Deep Music Analogy Via Latent Representation Disentanglement
Analogy-making is a key method for computer algorithms to generate both natural and creative music pieces. In general, an analogy is made by partially transferring the music abstractions, i.e., high-level representations and their relationships, from one piece to another; however, this procedure requires disentangling music representations, which usually takes little effort for musicians but is non-trivial for computers. Three sub-problems arise: extracting latent representations from the observation, disentangling the representations so that each part has a unique semantic interpretation, and mapping the latent representations back to actual music. In this paper, we contribute an explicitly-constrained variational autoencoder (EC$^2$-VAE) as a unified solution to all three sub-problems. We focus on disentangling the pitch and rhythm representations of 8-beat music clips conditioned on chords. In producing music analogies, this model helps us to realize the imaginary situation of “what if” a piece is composed using a different pitch contour, rhythm pattern, or chord progression by borrowing the representations from other pieces. Finally, we validate the proposed disentanglement method using objective measurements and evaluate the analogy examples by a subjective study.
💡 Research Summary
This paper tackles the problem of generating music by analogy—a process whereby high‑level musical abstractions such as pitch contour, rhythm pattern, and chord progression are transferred from one piece to another while preserving their intrinsic relationships. The authors argue that successful analogy requires three sub‑tasks: (1) extracting latent representations from raw observations, (2) disentangling those representations so that each latent sub‑vector corresponds to a unique semantic factor, and (3) reconstructing actual music from the disentangled latent codes. To address all three simultaneously, they propose an Explicitly‑Constrained Conditional Variational Auto‑Encoder (EC²‑VAE).
Data and Representation
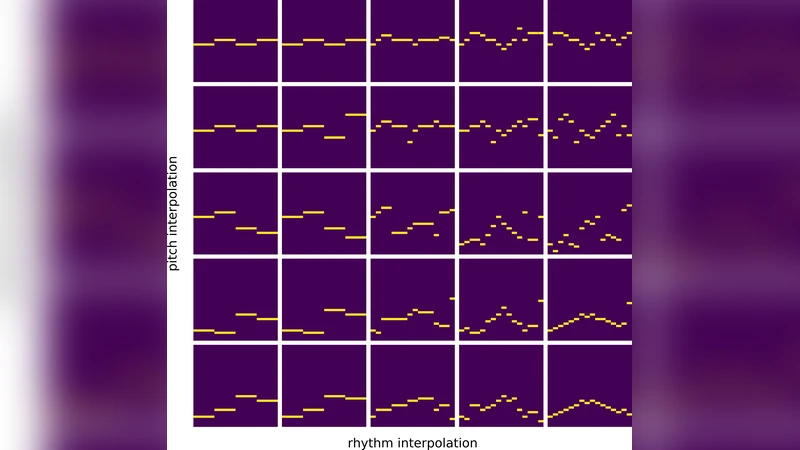
The experiments use 8‑beat (32 sixteenth‑note) melodic fragments from the Nottingham dataset. Each fragment is encoded as a sequence of 32 one‑hot vectors of dimension 130 (128 pitch onsets, one “hold” flag, one “rest” flag). A separate rhythm feature (3‑dimensional one‑hot per time step) encodes onset/hold/rest without pitch information. Chord progressions are supplied as a conditioning signal: a 32‑step chromagram where each step is a 12‑dimensional multi‑hot vector indicating active pitch classes.
Model Architecture
The encoder is a single‑layer bidirectional GRU that receives the concatenated melody and chord condition at each time step, producing a Gaussian posterior Q(z|x,c). The latent vector z has 256 dimensions and is explicitly split into two halves: zᵣ (rhythm) and zₚ (pitch), each 128‑dimensional. The decoder consists of three parts: (a) a rhythm sub‑decoder (single‑layer GRU) that takes zᵣ and predicts the rhythm feature r(x) using cross‑entropy loss, (b) a concatenation of the predicted rhythm, zₚ, and the chord condition, and (c) a full‑sequence decoder (stacked GRUs with teacher forcing) that reconstructs the original 130‑dimensional melody. By forcing the intermediate output of the rhythm sub‑decoder to match the ground‑truth rhythm, the model explicitly encourages zᵣ to capture only rhythmic information, leaving zₚ to capture pitch information.
Theoretical Justification
The training objective augments the standard conditional VAE Evidence Lower Bound (ELBO) with the rhythm reconstruction term. The authors show that this new ELBO is a lower bound of the original ELBO because the added term is non‑positive. Moreover, under perfect disentanglement—when the global decoder receives the true rhythm rather than the predicted one—the augmented ELBO collapses to the original ELBO, proving that the explicit constraint does not inherently sacrifice reconstruction quality.
Objective Evaluation
Two quantitative metrics are introduced: (1) Δz after pitch transposition, where the L1 norm of changes in zₚ and zᵣ is measured after shifting all notes by i semitones (i∈
Comments & Academic Discussion
Loading comments...
Leave a Comment