Compiler-Level Matrix Multiplication Optimization for Deep Learning
An important linear algebra routine, GEneral Matrix Multiplication (GEMM), is a fundamental operator in deep learning. Compilers need to translate these routines into low-level code optimized for specific hardware. Compiler-level optimization of GEMM has significant performance impact on training and executing deep learning models. However, most deep learning frameworks rely on hardware-specific operator libraries in which GEMM optimization has been mostly achieved by manual tuning, which restricts the performance on different target hardware. In this paper, we propose two novel algorithms for GEMM optimization based on the TVM framework, a lightweight Greedy Best First Search (G-BFS) method based on heuristic search, and a Neighborhood Actor Advantage Critic (N-A2C) method based on reinforcement learning. Experimental results show significant performance improvement of the proposed methods, in both the optimality of the solution and the cost of search in terms of time and fraction of the search space explored. Specifically, the proposed methods achieve 24% and 40% savings in GEMM computation time over state-of-the-art XGBoost and RNN methods, respectively, while exploring only 0.1% of the search space. The proposed approaches have potential to be applied to other operator-level optimizations.
💡 Research Summary
The paper addresses the critical need for compiler‑level optimization of the General Matrix Multiplication (GEMM) operation, which is a cornerstone of deep‑learning workloads. While most deep‑learning frameworks rely on hand‑tuned, hardware‑specific libraries (e.g., cuDNN, NNPACK), such approaches limit portability and performance across the growing diversity of target devices. To overcome this limitation, the authors build on the TVM compilation stack and propose two novel search algorithms that automatically discover high‑performance GEMM configurations: Greedy Best‑First Search (G‑BFS) and Neighborhood Actor‑Advantage‑Critic (N‑A2C).
Problem formulation
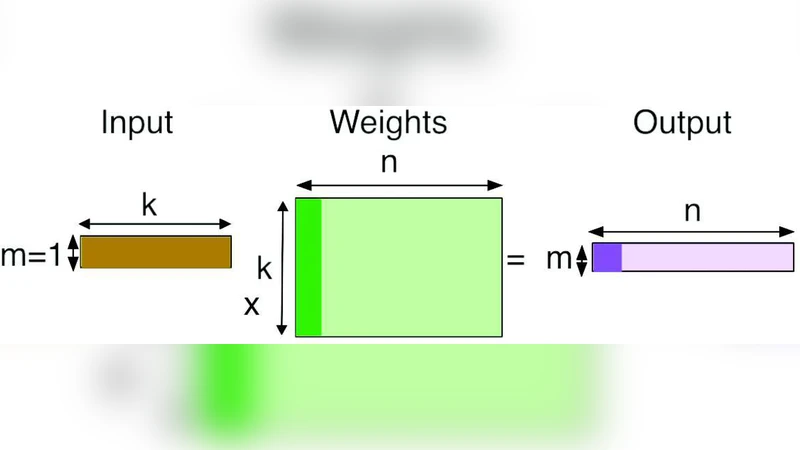
GEMM can be expressed as three nested loops over dimensions m, k, and n. Optimizing GEMM reduces to selecting tiling factors for each loop (the number of iterations at each level) that minimize runtime on a given hardware platform. The authors formalize a tiling configuration as a tuple ξ = (ξ_m, ξ_k, ξ_n) where each ξ_x is a factorization of the corresponding dimension (product of factors equals the original size). The search space is combinatorial and grows exponentially with the number of loop levels.
MDP modeling
The authors model the configuration space as a Markov Decision Process (MDP). A state s consists of the three factor vectors (s_m, s_k, s_n) together with a legality flag J. An action a modifies a pair of factors by doubling one and halving the other, preserving the product constraint. The transition function “step” maps (s, a) → s′, and the reward is defined as the negative runtime cost of the resulting configuration: r(s, a) = –cost(s′). This formulation captures the intuition that neighboring configurations (i.e., those differing by small factor adjustments) tend to have similar performance, enabling more focused exploration.
G‑BFS algorithm
G‑BFS maintains a priority queue ordered by observed runtime cost. Starting from a random or heuristically chosen configuration, the algorithm evaluates the cost, inserts the state into the queue, and repeatedly extracts the lowest‑cost state. For each extracted state, all admissible neighbor actions are applied, generating new candidate states that have not yet been visited. These candidates are evaluated and enqueued. The process stops after a predefined budget (e.g., 0.1 % of the total configuration space) or when no better states are found. Because the search is greedy yet guided by the cost‑ordered frontier, it quickly converges to high‑quality configurations with minimal evaluation overhead.
N‑A2C algorithm
N‑A2C treats the same MDP as a reinforcement‑learning problem. An Actor network proposes an action given the current state, while a Critic network estimates the expected return (negative runtime). The advantage function (actual reward minus Critic estimate) drives policy updates, encouraging actions that lead to lower runtime than predicted. Crucially, the action space is restricted to the defined “neighborhood” transformations, which dramatically reduces the exploration space and stabilizes learning. The algorithm iteratively samples trajectories, updates both networks, and gradually improves the policy toward configurations with minimal cost.
Experimental evaluation
Experiments are conducted on an NVIDIA Titan XP GPU using 1024 × 1024 matrix multiplication. The authors compare their methods against two state‑of‑the‑art TVM tuners: an XGBoost‑based tuner (the current TVM default) and an RNN‑controller tuner (previously shown to outperform random and evolutionary methods). Results show:
- G‑BFS achieves a 24 % reduction in GEMM runtime compared with the XGBoost tuner while evaluating only 0.1 % of the configuration space.
- N‑A2C achieves a 40 % reduction relative to the RNN‑controller tuner under the same evaluation budget.
- Both methods require substantially less search time than the baselines, demonstrating that intelligent exploitation of neighbor relations can dramatically accelerate the tuning process.
Broader impact and extensibility
The paper argues that the MDP formulation and neighbor‑based actions are not specific to GEMM; they can be generalized to other tensor operators such as convolutions and fully‑connected layers, which also admit loop‑tiling representations. Consequently, the proposed framework could be integrated into TVM to provide a unified, hardware‑agnostic optimizer capable of handling CPUs, GPUs, FPGAs, and ASICs without manual library development.
Conclusions
The authors contribute (1) a formal MDP model of GEMM tiling configurations, (2) two efficient search algorithms—G‑BFS and N‑A2C—that leverage the structure of the configuration space, and (3) empirical evidence that these methods outperform existing XGBoost and RNN‑based tuners while exploring a vanishingly small fraction of the search space. This work advances the state of the art in compiler‑level operator optimization and opens a path toward fully automated, portable performance tuning for deep‑learning workloads.
Comments & Academic Discussion
Loading comments...
Leave a Comment