Estimating the Degree Centrality Ranking of a Node
Complex networks have gained more attention from the last few years. The size of real-world complex networks, such as online social networks, WWW network, collaboration networks, is increasing exponentially with time. It is not feasible to collect the complete data and store and process it. In the present work, we propose a method to estimate the degree centrality rank of a node without having the complete structure of the graph. The proposed algorithm uses the degree of a node and power-law exponent of the degree distribution to calculate the ranking. Simulation results on the Barabasi-Albert networks show that the average error in the estimated ranking is approximately $5%$ of the total number of nodes.
💡 Research Summary
The paper addresses the problem of estimating a node’s degree‑centrality rank in large, evolving complex networks without requiring full knowledge of the graph’s adjacency structure. Traditional rank computation would need to collect the degree of every vertex, sort them, and assign ranks, an O(n log n) operation that becomes infeasible for massive, dynamic networks such as online social platforms, the World‑Wide‑Web, or collaboration graphs. The authors propose a lightweight, sampling‑based approach that leverages only local information (the degree of the target node) together with a few global parameters that can be estimated from a small random sample of the network.
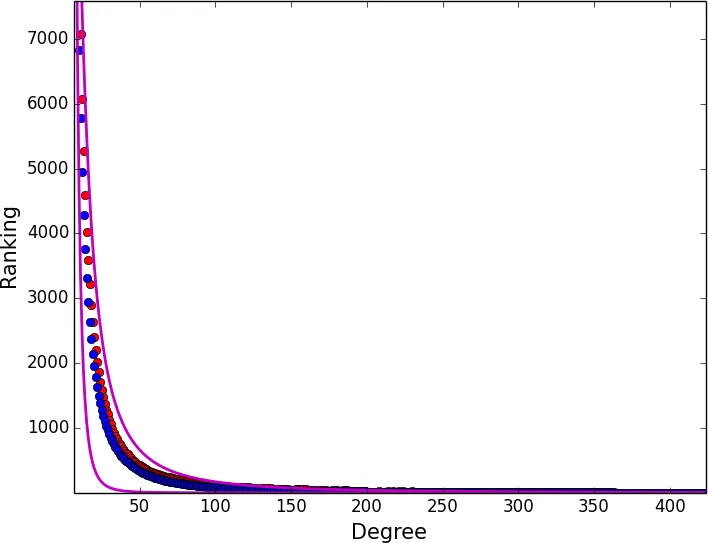
The methodological foundation rests on the Barabási‑Albert (BA) preferential‑attachment model, which generates scale‑free networks whose degree distribution follows a power‑law (f(k)=c,k^{-\gamma}) with exponent (\gamma) typically between 2 and 3. The authors first describe how to obtain three essential global quantities—total number of nodes (n), average degree (\bar d), and minimum degree (k_{\min})—using existing sampling techniques (random walks, induced‑edges, etc.). With these quantities, they analytically derive the normalization constant (c) and the power‑law exponent (\gamma). Specifically, by enforcing (\int_{k_{\min}}^{k_{\max}} f(k),dk = 1) and (\bar d = \int_{k_{\min}}^{k_{\max}} k f(k),dk), they obtain closed‑form expressions for (c) and (\gamma), the latter simplifying to (\gamma = 2 + \frac{k_{\min} - 1/2}{\bar d - k_{\min} + 1/2}) under the assumption that the maximum degree (k_{\max}) is large.
Given a node with observed degree (k), the probability that a randomly chosen other node has a higher degree is \
Comments & Academic Discussion
Loading comments...
Leave a Comment