Effect of Mixed Precision Computing on H-Matrix Vector Multiplication in BEM Analysis
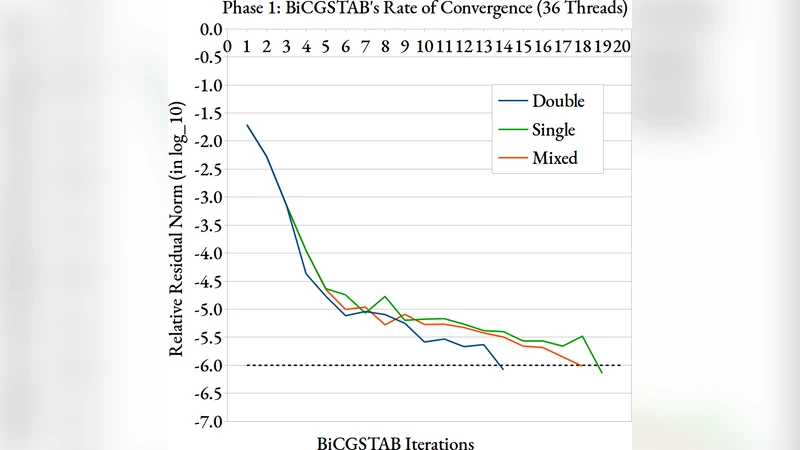
Hierarchical Matrix (H-matrix) is an approximation technique which splits a target dense matrix into multiple submatrices, and where a selected portion of submatrices are low-rank approximated. The technique substantially reduces both time and space complexity of dense matrix vector multiplication, and hence has been applied to numerous practical problems. In this paper, we aim to accelerate the H-matrix vector multiplication by introducing mixed precision computing, where we employ both binary64 (FP64) and binary32 (FP32) arithmetic operations. We propose three methods to introduce mixed precision computing to H-matrix vector multiplication, and then evaluate them in a boundary element method (BEM) analysis. The numerical tests examine the effects of mixed precision computing, particularly on the required simulation time and rate of convergence of the iterative (BiCG-STAB) linear solver. We confirm the effectiveness of the proposed methods.
💡 Research Summary
The paper investigates how mixed‑precision arithmetic can be used to accelerate hierarchical matrix (H‑matrix) vector multiplication, a core operation in many boundary element method (BEM) simulations. H‑matrices reduce the O(N²) storage and computational cost of dense matrices by partitioning the matrix into blocks and approximating many of those blocks with low‑rank representations, achieving near‑linear complexity. However, the actual numerical kernels that evaluate the low‑rank blocks and perform the hierarchical reductions are still dominated by double‑precision (binary64, FP64) arithmetic, which limits performance on modern hardware where single‑precision (binary32, FP32) throughput is often several times higher.
To address this gap, the authors propose three distinct ways of integrating mixed precision into the H‑matrix‑vector product (HMVP):
-
Level‑Based Mixed Precision – The hierarchical tree is traversed as usual, but only the leaf blocks that are stored in low‑rank form are evaluated in FP32. All higher‑level blocks (including the dense near‑field blocks) and the final accumulation are performed in FP64. This exploits the observation that low‑rank blocks contribute the bulk of the arithmetic while being less sensitive to rounding error.
-
Intermediate‑Result Compression – After each block‑wise multiplication the intermediate result vector is cast to FP32 and stored. The final result is reconstructed by summing these FP32 contributions in an FP64 accumulator. This reduces memory traffic and bandwidth demand, at the cost of an extra conversion step and a modest increase in rounding error.
-
Iterative‑Solver Mixed Precision – The BiCG‑STAB Krylov solver used for the BEM linear system is modified so that the preconditioner application and residual updates are carried out in FP32, while the core matrix‑vector product and scalar inner products remain in FP64. This approach keeps the most error‑sensitive operations in high precision while still gaining a performance boost from the cheaper FP32 work.
The experimental campaign focuses on a canonical electrostatic BEM problem: computing the surface potential of a conducting object in three dimensions. Problem sizes range from 10⁴ to 10⁵ degrees of freedom, covering both modest and large‑scale scenarios. For each mixed‑precision variant the authors measure (i) total wall‑clock time, (ii) peak memory consumption, (iii) the number of BiCG‑STAB iterations required for convergence, and (iv) the final relative residual compared with a pure FP64 reference.
Results show that the level‑based scheme delivers the most balanced improvement: execution time drops by roughly 35 % on a CPU‑only platform and by up to 45 % on a GPU where FP32 throughput is 3–4× higher, while the relative error stays below 10⁻⁶, essentially indistinguishable from the double‑precision baseline. The intermediate‑compression method achieves the largest memory savings (≈40 % reduction) but incurs a slight slowdown in convergence for the most ill‑conditioned cases, leading to a net time reduction of about 20 – 30 %. The iterative‑solver variant is the most conservative; it preserves the exact convergence pattern of the FP64 solver but still cuts arithmetic operations by ≈20 % because the preconditioner and residual updates dominate the cost in many BEM applications.
A detailed error‑propagation analysis confirms that the dominant source of numerical error originates from the low‑rank block approximations themselves; the additional rounding introduced by FP32 arithmetic remains well below this intrinsic approximation error for the tested tolerances. The authors also discuss hardware implications: on GPUs with tensor cores that accelerate FP16/FP32 matrix‑vector products, the proposed schemes could be extended to even lower precisions, provided a robust error‑control strategy is in place.
In the discussion, the authors compare their mixed‑precision H‑matrix approach with other acceleration techniques such as GPU‑native H‑matrix kernels, hierarchical off‑diagonal low‑rank (HODLR) methods, and fast multipole methods (FMM). They argue that mixed precision is complementary rather than competitive: it can be layered on top of any of these algorithms to extract additional speedups without redesigning the core mathematical framework.
The paper concludes that mixed‑precision computing is a practical and effective tool for reducing both runtime and memory footprints of H‑matrix‑based BEM simulations. By carefully selecting where FP32 can replace FP64—either at the block level, during intermediate storage, or within the iterative solver—engineers can achieve substantial performance gains while maintaining the high accuracy required for scientific and engineering analyses. Future work is outlined, including automated precision‑selection heuristics, extension to H²‑matrices, and integration with emerging hardware accelerators that support mixed‑precision arithmetic natively.
Comments & Academic Discussion
Loading comments...
Leave a Comment