From feature selection to continuous optimization
Metaheuristic algorithms (MAs) have seen unprecedented growth thanks to their successful applications in fields including engineering and health sciences. In this work, we investigate the use of a deep learning (DL) model as an alternative tool to do…
Authors: Hojjat Rakhshani, Lhassane Idoumghar, Julien Lepagnot
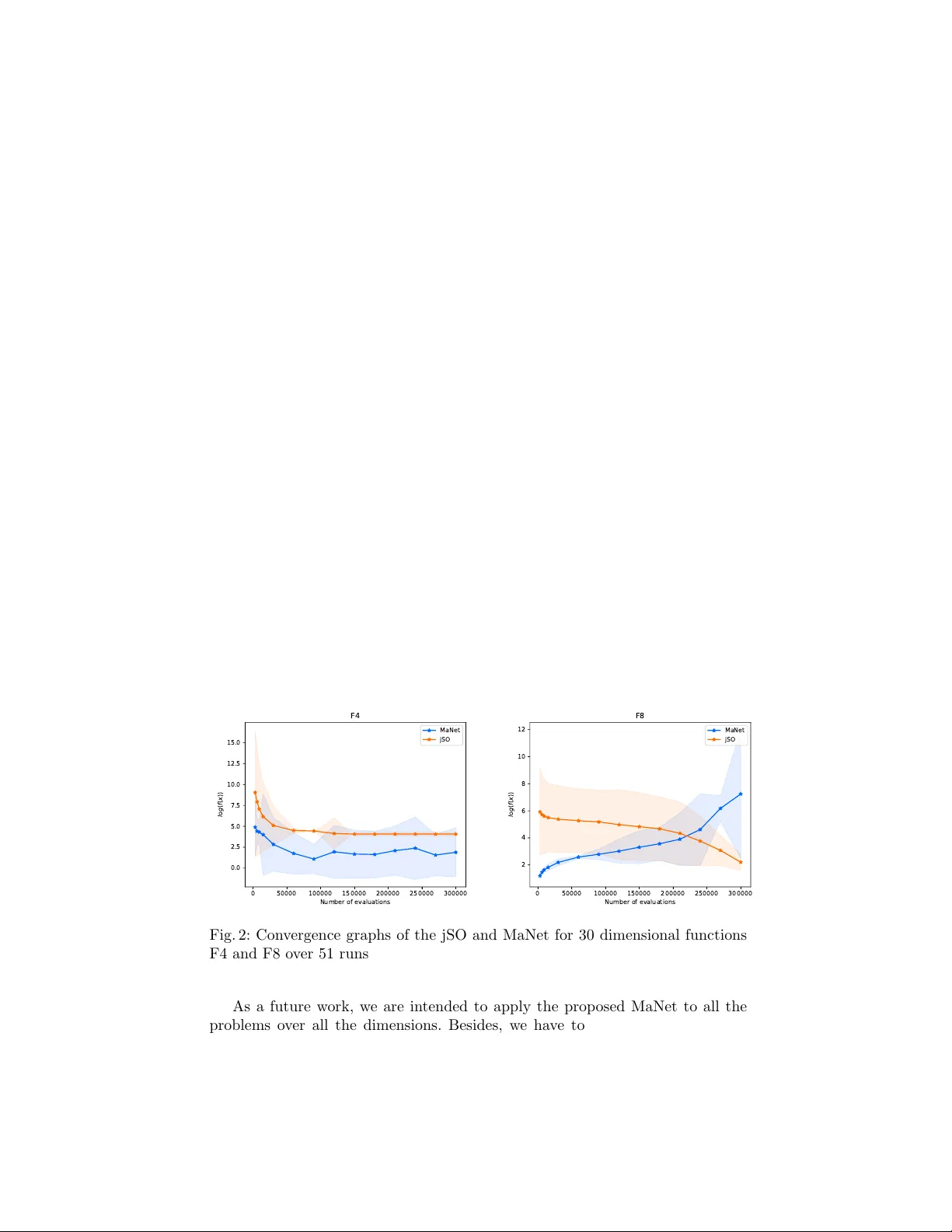
F rom feature selection to con tin uous optimization Ho jjat Rakhshani, Lhassane Idoumghar, Julien Lepagnot, and Mathieu Br ´ evilliers Univ ersit´ e de Haute-Alsace, IRIMAS-UHA, F-68093 Mulhouse, F rance Abstract. Metaheuristic algorithms (MAs) ha ve seen unpreceden ted gro wth thanks to their successful applications in fields including engi- neering and health sciences. In this w ork, we in vestigate the use of a deep learning (DL) model as an alternative to ol to do so. The proposed metho d, called MaNet, is motiv ated by the fact that most of the DL mo dels often need to solv e massiv e nasty optimization problems con- sisting of millions of parameters. F eature selection is the main adopted concepts in MaNet that helps the algorithm to skip irrelev an t or partially relev ant evolutionary information and uses those which con tribute most to the ov erall p erformance. The in tro duced mo del is applied on sev eral unimo dal and m ultimo dal con tinuous problems. The exp eriments indi- cate that MaNet is able to yield comp etitive results compared to one of the b est hand-designed algorithms for the aforemen tioned problems, in terms of the solution accuracy and scalability . Keyw ords: Metaheuristics · deep learning · con tinuous optimization. 1 In tro duction The need for optimization has receiv ed a lot of atten tion in different application areas. F ormally , optimization algorithms seek to find a parameter v ector x ∗ so as to minimize a cost function f ( x ) : R D → R , i.e. f ( x ∗ ) ≤ f ( x ) for all x ∈ Ω , where Ω = R D is the search domain and D is the dimension of the problem. There are no a prior hypothesis ab out f and optimization algorithms should treat them as blac k-b ox functions. This motiv ated the dev elopment of MAs whic h do not take adv antages of problem structure. MAs are one of the fastest gro wing fields aimed at solving differen t complex and highly non-linear real-w orld problems by inspiration from the pro cess of nat- ural evolution or ph ysical pro ce sses [18,9]. In MAs, w e often ha ve a population of candidate solutions that strive for surviv al and repro duction. In ev ery itera- tion, different search op erators are applied to the candidate solutions and then the p opulation will b e up dated based on its success in achieving the goal. Over the last decade, there has b een an explosion in the dev elopment of a v ariet y of extensions to further enhance the p erformance of MAs. How ever, there are no clear guidelines on the strengths and w eaknesses of alternative metho ds such as the DL mo dels for developing more enhanced optimization algorithms. 2 H. Rakhshani et al. The DL approac hes use a hierarch y of features in conjunction with several la yers to learn complex non-linear mappings betw een the input and output la y er. As opp osite to traditional machine learning metho ds that use handmade fea- tures, the important features are discov ered automatically and are represented hierarc hically . This is known to b e the strong p oint of DL against traditional mac hine learning approaches. Accordingly , these mo dels hav e b een describ ed as universal learning approaches that are not task sp ecific and can be used to tac kle different problems arise in differen t research domains [1]. In this work, w e propose a simple, yet effective approach for n umerical optimization based on the DL. The prop osed MaNet adopts a Conv olutional Neural Net w ork (CNN); whic h are regularized version of fully-connected neural net works inspired from biological visual systems [12]. The ”fully-connectedness” of CNNs enables them to tac kle the o ver-fitting problem and it is reasonable to postulate that they ma y outp erform classical neural netw orks for difficult optimization tasks. The rest of the pap er is organized as follows. Section 2 presents a review on the related works and describes our motiv ations. In Section 3, we elab orate tec hnical details of the MaNet approac h. In Section 4, a series of experiments are conducted to show the performance of the in tro duced metho d. The last section summarizes the pap er and draws conclusions. 2 Related w orks and motiv ations The idea of solving optimization problems using neural netw orks has an old his- tory whic h has seen a num b er of adv ances in recent years [10,23,2,3,14]. In [23], authors developed a Ba y esian optimization method, called as DNGO, based on deep neural netw orks for hyperparameter tuning of large scale problems with exp ensiv e ev aluation. The main idea is to combine large-scale parallelism with an optimization metho d to pro vide an appro ximate model of the real cost func- tion. They sho w that DNGO scales in a less dramatic fashion compared to the Gaussian pro cess, while maintains its desirable flexibility and c haracterization of uncertaint y . OptNet [2] is another metho d prop osed for learning optimization tasks b y the virtues of DL, sensitivity analysis, bilev el optimization, and implicit differen tiation. The authors highlighted the p otential p o wer of OptNet netw orks against existing netw orks to play mini-Sudoku. In [3], researc hers in vestigated automating the design of an optimization algorithm b y Long short-term mem- ory deep netw orks on a n um b er of tasks. Their results outperform hand-designed comp etitors for simple conv ex problems, neural netw ork training and styling im- ages with neural art. Similarly , Li and Malik [14] put forw ard a deep learning metho d for automating algorithm design pro cess. They formulate the problem as a reinforcement learning task according to whic h any candidate algorithm is represen ted b y a policy and the goal is to find an optimal p olicy . T o verify this finding, the authors conducted a set of experiments using different conv ex and non-con vex loss functions correspond to several machine learning mo dels. The obtained results clearly suggest that the automatically designed optimizer con verges faster compared to hand-engineered optimizer. F rom feature selection to con tinuous optimization 3 Some of the ab ov e men tioned works mainly aim at pro viding optimal solu- tions within a very limited computational time [23], while others [3,14] primarily fo cus on getting better heuristic solutions. These success stories of DL motiv ated us to in vestigate the ability of a mo derate model so as to make a balance b e- t ween the solution accuracy and computational time. Altogether, these are the same desired prop erties in MAs and our work is a step tow ards inv estigating the usefulness and strong p otential of this research direction. 3 The prop osed metho d This section presents a new optimization method, called MaNet, to explore the p ossibilit y of adopting a light weigh t deep learning architecture for con tinuous optimization tasks. In the following, it is assumed that the reader is familiar with the basic concepts of evolutionary computation and deep neural netw orks. The MaNet is designed to hav e the common prop erties of the MAs: pro- viding a sufficient goo d solution with incomplete or imp erfect information. It starts the optimization pro cedure with a set of randomly generated solutions as genot yp e. During training the netw ork, MaNet applies the netw ork training comp onen ts directly on the genot yp e, while deco des a genot yp e in to a phenotype (i.e., individuals in MAs) only in the last lay er. It finds an optimized solution by iterativ ely impro ving an initial solution with regard to its cost function. Among differen t DL mo dels, CNNs trained with an extension of sto chastic gradient de- scen t is used to build the MaNet. The CNNs ha ve b een cen tral to the largest adv ances in computer vision [12] and sp eech pro cessing [8]. A CNN is a DL metho d that uses con volutional lay ers to filter redundan t or even irrelev ant in- put data to increase the p erformance of the netw ork [7]. This consideration also reduces the dimensionality of the input data and speeds up the learning pro cess in the CNNs. Besides, it allows CNNs to be deep er net works with fewer param- eters. Altogether, these prop erties could mak e CNNs a p otential to ol for solving optimization problems; especially when we take into account the history b ehind the application of feature selection [17] and problem scale reducing [21] in the optimization domain. The architecture of a CNN consists of an input and an output la yer, as w ell as one or more hidden lay ers. The hidden la yers are typically comp osed of con volutional lay ers, fully connected lay ers, normalization la yers and p ooling la yers. The n umber of hidden la yers could be increased dep ending on the com- plexities in the input data, but at the cost of more computational exp ensiv e sim ulations. F rom the mathematical p erspective, conv olution lay ers pro vide a w ay of mixing input data with a filter so as to form a transformed feature map. F ully-Connected lay ers learn non-linear com binations of the high-lev el features b y connecting neurons in one la yer to neurons in the previous la y er, as seen in m ulti-lay er perceptrons neural netw orks (MLPs). Moreov er, normalization lay ers are adopted to normalize the data to a net work and to sp eed up learning. This includes batch normalization [20], weigh t normalization [19], and lay er normal- ization [13] techniques. Batc h normalization is applied to the input data or to 4 H. Rakhshani et al. the activ ation of a prior lay er, weigh t normalization is applied to the w eights of the la yer and lay er normalization is applied across the features. The po oling la yers are usually inserted in-b etw een succe ssiv e con volutional la yers to further reduce the n umber of parameters in the netw ork. A CNN net work can ha ve local or global p o oling lay ers that may compute a max or an a verage. Inspired by the aforemen tioned comp onents in CNNs, the MaNet is designed to train a mo del so as to solve an optimization problem (Fig. 1). The existing feature selection and dimensionality reduction p olicies in CNNs help MaNet to find complex dep endencies b etw een the parameters. The MaNet start optimiza- tion b y generating a set of random n × m inputs for the mo del (i.e., the raw pixel v alues of the image). So, eac h individual solution is represen ted b y a matrix rather than a vector. During training the netw ork, con volutional lay ers trans- form the initial p opulation lay er b y lay er to a final feasible solution. This large part genotype representation enables the optimizer to keep genetic information that w as necessary in the past as a source of exploration, as w ell as a pla yground for extracting new features that can b e adv antageous in the exploitation. The MaNet multiplies the initial p opulation with a t wo-dimensional arra y of filters that are connected to every disjoin t region. The output of multiplying the filters with initial p opulation forms a tw o-dimensional output arra y called as ”feature map”. They are obtained by conv olution process upon the initial p op- ulation with a linear filter, without applying a non-linear function or applying feature normalization methods. Similar to other DL mo dels, the filters/k ernels in MaNet are learned using the back-propagation algorithm for each sp ecific op- timization task. This is the nov el asp ect of DL tec hniques that filter w eights are learned during the training of the netw ork and are not hand designed. Accord- ingly , CNNs are not limited to image data and could b e used to extract a v ariety t yp es of features. Thank to this characteristic, MaNet will be forced to extract the features that are the most important to minimize the loss function for the problem at hand the net work is b eing trained to solve. In each con volution la yer, w e ha ve some predefined h yp erparameters that can b e used to modify the b e- ha vior of the mo del: the filter size and the num b er of filters. The first one simply denotes the dimensions of the filter when applying the con volution pro cess, while the second one determines the n umber of different con volution filters. In MaNet, m ultiple con volution la yers are stac ked whic h allo ws con volution la yers to be applied to the output of the previous la yer, results in a hierarc hically set of more decomposed features. Finally , a Dense la y er (or fully-connected) with linear activ ation function will b e used to form the final solution vector. As it can b e seen from Fig. 1, MaNet has a very simple structure and can b enefit from the adv antage of ha ving a fast netw ork training pro cess 1 . Indeed, it has only 3,742 trainable parameters compared to state-of-the-art mo dels [22] which ha ve millions or billions of parameters. This could facilitate the application of MaNet for optimization tasks where a small amount of data (i.e., population) is a v ailable. 1 Netron Visualizer is used to illustrate the mo del. The tools is av ailable online at: h ttps://github.com/lutzroeder/netron F rom feature selection to con tinuous optimization 5 A dam batc h size <1 > A dam batc h size <6 4> trainin g the n etwork stagna tion ana lysis voting yes no initial population intr oduced a r chitec tur e module optimization module ?×64×1 C on v1D k ernel 〈 3×1 ×6 〉 bias 〈 6 〉 C on v1D k ernel 〈 3×6 ×6 〉 bias 〈 6 〉 C on v1D k ernel 〈 3×6 ×6 〉 bias 〈 6 〉 Flatt en Dense k ernel 〈 348 ×10 〉 bias 〈 10 〉 input _1 dense_1 ?×64×1 C on v1D k ernel 〈 3×1 ×6 〉 bias 〈 6 〉 C on v1D k ernel 〈 3×6 ×6 〉 bias 〈 6 〉 C on v1D k ernel 〈 3×6 ×6 〉 bias 〈 6 〉 Flatt en Dense k ernel 〈 348 ×10 〉 bias 〈 10 〉 input _1 dense_1 one n x m individual solution in MaNet Fig. 1: An ov erview of the prop osed optimization architecture. The MaNet is comp osed of three con volution lay ers and one Dense lay er (or fully connected la yer). In eac h lay er, the n umber of filters and the filter size are 6 and 3, resp ec- tiv ely . The activ ation function for all the lay ers is prop ortional to their inputs. As it can b e seen, the MaNet is comp osed of t wo similar arc hitectures which are sub jected to different optimization procedures. The first one uses a batch size of one and the other uses 64 as its batch size. The batc h size is a h yp e rparameter of gradien t descent that should b e tuned for eac h optimization task. T o do so, MaNet integrates a reinforcement strategy inspired from SDCS [18]. T ec hnically sp eaking, SDCS is a simple metaheuristic algorithm whic h toggles con tinually b et ween t wo snap and drift mo des to enhance reinforcemen t and stability . Based on this idea, MaNet in tro duces a self-adaptive strategy to tune the batch size h yp erparameter. More precisely , it is lo oking to see if the b est cost function stops 6 H. Rakhshani et al. impro ving after some num b er of ep o chs, and if so then it restarts the optimization pro cess and contin uous the searc h b y the architecture whic h obtained a higher o verall performance so far. Finally , it is w orth mentioning to note that the initial p opulation will remain unchanged during training the net work and the algorithm will evolv e a set of filters. The goal of MaNet then, is to transfer the initial p opulation on one end to evolv ed solutions on the other hand. This is one of the main differences b etw een MaNet and evolutionary algorithms. 4 Exp erimen tal 4.1 Exp erimen tal setup W e use a set of 9 b enc hmark functions giv en in CEC 2017 [20] to ev aluate the p erformance of the prop osed algorithm 2 . The considered problems are widely used in the optimization communit y and are c hallenging for any optimization approac h. This w ork uses several problems that can be classified into unimo dal (F1 and F3) and multimodal (F4-10) minimization fu nctions with different prop- erties including separable, non-separable, rotated, ill-condition and shifted 3 . The aforemen tioned problems are adopted on the GPU so as to b e link ed with ma- c hine learning libraries. W e refer the reader to the detailed principle ab out the definition of CEC2017 b enc hmark functions as defined in [4]. T o verify the al- gorithm scalabilit y , 30-dimensional and 50-dimensional problems are used. All functions should b e minimized and hav e a global minimum at f ( x ) = 0. The results are rep orted according to their distance from the optimum. W e trained MaNet on each problem by using the parallel p ow er of 9 NVIDIA T esla K20m GPU cards. It has b een shown that v arious extensions of the differential evolution (DE) [24] algorithm are alwa ys among the winners of the CEC competition. Having this is mind, w e used jSO [6] algorithm for the purpose of comparison whic h is the second ranked algorithm in CEC2017 comp etitions for the single ob jectiv e opti- mization trac k. The algorithm is sho wn to outperform LSHADE [26] (the winner of the CEC2014) and its new extension for CEC2016 (iL-SHADE [5]). All the results are tak en from the original study . In order to mak e a fair comparison, all the exp eriment conditions are the same. The num b er of function ev aluations is 10 , 000 × D , where D is the problem dimension [4]. T o tackle the negative effects of the random initial configurations, eac h algorithm were run 51 times [4]. The initial population is generated randomly within the searc h b ounds [ − 100 , 100]. The parameters of the jSO are the same as rep orted in the original study [6]. In MaNet, w e hav e 3 con volution lay ers whic h are sequentially connected to eac h other. In each la yer, the num b er of filters and the filter size are 6 and 3, resp ectiv ely . The MaNet is a CNN mo del and needs a lot of input data to b e 2 The co des for CEC problems and the jSO algorithm are publicly a v ailable at: h ttp://www.ntu.edu.sg/home/EPNSugan/index files/CEC2017/CEC2017.h tm 3 F2 has been excluded by the organizers because it shows unstable behavior esp ecially for higher dimensions [4] F rom feature selection to con tinuous optimization 7 w ell trained and so the p opulation size is fixed to n = 5 , 000. Moreo ver, m is considered to b e 64 for all the problems. The MaNet will b e optimized using the Adam algorithm [11]. 4.2 Results and discussion T ables 1-2 present best, w orst, mean and standard deviation (Std.) results of the MaNet and jSO on 9 problems o ver 51 runs. T able 1 reports the results for 30 dimensional problems, while T able 2 sho ws the p erformance of the comp etitive algorithms for 50 dimensional cases. In these tables, a statistical test is also presen ted to assess the significance of p erformance b etw een the results of the jSO and MaNet. T able 1: The obtained results by MaNet and jSO for 30 dimensional problems o ver 51 runs [4]. The results for jSO are directly tak en from the original pap er [6]. F unction Algorithm Best W orst Mean Median Std. Sign 1 MaNet 3 . 71 e + 02 1 . 33 e + 03 7 . 94 e + 02 8 . 02 e + 02 2 . 03 e + 02 − jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 3 MaNet 3 . 69 e + 04 7 . 10 e + 04 5 . 85 e + 04 5 . 85 e + 04 6 . 46 e + 03 − jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 4 MaNet 1 . 46 e − 05 3 . 99 e + 00 5.88e-01 6 . 79 e − 04 1 . 41 e + 00 + jSO 5 . 86 e + 01 6 . 41 e + 01 5 . 87 e + 01 5 . 86 e + 01 7 . 78 e − 01 5 MaNet 0 . 00 e + 00 1 . 99 e + 00 5.85e-01 1 . 34 e − 07 6 . 59 e − 01 + jSO 3 . 98 e + 00 1 . 32 e + 01 8 . 56 e + 00 8 . 02 e + 00 2 . 10 e + 00 6 MaNet 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 = jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 7 MaNet 3 . 26 e + 01 3 . 41 e + 01 3.33e+01 3 . 33 e + 01 3 . 91 e − 01 + jSO 3 . 61 e + 01 4 . 31 e + 01 3 . 89 e + 01 3 . 91 e + 01 1 . 46 e + 00 8 MaNet 0 . 00 e + 00 4 . 97 e + 00 2.29e+00 1 . 99 e + 00 1 . 15 e + 00 + jSO 4 . 97 e + 00 1 . 30 e + 01 9 . 09 e + 00 8 . 96 e + 00 1 . 84 e + 00 9 MaNet 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 = jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 10 MaNet 1 . 09 e + 04 1 . 13 e + 04 1 . 11 e + 04 1 . 11 e + 04 1 . 19 e + 02 − jSO 1 . 04 e + 03 2 . 04 e + 03 1.53e+03 1 . 49 e + 03 2 . 77 e + 02 T able 2: The obtained results by MaNet and jSO for 50 dimensional problems o ver 51 runs [4]. The results for jSO are directly tak en from the original pap er [6]. F unction Algorithm Best W orst Mean Median Std. Sign 1 MaNet 3 . 67 e + 02 2 . 06 e + 03 1 . 39 e + 03 1 . 46 e + 03 3 . 71 e + 02 − jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 3 MaNet 9 . 80 e + 04 1 . 42 e + 05 1 . 23 e + 05 1 . 25 e + 05 8 . 88 e + 03 − jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 4 MaNet 3 . 10 e − 06 1 . 53 e − 03 8.22e-04 9 . 96 e − 04 4 . 46 e − 04 + jSO 1 . 32 e − 04 1 . 42 e + 02 5 . 62 e + 01 2 . 85 e + 01 4 . 88 e + 01 5 MaNet 1 . 99 e + 00 1 . 09 e + 01 6.15e+00 5 . 97 e + 00 2 . 20 e + 00 + jSO 8 . 96 e + 00 2 . 39 e + 01 1 . 64 e + 01 1 . 62 e + 01 3 . 46 e + 00 6 MaNet 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 = jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 7 MaNet 5 . 49 e + 01 5 . 65 e + 01 5.58e+01 5 . 59 e + 01 3 . 62 e − 01 + jSO 5 . 75 e + 01 7 . 42 e + 01 6 . 65 e + 01 6 . 66 e + 01 3 . 47 e + 00 8 MaNet 1 . 99 e + 00 8 . 95 e + 00 5.41e+00 5 . 97 e + 00 1 . 99 e + 00 + jSO 9 . 95 e + 00 2 . 41 e + 01 1 . 70 e + 01 1 . 70 e + 01 3 . 14 e + 00 9 MaNet 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 = jSO 0 . 00 e + 00 0 . 00 e + 00 0.00e+00 0 . 00 e + 00 0 . 00 e + 00 10 MaNet 1 . 86 e + 04 1 . 88 e + 04 1 . 87 e + 04 1 . 87 e + 04 6 . 25 e + 01 − jSO 2 . 40 e + 03 3 . 79 e + 03 3.14e+03 3 . 23 e + 03 3 . 67 e + 02 8 H. Rakhshani et al. The results of the Wilco xon rank sum test are rep orted at the 95% confidence lev el. In these tables, + shows that MaNet significantly outp erforms the jSO with 95% certain ty; - indicates that the jSO is significan tly better than MaNet; and = sho ws there is no statistical different betw een the tw o compared algorithms. The significan t results are given in b old. F or further v alidation, con v ergence graphs of jSO and MaNet for 30 dimensional functions F4 and F8 are given in Fig. 2. As can be seen from T ables 1-2, jSO giv es more accurate solutions for the uni- mo dal benchmarks F1 and F3 for b oth 30-dimensional and 50-dimensional cases. Moreo ver, with the exceptions of F10, MaNet has equal or significantly better p erformance on all the multimodal b enchmark functions. In fact, the results indicate that MaNet significantly outp erforms the jSO on 4 functions (F4-F8), obtains an equal p erformance on 2 functions (F6 and F9), and has w orst results on 3 test cases (F1, F3 and F10). F urthermore, we can see that MaNet is a ro- bust algorithm according to the rep orted standard deviation results. In addition, these exp erimental results ha ve confirmed that MaNet is not very sensitive to the increment of dimension and is scalable. Considering Fig. 2, it can b e seen also that MaNet has a more rapid conv ergence rate than the jSO algorithm for function F4 and F8. In MaNet, w e assume that not selection, but rather the com bination of different filters is the main source of evolution and that is the reason for ha ving unstable conv ergence b ehavior on these functions. Altogether, these promising results hav e confirmed that MaNet has a com- p etitiv e results in comparison with one of the best designed algorithm for the CEC2017 problems. This is quite interesting b ecause MaNet do esn’t b orrow an y searc h strategy or comp onents from the previously prop osed metho ds for the CEC problems; including CMAES [15], DE, jADE [27], SADE [16], SHADE [25], L-SHADE [26], i-LSHADE [5] and jSO. 0 50000 100000 150000 200000 250000 300000 Number of evaluations 0.0 2.5 5.0 7.5 10.0 12.5 15.0 l o g ( f ( x ) ) F4 MaNet jSO 0 50000 100000 150000 200000 250000 300000 Number of evaluations 2 4 6 8 10 12 l o g ( f ( x ) ) F8 MaNet jSO Fig. 2: Conv ergence graphs of the jSO and MaNet for 30 dimensional functions F4 and F8 o ver 51 runs As a future work, w e are intended to apply the prop osed MaNet to all the problems ov er all the dimensions. Besides, we hav e to find a wa y in order to F rom feature selection to con tinuous optimization 9 adjust the learning rate hyperparameter for each problem. F rom Fig. 2 one can see that a high learning rate in Adam causes the net work to generate large n umbers for F8 and the up dates are going to be just as large. After that, w e w ould like to apply the prop osed metho dology to more complicated real-world optimization problems. 5 Conclusion This study prop osed a new optimization algorithm based on the DL in order to pro vide an impro ved searc h process. The proposed method v erifies conv ergence conditions b y using a CNN model. The simple structure of the MaNet along with feature selection and dimension reduction strategies result in an arc hitecture at a relatively low computational cost. The MaNet optimizer is ev aluated using unimo dal and multimodal optimization b enchmarks from CEC2017 test suite. The obtained results are statistically analyzed and compared with state-of-the- art jSO algorithm. Ev aluations confirm that the introduced MaNet optimization mo del has a comp etitive p erformance in terms of the final solution accuracy and scalabilit y compared to one of the b est designed algorithms for the problem at hand. Ac kno wledgments This research w as supp orted through computational resources pro vided b y M´ esocentre of Strasb ourg: h ttps://services-numeriques.unistra.fr/ References 1. Alom, M.Z., T aha, T.M., Y akopcic, C., W estb erg, S., Sidike, P ., Nasrin, M.S., V an Esesn, B.C., Aww al, A.A.S., Asari, V.K.: The history b egan from alexnet: a comprehensiv e survey on deep learning approaches. arXiv preprint arXiv:1803.01164 (2018) 2. Amos, B., Kolter, J.Z.: Optnet: Differentiable optimization as a la yer in neural net- w orks. In: Pro ceedings of the 34th International Conference on Machine Learning- V olume 70. pp. 136–145. JMLR. org (2017) 3. Andryc howicz, M., Denil, M., Gomez, S., Hoffman, M.W., Pfau, D., Schaul, T., Shillingford, B., De F reitas, N.: Learning to learn by gradient descent by gradient descen t. In: Adv ances in Neural Information Pro cessing Systems. pp. 3981–3989 (2016) 4. Aw ad, N., Ali, M., Liang, J., Qu, B., Suganthan, P .: Problem definitions and ev al- uation criteria for the cec 2017 sp ecial session and comp etition on single ob jectiv e real-parameter numerical optimization. T ech. Rep. (2016) 5. Brest, J., Mau ˇ cec, M.S., Bo ˇ sk ovi ´ c, B.: il-shade: Impro ved l-shade algorithm for sin- gle ob jective real-parameter optimization. In: 2016 IEEE Congress on Ev olutionary Computation (CEC). pp. 1188–1195. IEEE (2016) 10 H. Rakhshani et al. 6. Brest, J., Mauˇ cec, M.S., Bo ˇ sko vi ´ c, B.: Single ob jective real-parameter optimization: Algorithm jso. In: 2017 IEEE congress on ev olutionary computation (CEC). pp. 1311–1318. IEEE (2017) 7. He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Pro ceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016) 8. Hin ton, G., Deng, L., Y u, D., Dahl, G., rahman Mohamed, A., Jaitly , N., Senior, A., V anhouck e, V., Nguy en, P ., Sainath, T., Kingsbury , B.: Deep neural netw orks for acoustic modeling in sp eech recognition. Signal Pro cessing Magazine (2012) 9. Kang, K., Bae, C., Y eung, H.W.F., Chung, Y.Y.: A hybrid gravitational search al- gorithm with sw arm intelligence and deep conv olutional feature for ob ject trac king optimization. Applied Soft Computing 66 , 319–329 (2018) 10. Kennedy , M.P ., Ch ua, L.O.: Neural netw orks for nonlinear programming. IEEE T ransactions on Circuits and Systems 35 (5), 554–562 (1988) 11. Kingma, D.P ., Ba, J.: Adam: A metho d for sto chastic optimization. arXiv preprint arXiv:1412.6980 (2014) 12. Krizhevsky , A., Sutskev er, I., Hinton, G.E.: Imagenet classification with deep con- v olutional neural net works. In: Adv ances in neural information pro cessing systems. pp. 1097–1105 (2012) 13. Lei Ba, J., Kiros, J.R., Hin ton, G.E.: Lay er normalization. arXiv preprin t arXiv:1607.06450 (2016) 14. Li, K., Malik, J.: Learning to optimize. arXiv preprin t arXiv:1606.01885 (2016) 15. Loshc hilov, I.: Cma-es with restarts for solving cec 2013 b enchmark problems. In: 2013 IEEE Congress on Evolutionary Computation. pp. 369–376. Ieee (2013) 16. Qin, A.K., Sugan than, P .N.: Self-adaptive differential evolution algorithm for nu- merical optimization. In: 2005 IEEE congress on evolutionary computation. vol. 2, pp. 1785–1791. IEEE (2005) 17. Rakhshani, H., Idoumghar, L., Lepagnot, J., Br´ evilliers, M.: Mac: Many-ob jective automatic algorithm configuration. In: International Conference on Evolutionary Multi-Criterion Optimization. pp. 241–253. Springer (2019) 18. Rakhshani, H., Rahati, A.: Snap-drift cuc koo search: A nov el cuck o o searc h opti- mization algorithm. Applied Soft Computing 52 , 771–794 (2017) 19. Salimans, T., Kingma, D.P .: W eigh t normalization: A simple reparameterization to accelerate training of deep neural netw orks. In: Adv ances in Neural Information Pro cessing Systems. pp. 901–909 (2016) 20. San turk ar, S., Tsipras, D., Ily as, A., Madry , A.: Ho w do es batch normalization help optimization? In: Adv ances in Neural Information Pro cessing Systems. pp. 2483–2493 (2018) 21. Senjyu, T., Sab er, A., Miyagi, T., Shimabukuro, K., Urasaki, N., F unabashi, T.: F ast technique for unit commitment by genetic algorithm based on unit cluster- ing. IEE Pro ceedings-Generation, T ransmission and Distribution 152 (5), 705–713 (2005) 22. Simon yan, K., Zisserman, A.: V ery deep conv olutional netw orks for large-scale image recognition. arXiv preprin t arXiv:1409.1556 (2014) 23. Sno ek, J., Ripp el, O., Sw ersky , K., Kiros, R., Satish, N., Sundaram, N., P atw ary , M., Prabhat, M., Adams, R.: Scalable ba yesian optimization using deep neural net works. In: International conference on mac hine learning. pp. 2171–2180 (2015) 24. Storn, R., Price, K.: Differen tial evolution–a simple and efficien t heuristic for global optimization o v er con tinuous spaces. Journal of global optimization 11 (4), 341–359 (1997) F rom feature selection to con tinuous optimization 11 25. T anab e, R., F ukunaga, A.: Success-history based parameter adaptation for differ- en tial ev olution. In: 2013 IEEE congress on evolutionary computation. pp. 71–78. IEEE (2013) 26. T anab e, R., F ukunaga, A.S.: Impro ving the search p erformance of shade using lin- ear population size reduction. In: 2014 IEEE congress on ev olutionary computation (CEC). pp. 1658–1665. IEEE (2014) 27. Zhang, J., Sanderson, A.C.: Jade: adaptive differential evolution with optional external archiv e. IEEE T ransactions on ev olutionary computation 13 (5), 945–958 (2009)
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment