Kernel-Based Approaches for Sequence Modeling: Connections to Neural Methods
We investigate time-dependent data analysis from the perspective of recurrent kernel machines, from which models with hidden units and gated memory cells arise naturally. By considering dynamic gating of the memory cell, a model closely related to th…
Authors: Kevin J Liang, Guoyin Wang, Yitong Li
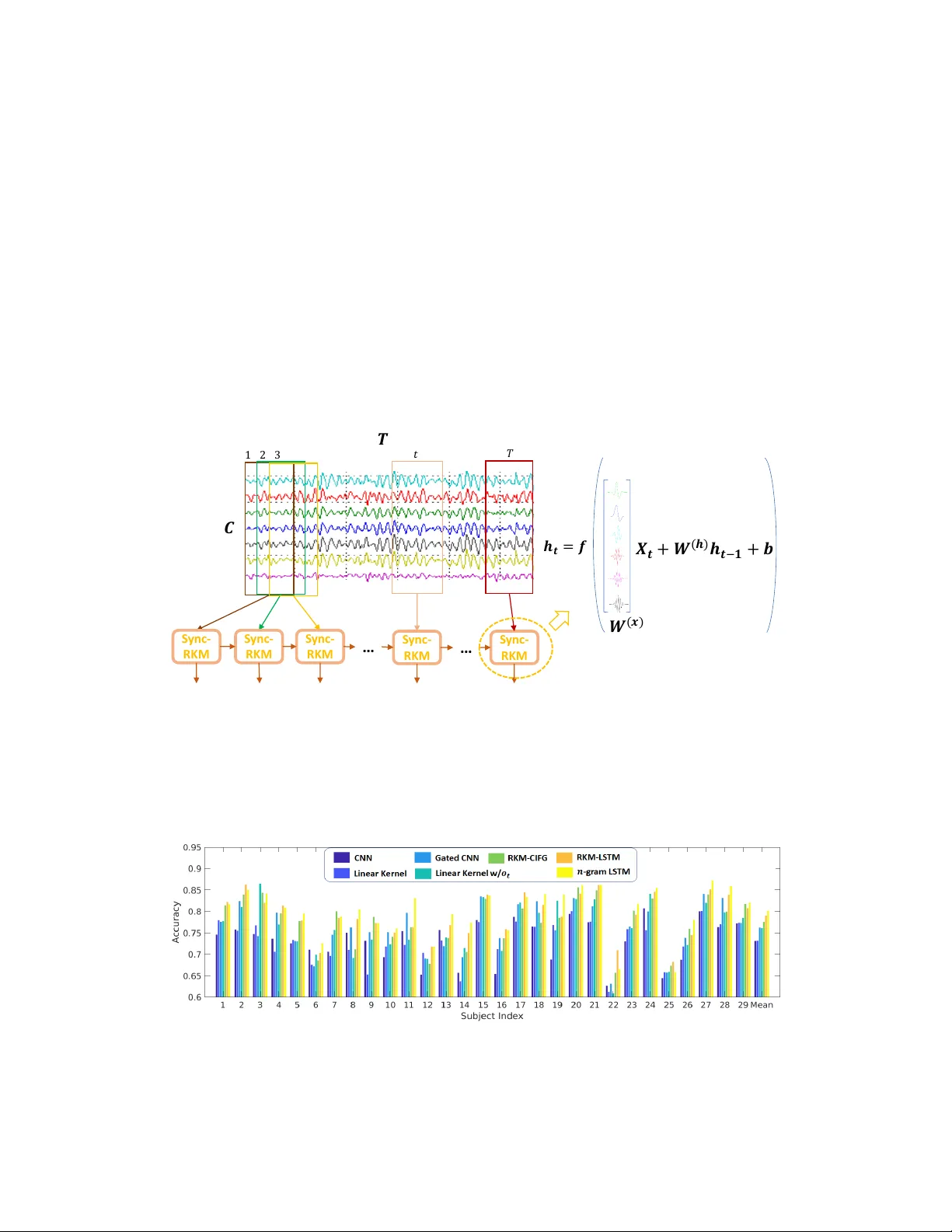
K er nel-Based A pproaches f or Sequence Modeling: Connections to Neural Methods Ke vin J Liang ∗ Guoyin W ang ∗ Y itong Li Ricardo Henao Lawrence Carin Department of Electrical and Computer Engineering Duke Uni versity {kevin.liang, guoyin.wang, yitong.li, ricardo.henao, lcarin}@duke.edu Abstract W e in vestigate time-dependent data analysis from the perspecti ve of recurrent kernel machines, from which models with hidden units and gated memory cells arise naturally . By considering dynamic gating of the memory cell, a model closely related to the long short-term memory (LSTM) recurrent neural network is deriv ed. Extending this setup to n -gram filters, the con volutional neural network (CNN), Gated CNN, and recurrent additi ve network (RAN) are also recov ered as special cases. Our analysis provides a ne w perspecti ve on the LSTM, while also extending it to n -gram con volutional filters. Experiments are performed on natural language processing tasks and on analysis of local field potentials (neuroscience). W e demonstrate that the variants we deri ve from kernels perform on par or e ven better than traditional neural methods. For the neuroscience application, the ne w models demonstrate significant improv ements relative to the prior state of the art. 1 Introduction There has been significant recent effort directed at connecting deep learning to kernel machines [ 1 , 5 , 23 , 36 ]. Specifically , it has been recognized that a deep neural network may be viewed as constituting a feature mapping x → ϕ θ ( x ) , for input data x ∈ R m . The nonlinear function ϕ θ ( x ) , with model parameters θ , has an output that corresponds to a d -dimensional feature vector; ϕ θ ( x ) may be viewed as a mapping of x to a Hilbert space H , where H ⊂ R d . The final layer of deep neural networks typically corresponds to an inner product ω | ϕ θ ( x ) , with weight vector ω ∈ H ; for a vector output, there are multiple ω , with ω | i ϕ θ ( x ) defining the i -th component of the output. For example, in a deep con volutional neural network (CNN) [ 19 ], ϕ θ ( x ) is a function defined by the multiple con volutional layers, the output of which is a d -dimensional feature map; ω represents the fully-connected layer that imposes inner products on the feature map. Learning ω and θ , i.e. , the cumulativ e neural network parameters, may be interpreted as learning within a reproducing k ernel Hilbert space (RKHS) [ 4 ], with ω the function in H ; ϕ θ ( x ) represents the mapping from the space of the input x to H , with associated kernel k θ ( x, x 0 ) = ϕ θ ( x ) | ϕ θ ( x 0 ) , where x 0 is another input. Insights garnered about neural netw orks from the perspecti ve of kernel machines provide v aluable theoretical underpinnings, helping to explain why such models work well in practice. As an example, the RKHS perspective helps explain in variance and stability of deep models, as a consequence of the smoothness properties of an appropriate RKHS to variations in the input x [ 5 , 23 ]. Further , such insights provide the opportunity for the de velopment of ne w models. Most prior research on connecting neural networks to kernel machines has assumed a single input x , e.g . , image analysis in the conte xt of a CNN [ 1 , 5 , 23 ]. Howe ver , the recurrent neural network (RNN) has also received renewed interest for analysis of sequential data. For example, long short-term memory (LSTM) [ 15 , 13 ] and the gated recurrent unit (GR U) [ 9 ] hav e become fundamental elements ∗ These authors contributed equally to this w ork. 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), V ancouv er , Canada. in many natural language processing (NLP) pipelines [ 16 , 9 , 12 ]. In this context, a sequence of data vectors ( . . . , x t − 1 , x t , x t +1 , . . . ) is analyzed, and the aforementioned single-input models are inappropriate. In this paper , we extend to r ecurr ent neural networks (RNNs) the concept of analyzing neural networks from the perspectiv e of kernel machines. Leveraging recent work on recurrent kernel machines (RKMs) for sequential data [ 14 ], we make ne w connections between RKMs and RNNs, showing how RNNs may be constructed in terms of recurrent kernel machines, using simple filters. W e demonstrate that these recurrent kernel machines are composed of a memory cell that is updated sequentially as ne w data come in, as well as in terms of a (distinct) hidden unit. A recurrent model that employs a memory cell and a hidden unit evok es ideas from the LSTM. Howe ver , within the recurrent kernel machine representation of a basic RNN, the rate at which memory f ades with time is fixed. T o impose adaptivity within the recurrent kernel machine, we introduce adaptiv e gating elements on the updated and prior components of the memory cell, and we also impose a gating network on the output of the model. W e demonstrate that the result of this refinement of the recurrent kernel machine is a model closely related to the LSTM, providing ne w insights on the LSTM and its connection to kernel machines. Continuing with this framew ork, we also introduce new concepts to models of the LSTM type. The refined LSTM framew ork may be viewed as con volving learned filters across the input sequence and using the con volutional output to constitute the time-dependent memory cell. Multiple filters, possibly of dif ferent temporal lengths, can be utilized, lik e in the CNN. One recov ers the CNN [ 18 , 37 , 17 ] and Gated CNN [ 10 ] models of sequential data as special cases, by turning of f elements of the ne w LSTM setup. From another perspective, we demonstrate that the new LSTM-like model may be viewed as introducing g ated memory cells and feedback to a CNN model of sequential data. In addition to dev eloping the aforementioned models for sequential data, we demonstrate them in an extensi ve set of e xperiments, focusing on applications in natural language processing (NLP) and in analysis of multi-channel, time-dependent local field potential (LFP) recordings from mouse brains. Concerning the latter , we demonstrate mark ed improv ements in performance of the proposed methods relativ e to recently-dev eloped alternativ e approaches [22]. 2 Recurrent K er nel Network Consider a sequence of vectors ( . . . , x t − 1 , x t , x t +1 , . . . ) , with x t ∈ R m . For a language model, x t is the embedding vector for the t -th word w t in a sequence of words. T o model this sequence, we introduce y t = U h t , with the recurrent hidden variable satisfying h t = f ( W ( x ) x t + W ( h ) h t − 1 + b ) (1) where h t ∈ R d , U ∈ R V × d , W ( x ) ∈ R d × m , W ( h ) ∈ R d × d , and b ∈ R d . In the conte xt of a language model, the vector y t ∈ R V may be fed into a nonlinear function to predict the next word w t +1 in the sequence. Specifically , the probability that w t +1 corresponds to i ∈ { 1 , . . . , V } in a vocab ulary of V words is defined by element i of vector Softmax( y t + β ) , with bias β ∈ R V . In classification, such as the LFP-analysis example in Section 6, V is the number of classes under consideration. W e constitute the factorization U = AE , where A ∈ R V × j and E ∈ R j × d , often with j V . Hence, we may write y t = Ah 0 t , with h 0 t = E h t ; the columns of A may be viewed as time-in variant factor loadings, and h 0 t represents a vector of dynamic f actor scores. Let z t = [ x t , h t − 1 ] represent a column vector corresponding to the concatenation of x t and h t − 1 ; then h t = f ( W ( z ) z t + b ) where W ( z ) = [ W ( x ) , W ( h ) ] ∈ R d × ( d + m ) . Computation of E h t corresponds to inner products of the rows of E with the vector h t . Let e i ∈ R d be a column vector , with elements corresponding to row i ∈ { 1 , . . . , j } of E . Then component i of h 0 t is h 0 i,t = e | i h t = e | i f ( W ( z ) z t + b ) (2) W e vie w f ( W ( z ) z t + b ) as mapping z t into a RKHS H , and v ector e i is also assumed to reside within H . W e consequently assume e i = f ( W ( z ) ˜ z i + b ) (3) where ˜ z i = [ ˜ x i , ˜ h 0 ] . Note that here ˜ h 0 also depends on index i , which we omit for simplicity; as discussed below , ˜ x i will play the primary role when performing computations. e | i h t = e | i f ( W ( z ) z t + b ) = f ( W ( z ) ˜ z i + b ) | f ( W ( z ) z t + b ) = k θ ( ˜ z i , z t ) (4) 2 (a) (b) (c) Figure 1: a) A traditional recurrent neural network (RNN), with the factorization U = AE . b) A recurrent kernel machine (RKM), with an implicit hidden state and recurrence through recursion. c) The recurrent kernel machine expressed in terms of a memory cell. where k θ ( ˜ z i , z t ) = h ( ˜ z i ) | h ( z t ) is a Mercer kernel [ 29 ]. Particular kernel choices correspond to dif ferent functions f ( W ( z ) z t + b ) , and θ is meant to represent k ernel parameters that may be adjusted. W e initially focus on kernels of the form k θ ( ˜ z , z t ) = q θ ( ˜ z | z t ) = ˜ h | 1 h t , 1 where q θ ( · ) is a function of parameters θ , h t = h ( z t ) , and ˜ h 1 is the implicit latent vector associated with the inner product, i.e. , ˜ h 1 = f ( W ( x ) ˜ x + W ( h ) ˜ h 0 + b ) . As discussed below , we will not need to explicitly ev aluate h t or ˜ h 1 to ev aluate the kernel, taking adv antage of the recursive relationship in (1). In fact, depending on the choice of q θ ( · ) , the hidden v ectors may ev en be infinite-dimensional. Howe ver , because of the relationship q θ ( ˜ z | z t ) = ˜ h | 1 h t , for rigorous analysis q θ ( · ) should satisfy Mercer’ s condition [ 11 , 29 ]. The vectors ( ˜ h 1 , ˜ h 0 , ˜ h − 1 , . . . ) are assumed to satisfy the same recurrence setup as (1), with each vector in the associated sequence ( ˜ x t , ˜ x t − 1 , . . . ) assumed to be the same ˜ x i at each time, i.e. , associated with e i , ( ˜ x t , ˜ x t − 1 , . . . ) → ( ˜ x i , ˜ x i , . . . ) . Stepping backwards in time three steps, for example, one may sho w k θ ( ˜ z i , z t ) = q θ [ ˜ x | i x t + q θ [ ˜ x | i x t − 1 + q θ [ ˜ x | i x t − 2 + q θ [ ˜ x | i x t − 3 + ˜ h | − 4 h t − 4 ]]]] (5) The inner product ˜ h | − 4 h t − 4 encapsulates contributions for all times further backwards, and for a sequence of length N , ˜ h | − N h t − N plays a role analogous to a bias. As discussed below , for stability the repeated application of q θ ( · ) yields diminishing (fading) contributions from terms earlier in time, and therefore for large N the impact of ˜ h | − N h t − N on k θ ( ˜ z i , z t ) is small. The ov erall model may be expressed as h 0 t = q θ ( c t ) , c t = ˜ c t + q θ ( c t − 1 ) , ˜ c t = ˜ X x t (6) where c t ∈ R j is a memory cell at time t , ro w i of ˜ X corresponds to ˜ x | i , and q θ ( c t ) operates pointwise on the components of c t (see Figure 1). At the start of the sequence of length N , q θ ( c t − N ) may be seen as a vector of biases, ef fectively corresponding to ˜ h | N h t − N ; we henceforth omit discussion of this initial bias for notational simplicity , and because for suf ficiently lar ge N its impact on h 0 t is small. Note that via the recursi ve process by which c t is e valuated in (6), the k ernel ev aluations reflected by q θ ( c t ) are defined entirely by the elements of the sequence (˜ c t , ˜ c t − 1 , ˜ c t − 2 , . . . ) . Let ˜ c i,t repre- sent the i -th component in vector ˜ c t , and define x ≤ t = ( x t , x t − 1 , x t − 2 , . . . ) . Then the sequence (˜ c i,t , ˜ c i,t − 1 , ˜ c i,t − 2 , . . . ) is specified by con volving in time ˜ x i with x ≤ t , denoted ˜ x i ∗ x ≤ t . Hence, the j components of the sequence (˜ c t , ˜ c t − 1 , ˜ c t − 2 , . . . ) are completely specified by con volving x ≤ t with each of the j filters, ˜ x i , i ∈ { 1 , . . . , j } , i.e. , taking an inner product of ˜ x i with the vector in x ≤ t at each time point. In (4) we represented h 0 i,t = q θ ( c i,t ) as h 0 i,t = k θ ( ˜ z i , z t ) ; no w , because of the recursi ve form of the model in (1), and because of the assumption k θ ( ˜ z i , z t ) = q θ ( ˜ z | i z t ) , we hav e demonstrated that we may express the k ernel equiv alently as k θ ( ˜ x i ∗ x ≤ t ) , to underscore that it is defined entirely by the elements at the output of the con volution ˜ x i ∗ x ≤ t . Hence, we may express component i of h 0 t as h 0 i,t = k θ ( ˜ x i ∗ x ≤ t ) . 1 One may also design recurrent kernels of the form k θ ( ˜ z , z t ) = q θ ( k ˜ z − z t k 2 2 ) [ 14 ], as for a Gaussian kernel, but if vectors x t and filters ˜ x i are normalized ( e.g . , x | t x t = ˜ x | i ˜ x i = 1 ), then q θ ( k ˜ z − z t k 2 2 ) reduces to q θ ( ˜ z | z t ) . 3 Component l ∈ { 1 , . . . , V } of y t = Ah 0 t may be expressed y l,t = j X i =1 A l,i k θ ( ˜ x i ∗ x ≤ t ) (7) where A l,i represents component ( l, i ) of matrix A . Considering (7), the connection of an RNN to an RKHS is clear , as made explicit by the k ernel k θ ( ˜ x i ∗ x ≤ t ) . The RKHS is manifested for the final output y t , with the hidden h t no w absorbed within the kernel, via the inner product (4). The feedback imposed via latent vector h t is constituted via update of the memory cell c t = ˜ c t + q θ ( c t − 1 ) used to ev aluate the kernel. Rather than ev aluating y t as in (7), it will prove conv enient to return to (6). Specifically , we may consider modifying (6) by injecting further feedback via h 0 t , augmenting (6) as h 0 t = q θ ( c t ) , c t = ˜ c t + q θ ( c t − 1 ) , ˜ c t = ˜ X x t + ˜ H h 0 t − 1 (8) where ˜ H ∈ R j × j , and recalling y t = Ah 0 t (see Figure 2a for illustration). In (8) the input to the kernel is dependent on the input elements ( x t , x t − 1 , . . . ) and is now also a function of the kernel outputs at the pre vious time, via h 0 t − 1 . Howe ver , note that h 0 t is still specified entirely by the elements of ˜ x i ∗ x ≤ t , for i ∈ { 1 , . . . , j } . 3 Choice of Recurrent K er nels & Introduction of Gating Networks 3.1 Fixed kernel parameters & time-in variant memory-cell gating The function q θ ( · ) discussed abov e may take se veral forms, the simplest of which is a linear k ernel, with which (8) takes the form h 0 t = c t , c t = σ 2 i ˜ c t + σ 2 f c t − 1 , ˜ c t = ˜ X x t + ˜ H h 0 t − 1 (9) where σ 2 i and σ 2 f (using analogous notation from [ 14 ]) are scalars, with σ 2 f < 1 for stability . The scalars σ 2 i and σ 2 f may be viewed as static ( i.e . , time-in variant) gating elements, with σ 2 i controlling weighting on the ne w input element to the memory cell, and σ 2 f controlling ho w much of the prior memory unit is retained; given σ 2 f < 1 , this means information from pre vious time steps tends to fade a way and ov er time is largely for gotten. Howe ver , such a kernel leads to time-in v ariant decay of memory: the contribution ˜ c t − N from N steps before to the current memory c t is ( σ i σ N f ) 2 ˜ c t − N , meaning that it decays at a constant exponential rate. Because the information contained at each time step can vary , this can be problematic. This suggests augmenting the model, with time-varying gating weights, with memory-component dependence on the weights, which we consider below . 3.2 Dynamic gating networks & LSTM-like model Recent work has shown that dynamic gating can be seen as making a recurrent network quasi-in variant to temporal warpings [ 30 ]. Moti vated by the form of the model in (9) then, it is natural to impose dynamic versions of σ 2 i and σ 2 f ; we also introduce dynamic gating at the output of the hidden vector . This yields the model: h 0 t = o t c t , c t = η t ˜ c t + f t c t − 1 , ˜ c t = W c z 0 t (10) o t = σ ( W o z 0 t + b o ) , η t = σ ( W η z 0 t + b η ) , f t = σ ( W f z 0 t + b f ) (11) where z 0 t = [ x t , h 0 t − 1 ] , and W c encapsulates ˜ X and ˜ H . In (10)-(11) the symbol represents a pointwise vector product (Hadamard); W c , W o , W η and W f are weight matrices; b o , b η and b f are bias vectors; and σ ( α ) = 1 / (1 + exp( − α )) . In (10), η t and f t play dynamic counterparts to σ 2 i and σ 2 f , respecti vely . Further , o t , η t and f t are vectors , constituting v ector-component-dependent gating. Note that starting from a recurrent kernel machine, we have thus deri ved a model closely resembling the LSTM. W e call this model RKM-LSTM (see Figure 2). Concerning the update of the hidden state, h 0 t = o t c t in (10), one may also consider appending a hyperbolic-tangent tanh nonlinearity: h 0 t = o t tanh( c t ) . Ho wever , recent research has suggested not using such a nonlinearity [ 20 , 10 , 7 ], and this is a natural consequence of our recurrent kernel analysis. Using h 0 t = o t tanh( c t ) , the model in (10) and (11) is in the form of the LSTM, except without the nonlinearity imposed on the memory cell ˜ c t , while in the LSTM a tanh nonlinearity (and biases) is employed when updating the memory cell [ 15 , 13 ], i.e. , for the LSTM ˜ c t = tanh( W c z 0 t + 4 (a) (b) Figure 2: a) Recurrent kernel machine, with feedback, as defined in (8). b) Making a linear kernel assumption and adding input, forget, and output gating, this model becomes the RKM-LSTM. b c ) . If o t = 1 for all time t (no output gating network), and if ˜ c t = W c x t (no dependence on h 0 t − 1 for update of the memory cell), this model reduces to the recurrent additiv e network (RAN) [20]. While separate gates η t and f t were constituted in (10) and (11) to operate on the new and prior composition of the memory cell, one may also also consider a simpler model with memory cell updated c t = (1 − f t ) ˜ c t + f t c t − 1 ; this was referred to as having a Coupled Input and For get Gate (CIFG) in [ 13 ]. In such a model, the decisions of what to add to the memory cell and what to forget are made jointly , obviating the need for a separate input gate η t . W e call this variant RKM-CIFG. 4 Extending the Filter Length 4.1 Generalized form of r ecurrent model Consider a generalization of (1): h t = f ( W ( x 0 ) x t + W ( x − 1 ) x t − 1 + · · · + W ( x − n +1 ) x t − n +1 + W ( h ) h t − 1 + b ) (12) where W ( x · ) ∈ R d × m , W ( h ) ∈ R d × d , and therefore the update of the hidden state h t 2 depends on data observed n ≥ 1 time steps prior , and also on the pre vious hidden state h t − 1 . Analogous to (3), we may express e i = f ( W ( x 0 ) ˜ x i, 0 + W ( x − 1 ) ˜ x i, − 1 + · · · + W ( x − n +1 ) ˜ x i, − n +1 + W ( h ) ˜ h i + b ) (13) The inner product f ( W ( x 0 ) x t + W ( x − 1 ) x t − 1 + · · · + W ( x − n +1 ) x t − n +1 + W ( h ) h t − 1 + b ) | f ( W ( x 0 ) ˜ x i, 0 + W ( x − 1 ) ˜ x i, − 1 + · · · + W ( x − n +1 ) ˜ x i, − n +1 + W ( h ) ˜ h i + b ) is assumed represented by a Mercer kernel, and h 0 i,t = e | i h t . Let X t = ( x t , x t − 1 , . . . , x t − n +1 ) ∈ R m × n be an n -gram input with zero padding if t < ( n − 1) , and ˜ X = ( ˜ X 0 , ˜ X − 1 , . . . , ˜ X − n +1 ) be n sets of filters, with the i -th ro ws of ˜ X 0 , ˜ X − 1 , . . . , ˜ X − n +1 collectiv ely represent the i -th n -gram filter , with i ∈ { 1 , . . . , j } . Extending Section 2, the kernel is defined h 0 t = q θ ( c t ) , c t = ˜ c t + q θ ( c t − 1 ) , ˜ c t = ˜ X · X t (14) where ˜ X · X t ≡ ˜ X 0 x t + ˜ X − 1 x t − 1 + · · · + ˜ X − n +1 x t − n +1 ∈ R j . Note that ˜ X · X t corresponds to the t -th component output from the n -gram con volution of the filters ˜ X and the input sequence; therefore, similar to Section 2, we represent h 0 t = q θ ( c t ) as h 0 t = k θ ( ˜ X ∗ x ≤ t ) , emphasizing that the kernel e valuation is a function of outputs of the con volution ˜ X ∗ x ≤ t , here with n -gram filters. Like in the CNN [ 18 , 37 , 17 ], dif ferent filter lengths (and kernels) may be considered to constitute different components of the memory cell. 4.2 Linear kernel, CNN and Gated CNN For the linear kernel discussed in connection to (9), equation (14) becomes h 0 t = c t = σ 2 i ( ˜ X · X t ) + σ 2 f h 0 t − 1 (15) For the special case of σ 2 f = 0 and σ 2 i equal to a constant ( e.g . , σ 2 i = 1 ), (15) reduces to a con volutional neural network (CNN), with a nonlinear operation typically applied subsequently to h 0 t . 2 Note that while the same symbol is used as in (12), h t clearly takes on a dif ferent meaning when n > 1 . 5 Rather than setting σ 2 i to a constant, one may impose dynamic gating, yielding the model (with σ 2 f = 0 ) h 0 t = η t ( ˜ X · X t ) , η t = σ ( ˜ X η · X t + b η ) (16) where ˜ X η are distinct con volutional filters for calculating η t , and b η is a vector of biases. The form of the model in (16) corresponds to the Gated CNN [ 10 ], which we see as a a special case of the recurrent model with linear kernel, and dynamic kernel weights (and without feedback, i.e. , σ 2 f = 0 ). Note that in (16) a nonlinear function is not imposed on the output of the con volution ˜ X · X t , there is only dynamic gating via multiplication with η t ; the advantages of which are discussed in [ 10 ]. Further , the n -gram input considered in (12) need not be consecutiv e. If spacings between inputs of more than 1 are considered, then the dilated con volution ( e .g. , as used in [31]) is recov ered. 4.3 Feedback and the generalized LSTM Now introducing feedback into the memory cell, the model in (8) is e xtended to h 0 t = q θ ( c t ) , c t = ˜ c t + q θ ( c t − 1 ) , ˜ c t = ˜ X · X t + ˜ H h 0 t − 1 (17) Again moti vated by the linear kernel, generalization of (17) to include g ating networks is h 0 t = o t c t , c t = η t ˜ c t + f t c t − 1 , ˜ c t = ˜ X · X t + ˜ H h 0 t − 1 (18) o t = σ ( ˜ X o · X t + ˜ W o h 0 t − 1 + b o ) , η t = σ ( ˜ X η · X t + ˜ W η h 0 t − 1 + b η ) , f t = σ ( ˜ X f · X t + ˜ W f h 0 t − 1 + b f ) (19) where y t = Ah 0 t and ˜ X o , ˜ X η , and ˜ X f are separate sets of n -gram con volutional filters akin to ˜ X . As an n -gram generalization of (10)-(11), we refer to (18)-(19) as an n -gram RKM-LSTM. The model in (18) and (19) is similar to the LSTM, with important differences: ( i ) there is not a nonlinearity imposed on the update to the memory cell, ˜ c t , and therefore there are also no biases imposed on this cell update; ( ii ) there is no nonlinearity on the output; and ( iii ) via the con volutions with ˜ X , ˜ X o , ˜ X η , and ˜ X f , the memory cell can tak e into account n -grams, and the length of such sequences n i may vary as a function of the element of the memory cell. 5 Related W ork In our de velopment of the kernel perspecti ve of the RNN, we hav e emphasized that the form of the kernel k θ ( ˜ z i , z t ) = q θ ( ˜ z | i z t ) yields a recursi ve means of kernel e valuation that is only a function of the elements at the output of the con volutions ˜ X ∗ x ≤ t or ˜ X ∗ x ≤ t , for 1-gram and ( n > 1) -gram filters, respectively . This underscores that at the heart of such models, one performs conv olutions between the sequence of data ( . . . , x t +1 , x t , x t − 1 , . . . ) and filters ˜ X or ˜ X . Consideration of filters of length greater than one (in time) yields a generalization of the traditional LSTM. The dependence of such models entirely on con volutions of the data sequence and filters is ev ocative of CNN and Gated CNN models for text [18, 37, 17, 10], with this made e xplicit in Section 4.2 as a special case. The Gated CNN in (16) and the generalized LSTM in (18)-(19) both employ dynamic gating. Howe ver , the generalized LSTM explicitly employs a memory cell (and feedback), and hence offers the potential to le verage long-term memory . While memory affords adv antages, a noted limitation of the LSTM is that computation of h 0 t is sequential, undermining parallel computation, particularly while training [ 10 , 33 ]. In the Gated CNN, h 0 t comes directly from the output of the gated con volution, allowing parallel fitting of the model to time-dependent data. While the Gated CNN does not employ recurrence, the filters of length n > 1 do lev erage extended temporal dependence. Further, via deep Gated CNNs [10], the effective support of the filters at deeper layers can be e xpansiv e. Recurrent kernels of the form k θ ( ˜ z , z t ) = q θ ( ˜ z | z t ) were also dev eloped in [ 14 ], but with the goal of extending recurrent kernel machines to sequential inputs, rather than making connections with RNNs. The formulation in Section 2 has tw o important diff erences with that prior work. First, we employ the same vector ˜ x i for all shift positions t of the inner product ˜ x | i x t . By contrast, in [14] effecti vely infinite-dimensional filters are used, because the filter ˜ x t,i changes with t . This makes implementation computationally impractical, necessitating truncation of the long temporal filter . Additionally , the feedback of h 0 t in (8) was not considered, and as discussed in Section 3.2, our proposed setup yields natural connections to long short-term memory (LSTM) [15, 13]. Prior work analyzing neural networks from an RKHS perspective has largely been based on the feature mapping ϕ θ ( x ) and the weight ω [ 1 , 5 , 23 , 36 ]. For the recurrent model of interest here, 6 Model Parameters Input Cell Output LSTM [15] ( nm + d )(4 d ) z 0 t = [ x t , h 0 t − 1 ] c t = η t tanh( ˜ c t ) + f t c t − 1 h 0 t = o t tanh( c t ) RKM-LSTM ( nm + d )(4 d ) z 0 t = [ x t , h 0 t − 1 ] c t = η t ˜ c t + f t c t − 1 h 0 t = o t c t RKM-CIFG ( nm + d )(3 d ) z 0 t = [ x t , h 0 t − 1 ] c t = (1 − f t ) ˜ c t + f t c t − 1 h 0 t = o t c t Linear Kernel w/ o t ( nm + d )(2 d ) z 0 t = [ x t , h 0 t − 1 ] c t = σ 2 i ˜ c t + σ 2 f c t − 1 h 0 t = o t c t Linear Kernel ( nm + d )( d ) z 0 t = [ x t , h 0 t − 1 ] c t = σ 2 i ˜ c t + σ 2 f c t − 1 h 0 t = tanh( c t ) Gated CNN [10] ( nm )(2 d ) z 0 t = x t c t = σ 2 i ˜ c t h 0 t = o t c t CNN [18] ( nm )( d ) z 0 t = x t c t = σ 2 i ˜ c t h 0 t = tanh( c t ) T able 1: Model variants under consideration, assuming 1-gram inputs. Concatenating additional inputs x t − 1 , . . . , x t − n +1 to z 0 t in the Input column yields the corresponding n -gram model. Number of model parameters are shown for input x t ∈ R m and output h 0 t ∈ R d . function h t = f ( W ( x ) x t + W ( h ) h t − 1 + b ) plays a role like ϕ θ ( x ) as a mapping of an input x t to what may be vie wed as a feature vector h t . Howe ver , because of the recurrence, h t is a function of ( x t , x t − 1 , . . . ) for an arbitrarily long time period prior to time t : h t ( x t , x t − 1 , . . . ) = f ( W ( x ) x t + b + W ( h ) f ( W ( x ) x t − 1 + b + W ( h ) f ( W ( x ) x t − 2 + b + . . . ))) (20) Howe ver , rather than explicitly working with h t ( x t , x t − 1 , . . . ) , we focus on the kernel k θ ( ˜ z i , z t ) = q θ ( ˜ z | i z t ) = k θ ( ˜ x i ∗ x ≤ t ) . The authors of [ 21 ] derive recurrent neural networks from a string kernel by replacing the exact matching function with an inner product and assume the decay factor to be a nonlinear function. Con volutional neural netw orks are recovered by replacing a pointwise multiplication with addition. Howe ver , the formulation cannot recov er the standard LSTM formulation, nor is there a consistent formulation for all the gates. The authors of [ 28 ] introduce a kernel-based update rule to approximate backpropagation through time (BPTT) for RNN training, but still follow the standard RNN structure. Previous works hav e considered recurrent models with n -gram inputs as in (12). For example, strongly-typed RNNs [ 3 ] consider bigram inputs, but the previous input x t − 1 is used as a replacement for h t − 1 rather than in conjunction, as in our formulation. Quasi-RNNs [ 6 ] are similar to [ 3 ], but generalize them with a con volutional filter for the input and use different nonlinearities. Inputs corresponding to n -grams hav e also been implicitly considered by models that use con volutional layers to extract features from n -grams that are then fed into a recurrent network ( e.g . , [ 8 , 35 , 38 ]). Relativ e to (18), these models contain an extra nonlinearity f ( · ) from the con volution and projection matrix W ( x ) from the recurrent cell, and no longer recov er the CNN [ 18 , 37 , 17 ] or Gated CNN [ 10 ] as special cases. 6 Experiments In the following experiments, we consider several model variants, with nomenclature as follows. The n -gram LSTM dev eloped in Sec. 4.3 is a generalization of the standard LSTM [ 15 ] (for which n = 1 ). W e denote RKM-LSTM (recurrent kernel machine LSTM) as corresponding to (10)-(11), which resembles the n -gram LSTM, b ut without a tanh nonlinearity on the cell update ˜ c t or emission c t . W e term RKM-CIFG as a RKM-LSTM with η t = 1 − f t , as discussed in Section 3.2. Linear Ker nel w/ o t corresponds to (10)-(11) with η t = σ 2 i and f t = σ 2 f , with σ 2 i and σ 2 f time-in variant constants; this corresponds to a linear kernel for the update of the memory cell, and dynamic gating on the output, via o t . W e also consider the same model without dynamic gating on the output, i.e. , o t = 1 for all t (with a tanh nonlinearity on the output), which we call Linear K ernel . The Gated CNN corresponds to the model in [ 10 ], which is the same as Linear K ernel w/ o t , but with σ 2 f = 0 ( i.e. , no memory). Finally , we consider a CNN model [ 18 ], that is the same as the Linear Kernel model, but without feedback or memory , i.e. , z 0 t = x t and σ 2 f = 0 . For all of these, we may also consider an n -gram generalization as introduced in Section 4. For example, a 3-gram RKM-LSTM corresponds to (18)-(19), with length-3 con volutional filters in the time dimension. The models are summarized in T able 1. All experiments are run on a single NVIDIA T itan X GPU. Document Classification W e show results for se veral popular document classification datasets [ 37 ] in T able 2. The A GNews and Y ahoo! datasets are topic classification tasks, while Y elp Full is sentiment analysis and DBpedia is ontology classification. The same basic network architecture is used for all models, with the only difference being the choice of recurrent cell, which we make single-layer and unidirectional. Hidden representations h 0 t are aggregated with mean pooling across 7 Parameters A GNews DBpedia Y ahoo! Y elp Full Model 1-gram 3-gram 1-gram 3-gram 1-gram 3-gram 1-gram 3-gram 1-gram 3-gram LSTM 720K 1.44M 91.82 92.46 98.98 98.97 77.74 77.72 66.27 66.37 RKM-LSTM 720K 1.44M 91.76 92.28 98.97 99.00 77.70 77.72 65.92 66.43 RKM-CIFG 540K 1.08M 92.29 92.39 98.99 99.05 77.71 77.91 65.93 65.92 Linear Kernel w/ o t 360K 720K 92.07 91.49 98.96 98.94 77.41 77.53 65.35 65.94 Linear Kernel 180K 360K 91.62 91.50 98.65 98.77 76.93 76.53 61.18 62.11 Gated CNN [10] 180K 540K 91.54 91.78 98.37 98.77 72.92 76.66 60.25 64.30 CNN [18] 90K 270K 91.20 91.53 98.17 98.52 72.51 75.97 59.77 62.08 T able 2: Document classification accuracy for 1-gram and 3-gram versions of v arious models. T otal parameters of each model are shown, e xcluding word embeddings and the classifier . PTB Wikitext-2 Model PPL valid PPL test PPL v alid PPL test LSTM [15, 25] 61.2 58.9 68.74 65.68 RKM-LSTM 60.3 58.2 67.85 65.22 RKM-CIFG 61.9 59.5 69.12 66.03 Linear Kernel w/ o t 72.3 69.7 84.23 80.21 T able 3: Language Model perplexity(PPL) on validation and test sets of the Penn Treebank and W ikitext-2 language modeling tasks. time, follo wed by two fully connected layers, with the second having output size corresponding to the number of classes of the dataset. W e use 300-dimensional GloV e [ 27 ] as our word embedding initialization and set the dimensions of all hidden units to 300. W e follow the same preprocessing procedure as in [ 34 ]. Layer normalization [ 2 ] is performed after the computation of the cell state c t . For the Linear K ernel w/ o t and the Linear Kernel, we set 3 σ 2 i = σ 2 f = 0 . 5 . Notably , the deriv ed RKM-LSTM model performs comparably to the standard LSTM model across all considered datasets. W e also find the CIFG version of the RKM-LSTM model to hav e similar accuracy . As the recurrent model becomes less sophisticated with regard to gating and memory , we see a corresponding decrease in classification accuracy . This decrease is especially significant for Y elp Full, which requires a more intricate comprehension of the entire text to make a correct prediction. This is in contrast to AGNe ws and DBpedia, where the success of the 1-gram CNN indicates that simple keyw ord matching is suf ficient to do well. W e also observe that generalizing the model to consider n -gram inputs typically improves performance; the highest accuracies for each dataset were achiev ed by an n -gram model. Language Modeling W e also perform experiments on popular word-le vel language generation datasets Penn T ree Bank (PTB) [ 24 ] and W ikitext-2 [ 26 ], reporting v alidation and test perplexities (PPL) in T able 3. W e adopt A WD-LSTM [ 25 ] as our base model 4 , replacing the standard LSTM with RKM-LSTM, RKM-CIFG, and Linear K ernel w/ o t to do our comparison. W e keep all other hyperparameters the same as the default. Here we consider 1-gram filters, as they performed best for this task; giv en that the datasets considered here are smaller than those for the classification experiments, 1-grams are less likely to overfit. Note that the static gating on the update of the memory cell (Linear K ernel w/ o t ) does considerably worse than the models with dynamic input and for get gates on the memory cell. The RKM-LSTM model consistently outperforms the traditional LSTM, again sho wing that the models deriv ed from recurrent kernel machines work well in practice for the data considered. LFP Classification W e perform experiments on a Local Field Potential (LFP) dataset. The LFP signal is multi-channel time series recorded inside the brain to measure neural activity . The LFP dataset used in this work contains recordings from 29 mice (wild-type or CLOCK ∆19 [ 32 ]), while the mice were ( i ) in their home cages, ( ii ) in an open field, and ( iii ) suspended by their tails. There are a total of m = 11 channels and the sampling rate is 1000 Hz. The goal of this task is to predict the state of a mouse from a 1 second segment of its LFP recording as a 3-way classification problem. 3 σ 2 i and σ 2 f can also be learned, but we found this not to ha ve much ef fect on the final performance. 4 W e use the official codebase https://github.com/salesforce/awd- lstm- lm and report ex- periment results before two-step fine-tuning. 8 Model n -gram LSTM RKM- LSTM RKM- CIFG Linear Kernel w/ o t Linear Kernel Gated CNN [10] CNN [22] Accuracy 80.24 79.02 77.58 76.11 73.13 76.02 73.40 T able 4: Mean leav e-one-out classification accuracies for mouse LFP data. For each model, ( n = 40) - gram filters are considered, and the number of filters in each model is 30 . In order to test the model generalizability , we perform leave-one-out cross-validation testing: data from each mouse is left out as testing iterativ ely while the remaining mice are used as training. SyncNet [ 22 ] is a CNN model with specifically designed wavelet filters for neural data. W e incorporate the SyncNet form of n -gram con volutional filters into our recurrent framework (we ha ve parameteric n -gram conv olutional filters, with parameters learned). As was demonstrated in Section 4.2, the CNN is a memory-less special case of our deri ved generalized LSTM. An illustration of the modified model (Figure 3) can be found in Appendix A, along with other further details on SyncNet. While the filters of SyncNet are interpretable and can pre vent ov erfitting (because they ha ve a small number of parameters), the same kind of generalization to an n -gram LSTM can be made without increasing the number of learned parameters. W e do so for all of the recurrent cell types in T able 1, with the CNN corresponding to the original SyncNet model. Compared to the original SyncNet model, our newly proposed models can jointly consider the time dependency within the whole signal. The mean classification accuracies across all mice are compared in T able 4, where we observe substantial improv ements in prediction accuracy through the addition of memory cells to the model. Thus, considering the time dependenc y in the neural signal appears to be beneficial for identifying hidden patterns. Classification performances per subject (Figure 4) can be found in Appendix A. 7 Conclusions The principal contribution of this paper is a new perspecti ve on gated RNNs, lev eraging concepts from recurrent kernel machines. From that standpoint, we ha ve deriv ed a model closely connected to the LSTM [ 15 , 13 ] (for conv olutional filters of length one), and hav e extended such models to con volutional filters of length greater than one, yielding a generalization of the LSTM. The CNN [ 18 , 37 , 17 ], Gated CNN [ 10 ] and RAN [ 20 ] models are recovered as special cases of the de veloped frame work. W e hav e demonstrated the ef ficacy of the deri ved models on NLP and neuroscience tasks, for which our RKM v ariants show comparable or better performance than the LSTM. In particular , we observe that extending LSTM v ariants with con volutional filters of length greater than one can significantly improv e the performance in LFP classification relativ e to recent prior work. Acknowledgments The research reported here was supported in part by D ARP A, DOE, NIH, NSF and ONR. References [1] Fabio Anselmi, Lorenzo Rosasco, Cheston T an, and T omaso Poggio. Deep Con volutional Networks are Hierarchical K ernel Machines. , 2015. [2] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffre y E. Hinton. Layer Normalization. arXiv:1607.06450 , 2016. [3] David Balduzzi and Muhammad Ghifary . Strongly-T yped Recurrent Neural Networks. Interna- tional Confer ence on Machine Learning , 2016. [4] Alain Berlinet and Christine Thomas-Agnan. Reproducing Kernel Hilbert spaces in Probability and Statistics. Kluwer Publishers , 2004. [5] Alberto Bietti and Julien Mairal. In variance and Stability of Deep Con volutional Representations. Neural Information Pr ocessing Systems , 2017. [6] James Bradbury , Stephen Merity , Caiming Xiong, and Richard Socher . Quasi-recurrent neural networks. International Confer ence of Learning Representations , 2017. 9 [7] Mia Xu Chen, Orhan Firat, Ankur Bapna, Melvin Johnson, W olfgang Macherey , George Foster , Llion Jones, Niki Parmar , Mike Schuster , Zhifeng Chen, Y onghui W u, and Macduff Hughes. The Best of Both W orlds: Combining Recent Adv ances in Neural Machine T ranslation. arXiv:1804.09849v2 , 2018. [8] Jianpeng Cheng and Mirella Lapata. Neural Summarization by Extracti ng Sentences and W ords. Association for Computational Linguistics , 2016. [9] Kyunghyun Cho, Bart v an Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Y oshua Bengio. Learning Phrase Representations using RNN Encoder- Decoder for Statistical Machine Translation. Empirical Methods in Natural Language Pr ocess- ing , 2014. [10] Y ann N. Dauphin, Angela Fan, Michael Auli, and Da vid Grangier . Language Modeling with Gated Con volutional Netw orks. International Confer ence on Machine Learning , 2017. [11] Marc G. Genton. Classes of Kernels for Machine Learning: A Statistics Perspecti ve. Journal of Machine Learning Resear ch , 2001. [12] David Golub and Xiaodong He. Character-Le vel Question Answering with Attention. Empirical Methods in Natural Languag e Pr ocessing , 2016. [13] Klaus Gref f, Rupesh Kumar Sri vasta va, Jan K outník, Bas R. Steunebrink, and Jürgen Schmidhu- ber . LSTM: A Search Space Odyssey. T ransactions on Neur al Networks and Learning Systems , 2017. [14] Michiel Hermans and Benjamin Schrauwen. Recurrent Kernel Machines: Computing with Infinite Echo State Networks. Neural Computation , 2012. [15] Sepp Hochreiter and Jür gen Schmidhuber . Long Short-T erm Memory. Neural Computation , 1997. [16] Rafal Jozefo wicz, W ojciech Zaremba, and Ilya Sutskev er . An Empirical Exploration of Recur- rent Network Architectures. International Confer ence on Machine Learning , 2015. [17] Y oon Kim. Conv olutional Neural Networks for Sentence Classification. Empirical Methods in Natural Languag e Pr ocessing , 2014. [18] Y ann LeCun and Y oshua Bengio. Con volutional Networks for Images, Speech, and T ime Series. The Handbook of Brain Theory and Neur al Networks , 1995. [19] Y ann LeCun, Léon Bottou, Y oshua Bengio, and Patrick Haffner . Gradient-based Learning Applied to Document Recognition. Pr oceedings of IEEE , 1998. [20] Kenton Lee, Omer Levy , and Luke Zettlemoyer . Recurrent Additiv e Networks. arXiv:1705.07393v2 , 2017. [21] T ao Lei, W engong Jin, Regina Barzilay , and T ommi Jaakkola. Deriving Neural Architectures from Sequence and Graph Kernels. International Conference on Mac hine Learning , 2017. [22] Y itong Li, Michael Murias, Samantha Major, Geraldine Dawson, Kafui Dzirasa, Lawrence Carin, and David E. Carlson. T argeting EEG/LFP Synchrony with Neural Nets. Neural Information Pr ocessing Systems , 2017. [23] Julien Mairal. End-to-End Kernel Learning with Supervised Con v olutional Kernel Netw orks. Neural Information Pr ocessing Systems , 2016. [24] Mitchell P . Marcus, Beatrice Santorini, and Mary Ann Marcinkiewicz. Building a Large Annotated Corpus of English: The Penn T reebank. Association for Computational Linguistics , 1993. [25] Stephen Merity , Nitish Shirish K eskar , and Richard Socher . Regularizing and Optimizing LSTM Language Models. International Conference on Learning Repr esentations , 2018. 10 [26] Stephen Merity , Caiming Xiong, James Bradbury , and Richard Socher . Pointer Sentinel Mixture Models. International Conference of Learning Repr esentations , 2017. [27] Jeffre y Pennington, Richard Socher , and Christopher D. Manning. GloV e: Global V ectors for W ord Representation. Empirical Methods in Natural Language Pr ocessing , 2014. [28] Christopher Roth, Ingmar Kanitscheider , and Ila Fiete. Kernel rnn learning (kernl). International Confer ence Learning Repr esentation , 2019. [29] Bernhard Scholkopf and Alexander J. Smola. Learning with kernels. MIT Press , 2002. [30] Corentin T allec and Y ann Ollivier . Can Recurrent Neural Networks W arp Time? International Confer ence of Learning Repr esentations , 2018. [31] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V inyals, Alex Grav es, Nal Kalchbrenner , Andrew Senior , and Koray Ka vukcuoglu. W aveNet: A Generativ e Model for Raw Audio. , 2016. [32] Jordy van Enkhuizen, Arpi Minassian, and Jared W Y oung. Further evidence for Clock ∆ 19 mice as a model for bipolar disorder mania using cross-species tests of exploration and sensorimotor gating. Behavioural Brain Resear ch , 249:44–54, 2013. [33] Ashish V aswani, Noam Shazeer , Niki Parmar , Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser , and Illia Polosukhin. Attention Is All Y ou Need. Neural Information Pr ocessing Systems , 2017. [34] Guoyin W ang, Chunyuan Li, W enlin W ang, Y izhe Zhang, Dinghan Shen, Xinyuan Zhang, Ri- cardo Henao, and Lawrence Carin. Joint Embedding of W ords and Labels for T ext Classification. Association for Computational Linguistics , 2018. [35] Jin W ang, Liang-Chih Y u, K. Robert Lai, and Xuejie Zhang. Dimensional Sentiment Analysis Using a Regional CNN-LSTM Model. Association for Computational Linguistics , 2016. [36] Andrew Gordon Wilson, Zhiting Hu, Ruslan Salakhutdinov , and Eric P . Xing. Deep Kernel Learning. International Conference on Artificial Intellig ence and Statistics , 2016. [37] Xiang Zhang, Junbo Zhao, and Y ann LeCun. Character-lev el Con volutional Networks for T ext Classification. Neural Information Pr ocessing Systems , 2015. [38] Chunting Zhou, Chonglin Sun, Zhiyuan Liu, and Francis C.M. Lau. A C-LSTM Neural Network for T ext Classification. , 2015. 11 A More Details of the LFP Experiment In this section, we provide more details on the Sync-RKM model. In order to incorporate the SyncNet model [ 22 ] into our framework, the weight W ( x ) = W ( x 0 ) , W ( x − 1 ) , · · · , W ( x − n +1 ) defined in Eq. (12) is parameterized as wavelet filters. If there is a total of K filters, then W ( x ) is of size K × C × n . Specifically , suppose the n -gram input data at time t is giv en as X t = [ x t − n +1 , · · · , x t ] ∈ R C × n with channel number C and window size n . The k -th filter for channel c can be written as W ( x ) kc = α kc cos ( ω k t + φ kc ) exp( − β k t 2 ) (21) W ( x ) kc has the form of the Morlet w avelet base function. Parameters to be learned are α kc , ω k , φ kc and β k for c = 1 , · · · C and k = 1 , · · · , K . t is a time grid of length n , which is a constant vector . In the recurrent cell, each W ( x ) kc is con volv ed with the c -th channel of X t using 1 - d con volution. Figure 3 gi ves the frame work of this Sync-RKM model. For more details of how the filter works, please refer to the original work [22]. 𝑪 𝑻 1 𝑡 𝑇 S y nc - RKM S y nc - RKM S y nc - RKM … S y nc - RKM S y nc - RKM … 2 3 𝒉 𝒕 = 𝒇 𝑿 𝒕 + 𝑾 ( 𝒉 ) 𝒉 𝒕 − 𝟏 + 𝒃 𝑾 ( 𝒙 ) Figure 3: Illustration of the proposed model with SyncNet filters. The input LFP signal is giv en by the C × T matrix. The SyncNet filters (right) are applied on signal chunks at each time step. When applying the Sync-RKM model on LFP data, we choose the windo w size as n = 40 to consider the time dependencies in the signal. Since the experiment is performed by treating each mouse as test iterativ ely , we show the subject-wise classification accuracy in Figure 4. The proposed model does consistently better across nearly all subjects. Figure 4: Subject-wise classification accuracy comparison for LFP dataset. 12
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment