On Automating Conversations
From 2016 to 2018, we developed and deployed Chorus, a system that blends real-time human computation with artificial intelligence (AI) and has real-world, open conversations with users. We took a top-down approach that started with a working crowd-powered system, Chorus, and then created a framework, Evorus, that enables Chorus to automate itself over time. Over our two-year deployment, more than 420 users talked with Chorus, having over 2,200 conversation sessions. This line of work demonstrated how a crowd-powered conversational assistant can be automated over time, and more importantly, how such a system can be deployed to talk with real users to help them with their everyday tasks. This position paper discusses two sets of challenges that we explored during the development and deployment of Chorus and Evorus: the challenges that come from being an “agent” and those that arise from the subset of conversations that are more difficult to automate.
💡 Research Summary
The paper presents a two‑stage research effort that spans from 2016 to 2018, focusing on the design, deployment, and analysis of a crowd‑powered conversational assistant called Chorus and a subsequent framework named Evorus that gradually automates Chorus over time. The authors adopt a “top‑down” methodology: instead of building a fully automated chatbot from scratch, they first launch a working system in which multiple crowd workers propose and vote on responses in real time. This human‑in‑the‑loop architecture supplies high‑quality implicit labels (up‑votes/down‑votes) that can be used to train machine‑learning models for automatic response selection.
System Architecture
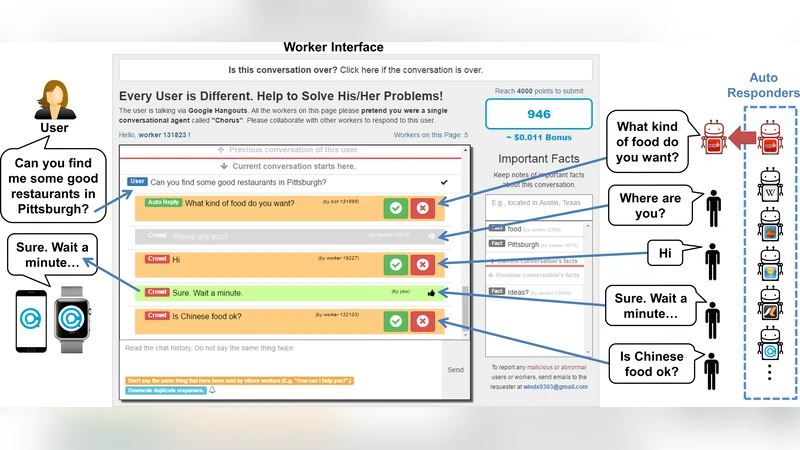
- Chorus: Users type natural‑language queries; a web interface shows candidate replies from a pool of on‑demand crowd workers. Workers up‑vote or down‑vote each candidate; the highest‑voted reply is sent to the user. The voting outcome becomes a quality label for later automation.
- Evorus: Sits on top of Chorus and introduces three sources of automated candidates: (1) domain‑specific task‑oriented bots, (2) general‑purpose chatterbots, and (3) reuse of previously accepted crowd responses. Automated candidates are subjected to the same voting process; when they achieve a predefined positive‑vote threshold they are automatically accepted and stored for future reuse. Over the two‑year deployment, automated replies accounted for 12.44 % of all system replies.
Deployment Statistics
- 420+ distinct users engaged with the system.
- 2,200+ conversation sessions were logged.
- Average per‑session counts: 9.90 user messages, 13.58 crowd messages, 1.93 automated bot messages.
- In a purely crowd‑only baseline, the averages were 8.73 user messages and 12.98 crowd messages, showing that automation modestly increased overall message volume but did not dramatically alter conversation length.
Quality Evaluation
The authors sampled 46 purely crowd‑generated conversations and 54 conversations that contained at least one accepted automated response. Eight Mechanical Turk workers rated each conversation on four dimensions derived from the PARADISE framework and the Quality of Communication Experience metric: Satisfaction, Clarity, Responsiveness, Comfort (5‑point Likert scale). Results:
- Crowd‑only:
Comments & Academic Discussion
Loading comments...
Leave a Comment