On the convergence properties of a $K$-step averaging stochastic gradient descent algorithm for nonconvex optimization
Despite their popularity, the practical performance of asynchronous stochastic gradient descent methods (ASGD) for solving large scale machine learning problems are not as good as theoretical results indicate. We adopt and analyze a synchronous K-step averaging stochastic gradient descent algorithm which we call K-AVG. We establish the convergence results of K-AVG for nonconvex objectives and explain why the K-step delay is necessary and leads to better performance than traditional parallel stochastic gradient descent which is a special case of K-AVG with $K=1$. We also show that K-AVG scales better than ASGD. Another advantage of K-AVG over ASGD is that it allows larger stepsizes. On a cluster of $128$ GPUs, K-AVG is faster than ASGD implementations and achieves better accuracies and faster convergence for \cifar dataset.
💡 Research Summary
This paper introduces and rigorously analyzes a synchronous K‑step averaging stochastic gradient descent algorithm, called K‑AVG, aimed at large‑scale machine learning tasks with non‑convex objectives. The authors begin by stating four standard assumptions: the objective function has an L‑Lipschitz continuous gradient, the iterates stay within a bounded region, stochastic gradients are unbiased, and their variance is uniformly bounded by a constant M. Under these conditions, K‑AVG operates by letting each of P processors perform K local SGD updates (using mini‑batches of size B) before a global reduction that averages all local parameters. When K = 1 the method reduces to the classic hard‑synchronization SGD; larger K values amortize communication over more computation, potentially reducing the communication bottleneck that plagues asynchronous SGD (ASGD) on GPU clusters.
The theoretical contributions are threefold. First, for a fixed stepsize γ and fixed batch size B, Theorem 3.1 provides an upper bound on the expected average squared norm of the gradient. The bound consists of a term that decays with the number of iterations N (proportional to the initial optimality gap) and a residual term that depends on γ, B, L, M, the number of processors P, and the delay K. Notably, the residual term scales as 1/(PB) and contains a factor 1/P, showing that increasing the number of workers reduces variance, but the benefit saturates when the term L(2K‑1)(K‑1)γ⁶ dominates. Second, Theorem 3.2 shows that if the stepsize diminishes appropriately and the batch size grows, the expected weighted average of the squared gradient norms converges to zero, restoring the classic O(N⁻¹/²) convergence rate for non‑convex problems while still enjoying the communication savings of K‑step averaging. The analysis also reveals that K‑AVG permits larger stepsizes than ASGD because the averaging operation acts as a variance‑reduction mechanism, relaxing the usual Robbins‑Monro condition Σγ² < ∞ to the milder Σγ³ < ∞.
Third, the paper compares scalability with ASGD. In ASGD, the staleness of gradients is typically bounded by the number of processors P, leading to an expected gradient norm bound that scales as O(1/P²). By contrast, the K‑AVG bound contains a 1/P factor, indicating superior scaling as the cluster size grows. The authors formalize this claim in Theorem 3.3 and support it with empirical results.
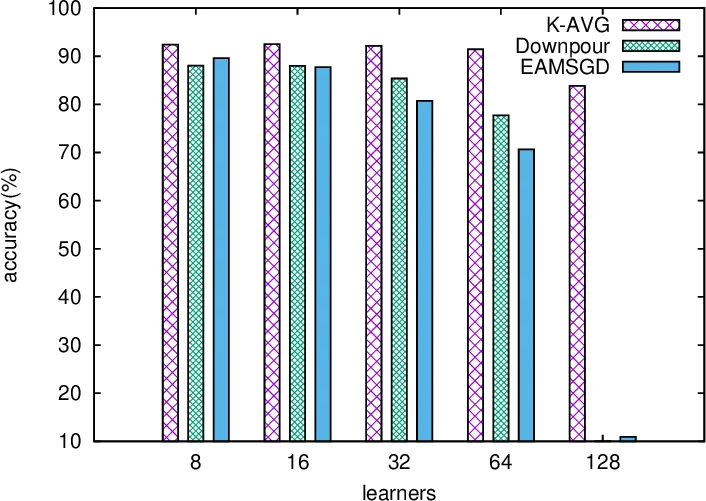
A particularly insightful part of the work is the discussion of the optimal delay K. Contrary to the common belief that more frequent averaging (smaller K) always accelerates convergence, Theorem 3.4 analyzes the scenario where the total number of processed samples NK is fixed. The theorem shows that there exists a non‑trivial optimal K that balances reduced communication overhead against slower global parameter updates. Experiments on CIFAR‑10 with 128 GPUs confirm that moderate K values (e.g., K ≈ 10–20) achieve faster wall‑clock convergence and higher final accuracy than both K = 1 (hard‑sync SGD) and asynchronous methods such as Downpour and EAMSGD. In some cases, K‑AVG is up to seven times faster than Downpour and 2–6 times faster than EAMSGD, while also delivering better test performance.
The experimental section details the implementation on a GPU‑direct enabled cluster, the choice of hyper‑parameters, and a systematic comparison of communication time, iteration count, and final accuracy across K‑AVG, ASGD variants, and traditional SGD. The results corroborate the theoretical predictions: larger batch sizes and more workers reduce variance, larger stepsizes are tolerated, and an appropriately chosen K yields the best trade‑off between computation and communication.
In summary, the paper makes a solid contribution by (1) providing the first comprehensive convergence analysis of K‑step averaging SGD for non‑convex objectives, (2) demonstrating that K‑AVG scales more favorably than asynchronous SGD as the number of processors grows, (3) showing that K‑AVG can safely employ larger learning rates, and (4) offering practical guidance on selecting the averaging interval K to achieve optimal performance on modern GPU clusters. The work bridges the gap between theoretical guarantees and practical efficiency, making K‑AVG a compelling alternative for large‑scale distributed deep learning.
Comments & Academic Discussion
Loading comments...
Leave a Comment