Hierarchical Representation Network for Steganalysis of QIM Steganography in Low-Bit-Rate Speech Signals
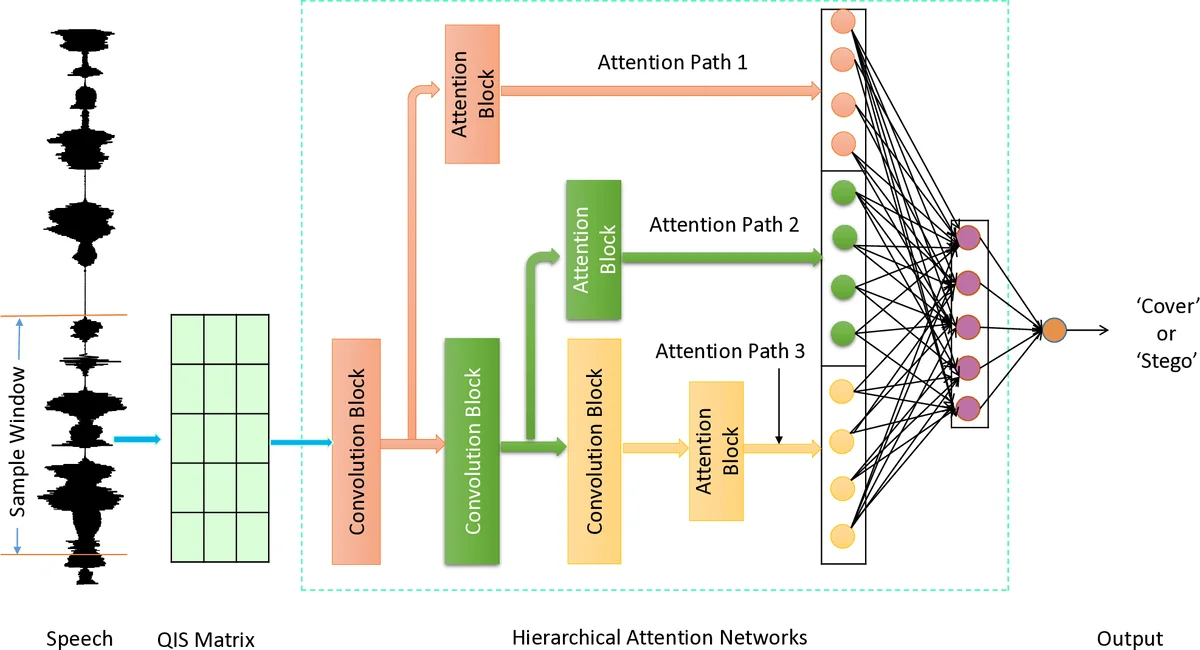
With the Volume of Voice over IP (VoIP) traffic rises shapely, more and more VoIP-based steganography methods have emerged in recent years, which poses a great threat to the security of cyberspace. Low bit-rate speech codecs are widely used in the VoIP application due to its powerful compression capability. QIM steganography makes it possible to hide secret information in VoIP streams. Previous research mostly focus on capturing the inter-frame correlation or inner-frame correlation features in code-words but ignore the hierarchical structure which exists in speech frame. In this paper, motivated by the complex multi-scale structure, we design a Hierarchical Representation Network to tackle the steganalysis of QIM steganography in low-bit-rate speech signal. In the proposed model, Convolution Neural Network (CNN) is used to model the hierarchical structure in the speech frame, and three level of attention mechanisms are applied at different convolution block, enabling it to attend differentially to more and less important content in speech frame. Experiments demonstrated that the steganalysis performance of the proposed method can outperforms the state-of-the-art methods especially in detecting both short and low embeded speech samples. Moreover, our model needs less computation and has higher time efficiency to be applied to real online services.
💡 Research Summary
**
The paper addresses the growing security threat posed by steganographic communication over Voice over IP (VoIP) networks, specifically focusing on Quantization Index Modulation (QIM) techniques applied to low‑bit‑rate speech codecs such as G.729 and G.723.1. Existing steganalysis approaches for QIM‑based hidden data primarily exploit statistical correlations between codewords or within a single frame, but they overlook the inherent hierarchical, multi‑scale structure of speech (phoneme → sub‑word → word). To fill this gap, the authors propose an end‑to‑end hierarchical representation network that explicitly models these layers of abstraction.
The core of the model consists of three stacked one‑dimensional convolutional blocks. Each block uses a different kernel size to capture increasingly broader temporal contexts, thereby mimicking the progression from fine‑grained acoustic units to higher‑level linguistic constructs. After each convolutional block, a dedicated attention mechanism is applied. These attention modules assign higher weights to time‑steps or codeword positions that are most informative for detecting the subtle distortions introduced by QIM embedding. The outputs of the three attention‑enhanced blocks are concatenated and fed into two fully connected layers that perform binary classification (cover vs. stego).
Training is supervised with cross‑entropy loss on a publicly available VoIP steganography dataset. Experiments vary both the embedding rate (0.1 % to 5 %) and the analysis window length (20 ms, 50 ms, 100 ms, 200 ms). The proposed network is compared against several baselines: a Markov‑chain statistical model, an MFCC‑based CNN, a recurrent neural network that models codeword correlations, and a recent Transformer‑style architecture. Evaluation metrics include accuracy, precision, recall, F1‑score, as well as computational cost (FLOPs) and inference latency.
Results show that the hierarchical network consistently outperforms all baselines. Overall accuracy reaches 96.3 %, with particularly strong gains on the most challenging settings—short windows (20 ms) and ultra‑low embedding rates (0.1 %). In the 20 ms scenario the model achieves 93.1 % accuracy, an improvement of more than 8 % over the best competing method. Computationally, the model requires roughly 30 % fewer FLOPs than the RNN baseline and processes a 200‑sample window in about 1.8 ms on a standard Xeon CPU, satisfying real‑time constraints for online VoIP monitoring.
The authors acknowledge several limitations. The dataset is limited to a single codec and does not include packet loss, jitter, or other network impairments that could affect QIM signatures. The design choices for the attention modules (e.g., number of heads, scaling factors) are not explored through ablation studies, and there is no visualization of what features each hierarchical level actually captures, reducing model interpretability. Moreover, details on regularization, data augmentation, and strategies to prevent over‑fitting are sparse, which may hinder reproducibility.
Future work is suggested in four directions: (1) extending experiments to multiple codecs (e.g., Opus, G.711) and realistic network conditions; (2) conducting thorough ablation and attention‑weight analysis to improve explainability; (3) developing lightweight variants (e.g., MobileNet‑V2 or EfficientNet backbones) for deployment on edge devices; and (4) integrating robustness checks against common attacks such as re‑quantization or packet reordering. By addressing these points, the hierarchical representation network could become a practical component of real‑time VoIP security infrastructures, offering both high detection performance and operational efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment