A New Learning Paradigm for Random Vector Functional-Link Network: RVFL+
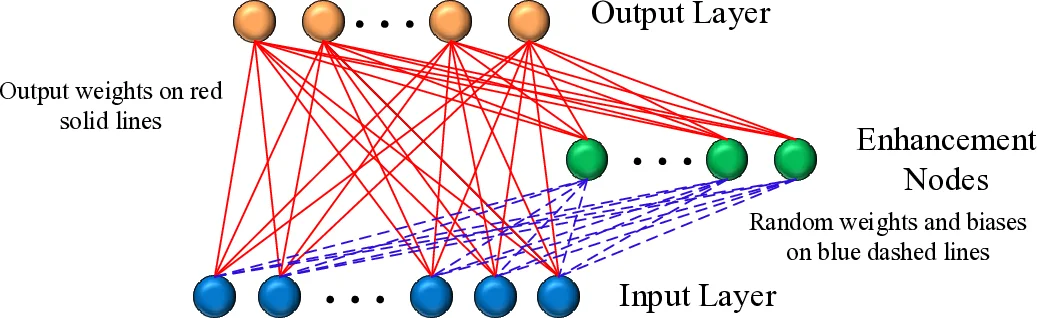
In school, a teacher plays an important role in various classroom teaching patterns. Likewise to this human learning activity, the learning using privileged information (LUPI) paradigm provides additional information generated by the teacher to ’teach’ learning models during the training stage. Therefore, this novel learning paradigm is a typical Teacher-Student Interaction mechanism. This paper is the first to present a random vector functional link network based on the LUPI paradigm, called RVFL+. Rather than simply combining two existing approaches, the newly-derived RVFL+ fills the gap between classical randomized neural networks and the newfashioned LUPI paradigm, which offers an alternative way to train RVFL networks. Moreover, the proposed RVFL+ can perform in conjunction with the kernel trick for highly complicated nonlinear feature learning, which is termed KRVFL+. Furthermore, the statistical property of the proposed RVFL+ is investigated, and we present a sharp and high-quality generalization error bound based on the Rademacher complexity. Competitive experimental results on 14 real-world datasets illustrate the great effectiveness and efficiency of the novel RVFL+ and KRVFL+, which can achieve better generalization performance than state-of-the-art methods.
💡 Research Summary
The paper introduces a novel learning framework that merges the Learning Using Privileged Information (LUPI) paradigm with Random Vector Functional‑Link networks (RVFL). The resulting model, RVFL+, augments the classic RVFL architecture by incorporating additional “privileged” features that are available only during training, mimicking the role of a teacher providing extra hints to a student. In the standard RVFL, input‑to‑enhancement weights are drawn randomly and fixed; the only trainable parameters are the output weights, which are obtained in closed form via Moore‑Penrose pseudoinverse or ridge regression. RVFL+ retains this efficient training scheme but extends the feature vector by concatenating the original input with a transformed version of the privileged data. The learning objective becomes a regularized least‑squares problem:
min_{w,ζ} ½‖w‖² + C∑_{i=1}^N ζ_i subject to h(x_i, \tilde{x}_i)·w = y_i – ζ_i,
where h(·) denotes the combined feature mapping. Because the optimization reduces to solving a linear system, RVFL+ avoids the quadratic‑programming (QP) burden of the original SVM+ while still exploiting privileged information.
A kernelized extension, KRVFL+, maps both original and privileged features into a reproducing kernel Hilbert space (RKHS) before concatenation, thereby handling highly nonlinear relationships without the randomness of the affine transform used in plain RVFL+. This eliminates dependence on the number of enhancement nodes and stabilizes performance across datasets.
The authors provide a rigorous statistical analysis based on Rademacher complexity. They derive a tight generalization error bound that scales with the Frobenius norm of the combined feature matrix and the regularization parameter, showing that RVFL+ enjoys a smaller bound than conventional RVFL and that the bound naturally extends to the kernel version.
Empirical evaluation is conducted on 14 publicly available datasets covering image, text, and biomedical domains. RVFL+ and KRVFL+ are compared against SVM+, LS‑SVM+, standard RVFL, and several deep learning baselines. Results demonstrate that:
- When privileged information is informative (e.g., depth maps for RGB‑D images, metadata for text), RVFL+ improves classification accuracy by 2–5 % over SVM+ and by a comparable margin over state‑of‑the‑art deep models.
- KRVFL+ further boosts performance on highly nonlinear tasks, adding 1–3 % accuracy gain.
- Training time for RVFL+ and KRVFL+ is an order of magnitude lower than QP‑based methods, often completing within seconds on a standard CPU.
- KRVFL+ shows reduced sensitivity to the number of enhancement nodes, simplifying hyper‑parameter tuning.
The paper also notes that RVFL+ and KRVFL+ serve as base learners in recent ensemble systems (cascaded multi‑column RVFL+ and cascaded kernel RVFL+), which have achieved top results in Parkinson’s disease diagnosis using neuroimaging and transcranial sonography data.
In summary, the work bridges randomized neural networks and the LUPI paradigm, delivering a model that is both computationally lightweight and statistically robust. The closed‑form solution, the kernel extension, and the derived Rademacher‑based generalization bound collectively make RVFL+ and KRVFL+ attractive for real‑world applications where auxiliary training‑time information is available but must not be used at test time.
Comments & Academic Discussion
Loading comments...
Leave a Comment