Deep-Learning-Based Audio-Visual Speech Enhancement in Presence of Lombard Effect
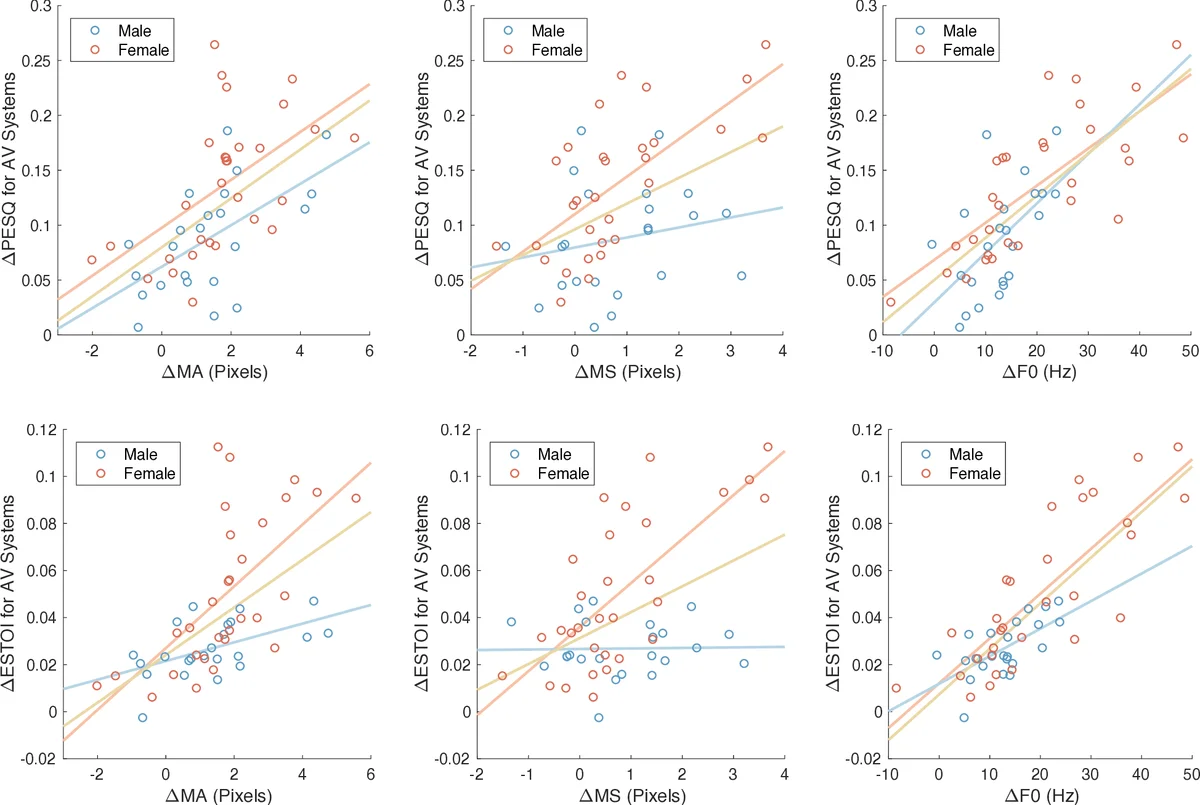
When speaking in presence of background noise, humans reflexively change their way of speaking in order to improve the intelligibility of their speech. This reflex is known as Lombard effect. Collecting speech in Lombard conditions is usually hard and costly. For this reason, speech enhancement systems are generally trained and evaluated on speech recorded in quiet to which noise is artificially added. Since these systems are often used in situations where Lombard speech occurs, in this work we perform an analysis of the impact that Lombard effect has on audio, visual and audio-visual speech enhancement, focusing on deep-learning-based systems, since they represent the current state of the art in the field. We conduct several experiments using an audio-visual Lombard speech corpus consisting of utterances spoken by 54 different talkers. The results show that training deep-learning-based models with Lombard speech is beneficial in terms of both estimated speech quality and estimated speech intelligibility at low signal to noise ratios, where the visual modality can play an important role in acoustically challenging situations. We also find that a performance difference between genders exists due to the distinct Lombard speech exhibited by males and females, and we analyse it in relation with acoustic and visual features. Furthermore, listening tests conducted with audio-visual stimuli show that the speech quality of the signals processed with systems trained using Lombard speech is statistically significantly better than the one obtained using systems trained with non-Lombard speech at a signal to noise ratio of -5 dB. Regarding speech intelligibility, we find a general tendency of the benefit in training the systems with Lombard speech.
💡 Research Summary
The paper investigates how the Lombard effect—an involuntary change in speech production that occurs when speakers talk in noisy environments—impacts deep‑learning‑based audio‑visual speech enhancement (AV‑SE) systems. While most speech enhancement research trains and evaluates models on clean recordings artificially corrupted with noise, real‑world communication often involves Lombard speech, which exhibits higher fundamental frequency, increased high‑frequency energy, flattened spectral tilt, and more pronounced lip and jaw movements. Ignoring these characteristics can lead to sub‑optimal performance in practical applications.
To address this gap, the authors use the Lombard GRID corpus, an extension of the well‑known GRID dataset. The corpus contains recordings from 55 native British English speakers (25 male, 30 female), each uttering 50 sentences in a quiet (non‑Lombard) condition and 50 sentences while exposed to 80 dB SPL speech‑shaped noise (Lombard condition). Audio is sampled at 16 kHz, and video is captured at 720 × 480 pixels with a frame rate around 24 fps; the frontal camera view is used to extract a 128 × 128 pixel mouth region.
The enhancement architecture follows the model introduced by Gabbay et al. (2018) and previously used by Michelsanti et al. (2019a). It consists of separate audio and video encoders (six convolutional layers each, leaky‑ReLU, batch normalization), a fusion sub‑network (three fully‑connected layers), and an audio decoder (six transposed‑convolution layers) that predicts an ideal amplitude mask (IAM). The mask is constrained to the range
Comments & Academic Discussion
Loading comments...
Leave a Comment