ). Dataset bias: The way of creating datasets tends to bias the data to wards certain types of opinions. Since models are trained on these data, their outputs are automatically unfair . Besides, they are tested on the same type of data and consequently the unfairness might be missed. Indeed, most ML datasets have their labels collected via crowdsourcing ( annotators label samples ref lecting their opinions on these), which should enable the collection of true opinions. However , due to annotation quality issues (mistakes, spamming), researchers and practitioners need to exclude low quality inputs, but current methods can not distinguish these from low popularity opinions, and lead to the sele ction of only one opinion per sample, leading to exclusion. Indeed to avoid the problem, several annotators label a sample and the annotations ar e aggregated into a unique , more accurate label ( e.g. by majority-voting -MV or by a probabilistic approach [ 16 , 22 ]), assuming that the more annotators there are the higher the chance is to get a majority of correct annotations. This implies that correct labels are labels on which annotators agree, but subjectivity involves disagreement and consequently the assumption does not hold (example T able 1). Thus, this process automatically biases datasets towards a unique kind of opinion ref lected via the aggregation method sele cted. Few works leverage the disagreement to filter out the wrong annotators and annotations. The Crow dTruth frame work enables to compute quality scores to quantify the annotators’ quality and the samples’ ambiguity based on their disagreement [ 2 ]. Collaborative approaches of discussion and argumentation b etween annotators are also taken to refine the crowdsour cing task and get high-quality lab els [ 7 , 9 ], but this still implies a unique ground truth. Groups of annotators with similar annotation trends can also be identified by clustering to possibly discover annotators of high-quality or having spe cific interpretations of the tasks, but this is not yet scalable to a large number of annotators annotating dierent samples [13]. Evaluation bias: The notion of fairness as exclusion of opinions being new , there is no established way to evaluate it. Pre vious research is directed at unfairness as a notion of discrimination to wards protected categories of population, fo cusing on models which classify people over certain labels (e.g. whether someone who commied a crime will reoend) [ 10 ]. Recently , research has also studie d unfairness in the ML process (mainly the choice of p ossibly unfair features) [ 11 ]. Consequently , current systems’ evaluation methods are biased towards performance metrics and unfairness as discrimination. The lack of adapted metric fosters exclusion in current systems since ML practitioners are not aware of the problem, or hav e no tool to consider it in their systems. Therefore, we adv ocate for investigating the evaluation of unfairness and propose initial resear ch ideas in the next sections. Unfairness towards subjective opinions in Machine Learning CHI HCML Perspectives ’19, May 04, 2019, Glasgow METHODS TO UNDERST AND AND MITIGA TE UNF AIRNESS Requirements for the unfairness measure: (1) antifies unfairness. (2) antifies general model performance (to obser ve the trade-o between fair- ness and performance since a model could be totally fair and inaccurate). (3) Is independent fr om the e valuation dataset. (4) Is adaptable to the performance met- ric(s) important for the application. (5) Provides insights into causes of unfair- ness. Grouping criteria to understand unfair- ness. W e assume that the main reason for which un- fairness can occur is the diiculty of ML mo dels to predict certain opinions (generally the un- common opinions). This diiculty might mani- fest in multiple ways that can be investigated through the following grouping seings. • Sample-level: Ambiguous samples might present mor e disagreement making the opin- ions on them harder to discov er by the mo del. Grouping samples based on their ambiguity would point out these diiculties. • Annotation-level: Popular annotations for a sample are seen more oen by the ML model during training, and consequently , should be easier to predict. Grouping annotations based on their popularity (percentage of iden- tical annotations within a sample ’s annota- tions) would highlight this. • User-level: Apart from the disagreement among users, users of a certain category of population might have similar opinions. Grouping these users would show whether certain categories are discriminated against for the benefit of others. Our proposition to identify and quantify unfairness in ML Here we define an ML model to b e unfair when its performance is unequal across its users (opinions would not be equally accounted for among users). Although this definition suggests easy ways to identify whether a model is unfair , we also need 1) to quantify unfairness in order to minimise it and to compare models on other criteria than traditional p erformance measures, and 2) to investigate potential causes of unfairness. T o quantify unfairness, a metric should satisfy the requirements listed in the sidebar . W e propose the following evaluation method. a) Group the users of the mo del in the dataset base d on their disagreement rate with the other users (we compute the average disagreement rate - ADR - per user as the percentage of times a user’s annotations are dierent from the MV b ecause we assume the MV is representative of the outputs of the traditional unfair ML model). This enables to obtain comparable values for dierent datasets which would b e constituted of the same groups’ characteristics. b) Compute model performance for each user , and the mean of these values within each group. c) Compute the standard deviation and mean across the groups’ performance to quantify unfairness and general model performance, respectively . The performance metric is chosen by the ML practitioner and several metrics can be combined by averaging the results. T o investigate potential causes of unfairness, we visualise the performance of each individual group . W e hypothesize it enables to identify where inequalities come from and to point out the types of users for which the predictions should be improv ed. Additionally , we suggest other criteria (see sidebar ) to group the dataset in order to beer understand how the ML model behaves and which are the inaccuracies that make the model unfair . Considerations to de crease unfairness T o mitigate dataset bias and maintain a diversity of opinions, we must not aggregate the annotations. W e propose first to use a quality contr ol mechanism (e .g. Crow dTruth frame work) to filter out the lowest quality annotators giving wrong annotations. Second, we can employ disagreement as a signal to identify valid but unpopular opinions and dierentiate them from occasional annotators’ mistakes. Regarding algorithmic bias, w e envision two main lines of work which could ev entually be combined. Usually , few data points per user are known at training time , thus it is neither possible nor scalable to train one accurate model per user . A solution is to train models with certain parameters conditioned on the users (e .g. [ 21 ] for recommender systems), where preferences of ne w users should be learned at run time. Another possibility is to leverage the kno wledge of other fields such as Psychology to find the internal characteristics of a user , which inf luence their perception of a lab el (or deduce these variables with additional ML models) and input these as features encoding each user . Unfairness towards subjective opinions in Machine Learning CHI HCML Perspectives ’19, May 04, 2019, Glasgow Examples for sentence toxicity prediction The three ML mo dels: T able 2: First two ML mo dels used to anal- yse the unfairness evaluation method. Model 1 Model 2 Inputs samples samples + demo- graphics Ground truth MV annotations Unfairness value 0.07 0.04 General performance 0.68 0.68 W e add the demographic information to Model 2 ’s inputs b ecause Psychology literature high- lights these variables as the most influencing variables for perception of sentence toxicity [ 8 ]. Model 3 is a hypothetical, perfectly accurate model which returns the exact annotations for each annotator , and consequently , is fair . W e instantiate the models with Logistic Regres- sion classifiers trained and tuned using 5-fold cross validation, and compute the accuracy per- formance on a balanced evaluation dataset. Figure 3: Visualisation of the unfairness based on groups of annotators’ average disagreement rate with the MV (ADR). W e illustrate our method for a b eer understanding of unfairness using the dataset of [ 23 ] for sentence toxicity prediction, which includes opinions of ten annotators per sample with corresponding demographic information (age , gender , education). W e build three ML models with three dierent unfairness-related behaviors ( see sidebar). Models 1 to 3 are expected to b e less to most fair due to their training process. Figure 3 shows an example visualisation of the gr oups’ performance for annotators grouped on ADR scores. A s expecte d, Model 1 is mor e unfair than Model 2 since its performance across groups is more disparate than for Model 2 . The perfect model would present equal accuracy of 1 for each group and consequently an unfairness of 0 and performance of 1. The unfairness score (T able 2) ref lects this trend with a higher value for Model 1 , while the general p erformance is equal for the two models. The visualisation furthermore confirms the sources of unfairness in the models. W e obser ve that Model 1 is inaccurate at predicting the opinions of users who tend to disagree with the MV the most; this is beer in Model 2 , but not fully solved. ML practitioners could use these observations to further improve their model, for example , by collecting more data from specific annotators. Discussion The evaluation method meets the requirements to beer understand unfairness. Although applie d to a specific case focusing on accuracy with Logistic Regression, it is applicable to any type of subjective classification task, any performance metric(s) as well as ML model. T o thoroughly evaluate the eectiveness of the method in the future, we recommend first to perform user studies to understand whether the visualizations are both clear and informative to the users, and second to investigate whether integrating the visualizations within a human-in-the-loop unfairness mitigation methodology enables to eectively remove the biases. Our proposition accounts for group fairness. However , there might exist unfairness inside the groups themselves, and thus, metrics to measure individual fairness would also give dierent insights into the problem. Unsuper vised clustering of sentences with similar content, or of annotators with similar annotation trends could enable the discovery of other reasons for unfairness. E.g. it could identify annotators with a certain opinion trend, which might always be served badly by a model compared to annotators of another opinion line . Besides, we employ ed users’ demographics to improv e classification, howev er , this might be a privacy sensitive point for certain applications. Here appears a trade-o not only between fairness and accuracy , but also privacy , that presages more complexity in the ways to mitigate the issue . CONCLUSION In this paper , we discussed the issue of unfairness in the conte xt of ML-based systems, and we argued for a reconsideration of the problem at hand in other terms with more aention towards the human Unfairness towards subjective opinions in Machine Learning CHI HCML Perspectives ’19, May 04, 2019, Glasgow user . W e proposed ways to quantify unfairness, to explore its causes, and to mitigate them. The proposed approach is currently being implemented within the IBM AIF360 toolkit [ 3 ], in order to make it easily available for ML practitioners who would implement systems with potential ethical issues. This work falls within the br oader research dir ection of ethics, ML and explainability . Methods to make ML more fair might trigger additional ethical issues that remain to be investigated. REFERENCES [1] Tiago A Almeida, Tiago P Silva, Igor Santos, and José M Gómez Hidalgo. 2016. T ext normalization and semantic indexing to enhance instant messaging and SMS spam filtering. Knowledge-Based Systems 108 (2016), 25–32. [2] Lora Aroyo and Chris W elty . 2013. Crowd T ruth: Harnessing disagreement in crowdsour cing a relation extraction gold standard. W ebSci2013. ACM 2013 (2013). [3] R. K. E. Bellamy , K. Dey , M. Hind, S. C. Homan, S. Houde, K. Kannan, P. Lohia, J. Martino , S. Mehta, A. Mojsilovic, S. Nagar , K. N. Ramamurthy, J. Richards, D . Saha, P. Saigeri, M. Singh, K. R. V arshney , and Y. Zhang. 2018. AI Fairness 360: An Extensible T o olkit for Detecting, Understanding, and Mitigating Unwanted Algorithmic Bias. [4] Simone Bianco, Luigi Celona, Paolo Napoletano, and Raimondo Scheini. 2016. Predicting image aesthetics with deep learning. In International Conference on Advanced Concepts for Intelligent Vision Systems . Springer , 117–125. [5] Reuben Binns, Michael V eale, Max V an Kle ek, and Nigel Shadbolt. 2017. Like trainer, like bot? Inheritance of bias in algorithmic content moderation. In International Conference on Social Informatics . Springer , 405–415. [6] Engin Bozdag and Jeroen van den Hoven. 2015. Breaking the filter bubble: democracy and design. Ethics and Information T e chnology 17, 4 (2015), 249–265. [7] Joseph Chee Chang, Saleema Amershi, and Ece Kamar . 2017. Revolt: Collaborative crowdsourcing for labeling machine learning datasets. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems . ACM, 2334–2346. [8] Gloria Cowan and Cyndi Hodge. 1996. Judgments of hate spe ech: The eects of target group, publicness, and behavioral responses of the target. Journal of A pplied Social Psychology 26, 4 (1996), 355–374. [9] Ryan Drapeau, Lydia B Chilton, Jonathan Bragg, and Daniel S W eld. 2016. Microtalk: Using argumentation to improve crowdsourcing accuracy . In Fourth AAAI Conference on Human Computation and Crowdsourcing . [10] Pratik Gajane and Mykola Pechenizkiy . 2017. On formalizing fairness in prediction with machine learning. [11] N Grgic-Hlaca, E M Redmiles, K P Gummadi, and A W eller . 2018. Human Perceptions of Fairness in Algorithmic Decision Making: A Case Study of Criminal Risk Prediction. In Proceedings of the 2018 Conference on W orld Wide W eb . 903–912. [12] Samitha Herath, Mehrtash Harandi, and Fatih Porikli. 2017. Going deeper into action recognition: A survey . Image and vision computing 60 (2017), 4–21. [13] Sanjay Kairam and Jerey Heer . 2016. Parting crowds: Characterizing divergent interpretations in crowdsourced annotation tasks. In Proceedings of the 19th ACM Conference on Computer-Supported Cooperative W ork & Social Computing . ACM. [14] Y LeCun, B E Boser , J S Denker, D Henderson, Richard E H, W E Hubbard, and L D Jackel. 1990. Handwrien digit recognition with a back-propagation network. In Advances in neural information pr ocessing systems . 396–404. [15] C. O’Neil. 2017. W eapons of math destruction: How big data incr eases inequality and threatens democracy . Broadway Books. [16] Vikas C Raykar , Shipeng Yu, Linda H Zhao, Gerardo Hermosillo V aladez, Charles Florin, Luca Bogoni, and Linda Moy . 2010. Learning from crowds. Journal of Machine Learning Research 11, Apr (2010), 1297–1322. [17] Markus Schedl, Mats Sjöb erg, Ionut Mironica, Bogdan Ionescu, Vu Lam ang, and Yu-Gang Jiang. 2015. V sd2014: a dataset for violent scenes detection in hollywood movies and web videos. Sixth Sense 6, 2.00 (2015), 12–40. Unfairness towards subjective opinions in Machine Learning CHI HCML Perspectives ’19, May 04, 2019, Glasgow [18] V . Sharmanska, D. Hernández-Lobato , J. Miguel Hernandez-Lobato, and N. adrianto. 2016. Ambiguity helps: Classifi- cation with disagreements in crow dsourced annotations. In Proceedings of the IEEE Conference on Computer Vision and Paern Recognition . [19] Michael Skirpan and Micha Gorelick. 2017. The Authority of " Fair" in Machine Learning. [20] Duyu Tang, Bing Qin, and Ting Liu. 2015. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 conference on empirical methods in natural language processing . 1422–1432. [21] Duyu T ang, Bing Qin, Ting Liu, and Y uekui Y ang. 2015. User Modeling with Neural Network for Review Rating Prediction.. In IJCAI . 1340–1346. [22] Jacob Whitehill, Ting-fan W u, Jacob Bergsma, Javier R Movellan, and Paul L Ruvolo. 2009. Whose vote should count more: Optimal integration of labels from labelers of unknown expertise. In Advances in neural information processing systems . [23] Ellery Wulczyn, Nithum Thain, and Lucas Dixon. 2017. Ex machina: Personal aacks seen at scale. In Procee dings of the 26th International Conference on W orld Wide W eb . International W orld Wide W eb Conferences Steering Commie e.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment