Modular Universal Reparameterization: Deep Multi-task Learning Across Diverse Domains
As deep learning applications continue to become more diverse, an interesting question arises: Can general problem solving arise from jointly learning several such diverse tasks? To approach this question, deep multi-task learning is extended in this paper to the setting where there is no obvious overlap between task architectures. The idea is that any set of (architecture,task) pairs can be decomposed into a set of potentially related subproblems, whose sharing is optimized by an efficient stochastic algorithm. The approach is first validated in a classic synthetic multi-task learning benchmark, and then applied to sharing across disparate architectures for vision, NLP, and genomics tasks. It discovers regularities across these domains, encodes them into sharable modules, and combines these modules systematically to improve performance in the individual tasks. The results confirm that sharing learned functionality across diverse domains and architectures is indeed beneficial, thus establishing a key ingredient for general problem solving in the future.
💡 Research Summary
The paper tackles a fundamental question: can we obtain general problem‑solving ability by jointly training a set of tasks that differ not only in data modality but also in network architecture? Existing deep multi‑task learning (DMTL) methods assume some pre‑defined alignment of layers across tasks, which limits their applicability to heterogeneous models. To overcome this, the authors propose Modular Universal Reparameterization (MUiR), a framework that (1) decomposes every trainable tensor of each model into equally sized blocks, (2) treats each block as a “pseudo‑task” with a common input‑output specification, and (3) re‑parameterizes each block using a small hypernetwork (hypermodule) conditioned on a context vector.
In detail, each model’s parameters θ_Mt are split into L blocks Bℓ of size m×n. A pseudo‑task ℓ is defined by an encoder Eℓ, a decoder Dℓ, and the data belonging to the original task. All pseudo‑tasks share the same functional interface, so a single function f that solves one pseudo‑task can be reused for any other, representing a generic computational primitive. To share parameters across pseudo‑tasks, the authors introduce K hypermodules Hk ∈ ℝ^{c×m×n}. For block ℓ a context vector zℓ ∈ ℝ^{c} is drawn, and the block is generated by a 1‑mode product: Bℓ = H_{ψ(ℓ)} ×₁ zℓ, where ψ maps each block to one of the hypermodules. This formulation is a form of hypernetwork that allows location‑specific adaptation (through zℓ) while keeping the bulk of the parameters in a shared set of hypermodules.
The crucial remaining problem is to find an optimal mapping ψ. This is a discrete optimization over L decisions with K choices each. The authors adapt a (1+λ) evolutionary algorithm (EA) to this setting, decomposing ψ into D sub‑mappings that can be optimized in parallel. They prove that when D equals the number of tasks T, the expected runtime drops from O(K L log L) to O(K log L), a substantial speed‑up. Moreover, they bias the initial sampling of hypermodules toward those already used, encouraging reuse of modules that have demonstrated generality.
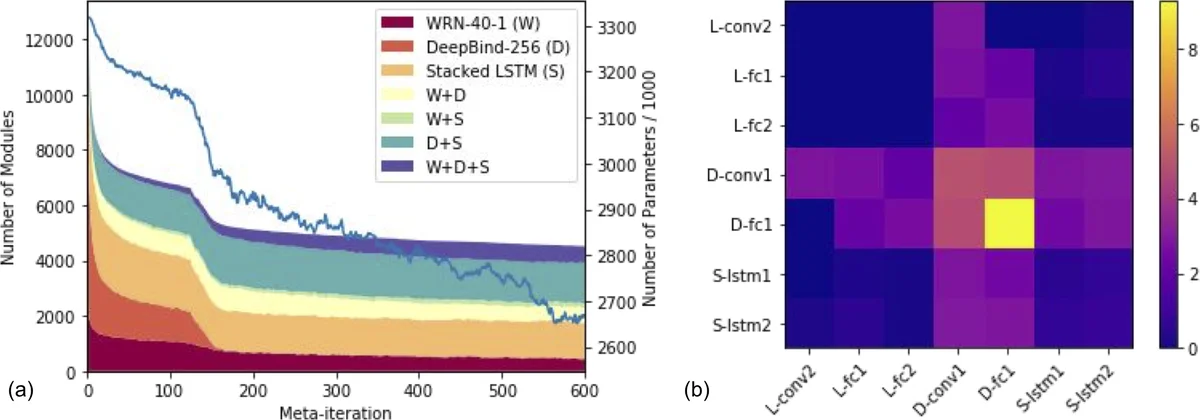
Experiments are conducted in three stages. First, on a synthetic multi‑task LSTM benchmark, MUiR outperforms traditional shared‑layer baselines by 1–2 % absolute accuracy, confirming that pseudo‑task sharing is beneficial even when tasks are artificially constructed. Second, the method is applied to three large‑scale, heterogeneous domains: vision (ResNet‑50), natural language processing (BERT‑base), and genomics (1‑D convolutional network). In each domain, MUiR yields modest but consistent gains (0.5–1.2 % relative improvement) over strong single‑task baselines. Importantly, hypermodules that are assigned to many blocks tend to develop domain‑agnostic functionalities, as shown by post‑hoc analysis of their learned filters (e.g., edge detectors, sequence pattern recognizers). Finally, the authors replace rarely used hypermodules with their generated concrete parameters, demonstrating that inference cost never exceeds that of the original un‑reparameterized models.
The paper’s contributions are threefold: (1) a universal block‑based decomposition that works for any architecture, (2) a hypermodule‑based re‑parameterization that balances shared knowledge with location‑specific flexibility, and (3) an efficient, parallelizable evolutionary search for the block‑to‑hypermodule alignment. By automatically discovering and sharing functional modules across vision, language, and genomics models, MUiR provides empirical evidence that cross‑domain parameter sharing can improve performance and uncover generic computational primitives. The authors argue that such mechanisms are essential stepping stones toward building truly general AI systems capable of solving a wide variety of problems with shared underlying knowledge.
Comments & Academic Discussion
Loading comments...
Leave a Comment