Explaining Visual Models by Causal Attribution
Model explanations based on pure observational data cannot compute the effects of features reliably, due to their inability to estimate how each factor alteration could affect the rest. We argue that explanations should be based on the causal model o…
Authors: Alvaro Parafita, Jordi Vitri`a
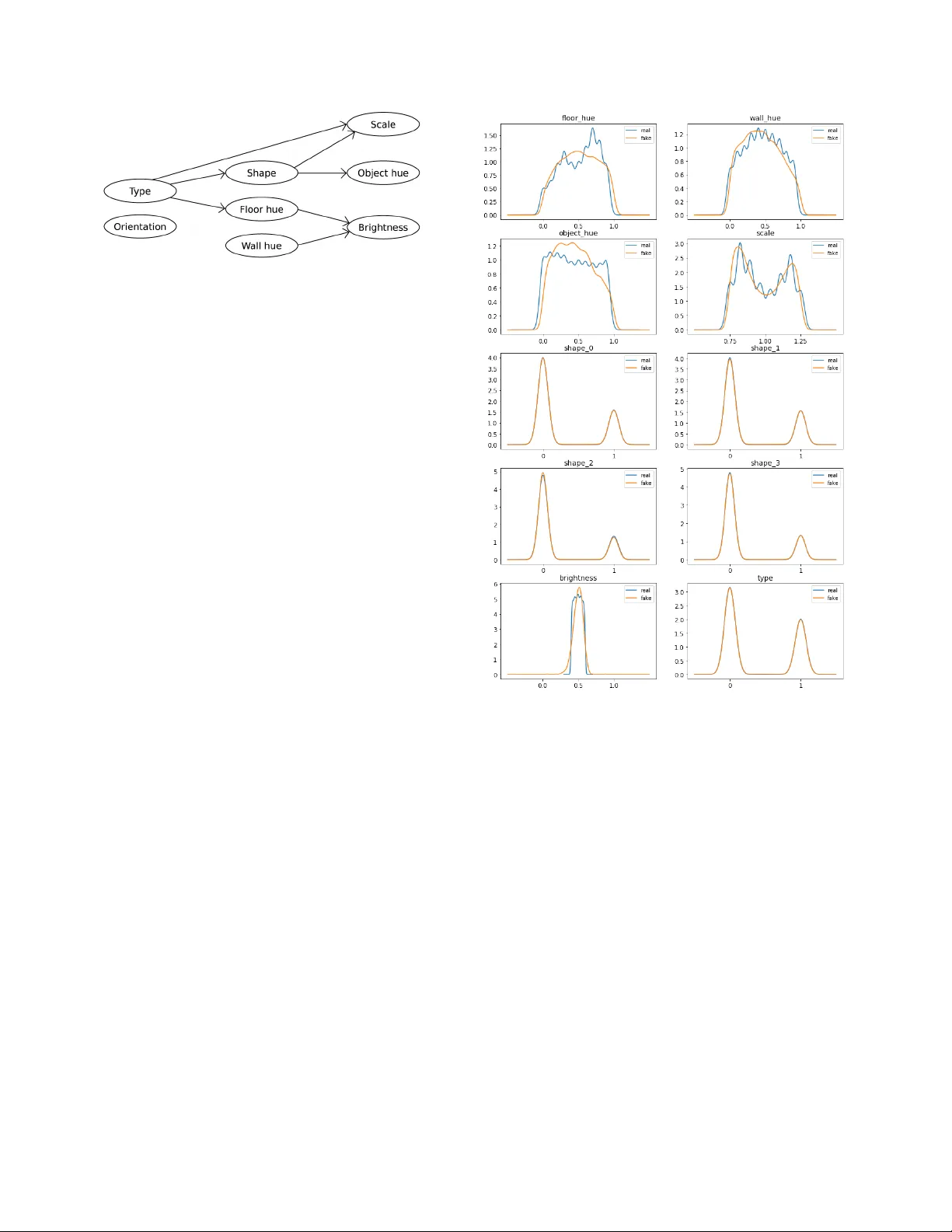
Explaining V isual Models by Causal Attrib ution ´ Alv aro Parafita, Jordi V itri ` a Uni versitat de Barcelona { parafita.alvaro,jordi.vitria } @ub.edu Abstract Model explanations based on pur e observational data cannot compute the effects of featur es r eliably , due to their inability to estimate how each factor alteration could af fect the r est. W e ar gue that e xplanations should be based on the causal model of the data and the derived intervened causal models, that r epr esent the data distrib ution subject to inter - ventions. W ith these models, we can compute counterfactu- als, new samples that will inform us how the model r eacts to featur e changes on our input. W e pr opose a novel expla- nation methodology based on Causal Counterfactuals and identify the limitations of curr ent Imag e Generative Models in their application to counterfactual cr eation. 1. Introduction The field of Machine Learning (ML) Interpretability has been gaining traction ov er recent years due to the prolifera- tion of ML applications in a wide range of uses. Ho wev er , there is no common notion of what interpretability means, or what does it entail. Lipton [ 13 ] distinguishes two types of interpretability: transparenc y and post-hoc explanations. W e will focus on the latter , specifically on the definition of a system capable of attributing the effect of feature alterations to the outcome of a predictor . Although the technique is general (from regression to classification; from tab ular data to image data), in this paper we will only cover its applica- tion to Deep Learning image classifiers. As an example, consider a CNN image classifier that tries to predict the gender of a person from a face. Our ob- jectiv e is not to optimize the classifier , but to explain what affects its prediction for specific faces. Assuming we know certain factors about the face ( i.e . hair colour , age, use of makeup or presence of facial hair), we are interested in de- tecting which of these latent factors (variables that describe the image b ut which are not included in the input) are re- sponsible for the outcome of the classifier . This contrasts with the problem of saliency , where pixels are sorted by im- portance with respect to the result of the prediction. Here we attribute more semantically-charged aspects of the in- Figure 1. Explanation of visual models by counterfactuals needs to consider the causal structure of the data in terms of meaningful latent factors. It is by applying interventions on this causal model that we create a ne w , intervened model on which we can base gen- erators to create causal counterf actual images. In this example, by intervening on shape, scale increases as well. put, its latent factors, since those are the ones that can be interpreted and understood by the human user . Specifically , we will answer questions of the type: Giv en the fact that this face belongs to a woman, has been classified as a woman and the person does not have a beard, how would the classifier’ s prediction hav e changed had there been a beard? In the field of Causality (refer to the book by Pearl [ 16 ]), this is referred to as Counterfactual reasoning. The idea is to consider alternative worlds where certain aspects ha ve changed independently of their underlying causes (this is what we call an intervention ), but the rest of the variables will be unaltered except for those that are af fected by the intervention we made. This is a Causal Counterfactual. W e find that these contrastiv e questions are the key to explaining the effects of factors on a predictor . Figure 1 summarizes our vie ws on the importance of causal models for the computation of counterfactuals. Assume we ha ve an image to explain, along with its corresponding latent fac- tors. W e want to compute the effects of certain interventions (modifications on some of the latent factors) on the classi- fier prediction. These interv entions alter the causal model 1 in which we work: from the original one, that represents our dataset, to the intervened one, that contains the desired intervention. Counterfactuals are, in fact, samples from that intervened model adjusted to the input we want to study . By taking sev eral of these samples (ne w latent factors) we can generate, through a Counterfactual Image Generator , ne w images that contain the intervention we made, along with any other factors affected by this intervention. Finally , these modified (counterfactual) images pass through the classifier to obtain different predictions, and by aggre gating them we obtain the average ef fect of the interv ention on the classifier , for the original input image that we want to explain. Notice that the original causal model and the inter- vened one may result in significantly different distributions. Therefore, only by considering the causal graph can we re- ally sample from the intervened model, where counterfactu- als li ve. A non-causal generator would sample from the ob- servational data, represented by the original causal model, but it would not accommodate for the causal effects of our interventions. The computation of effects of interventions on the final predictor allo w us to explain why a certain prediction was made. If we notice that by intervening on a factor the pre- diction changes significantly , we can say that the current value for that factor is a cause for the current prediction. Not only that, b ut we also know what could change in or- der to alter the outcome of the classifier . Additionally , this technique can be applied to detect classifier biases or un- fairness in its assessment ( i.e ., race as a factor in recidi vism prediction). Lastly , for clarification, it is important to note that the term counterfactual has been used with very dif ferent mean- ings across the literature. As an example, Sundarajan et al . [ 17 ] used it to refer to interpolations between an image and a baseline (a blank picture), as a way to estimate the gra- dient of the classifier in non-saturated re gions of the input. W achter et al . [ 18 ] and Goyal et al . [ 7 ], on the other hand, consider a counterfactual as an image similar to the original one but resulting on a different prediction. The difference with the definition in Causal Theory is subtle, but decisiv e: causal counterfactuals stem from an interv ention on the f ac- tors of the causal model, whilst W achter and Goyal’ s result from looking for a dif ferent outcome of the predictor , and only then do the y look at the factors. Their use of those counterfactuals is to compare between the original input and the new one, to highlight the differences between them as the reasons for the change in classification. This, howe ver , does not take into account that some changes might appear in order to make the true causal factor more likely , con- founding the real causal factor with a non-causal one. Only by intervention can we really estimate the ef fect of a factor . Our contributions are threefold: 1. W e define a method for implementing Causal Graphs with Deep Learning that allo ws sampling from the ob- servational model and any interv ened model. Addi- tionally , we can also estimate the log-lik elihood of an y sample. Both operations allow backpropagation, so they can be used as parts of even more complex mod- els. As far as we know , this approach is novel in Deep Learning; we call this method Distrib utional Causal Graphs. 2. W e define a ne w explanation technique for visual mod- els based on latent factors, using the previously defined graphs and a Counterfactual Image Generator . 3. W e identify the limitations of current Conditional Im- age Generators for Counterfactual Generation and enu- merate the requirements for such a model. 2. Related work The use of contrastive techniques for attribution (com- paring the image of study to another with certain features changed) is well extended in the literature. Zeiler et al . [ 19 ] and Ancona et al . [ 1 ] use pix el masking (replacing certain pixels with constant, blank v alues) to measure classifier de- pendency on certain pixels. In this case, they compare the original image with a masked one. Chang et al . [ 3 ] also use pixel masking, not only by replacing with a constant value, random noise or by blurring the masked region, but by in- filling it with probable values with respect to the remaining parts of the image. This in-filling is done via Generativ e Models. Counterfactuals understood in the sense of minimal al- terations to change classifier prediction are used in the aforementioned W achter et al . [ 18 ] and Goyal et al . [ 7 ], but also in Mothilal et al . [ 14 ]. This latter case also men- tions the importance of counterf actual div ersity (obtaining div erse counterfactual images that manage to change clas- sifier prediction) and counterfactual feasibility (lik elihood that such a counterfactual exists or that the intervention nec- essary is feasible to ex ecute). Parallel work by Denton et al . [ 4 ] conceiv es counterfac- tuals in the sense of altering just one of the latent factors and estimating its effect. Ho wev er , their work does not take into account the causal dependencies resulting from this trans- formation, and the use of their technique is limited to in- terventions of single variables. Their approach is similar to TCA V (Kim et al . [ 9 ]): computing vectors that encode each feature of interest and moving along this direction to study the ef fects on the classifier . Although the latter uses them in the space of layer activ ations inside the classifier , the former works in the latent space of a Generati ve Adversarial Net- work (Goodfellow et al . [ 6 ]), so that the changes produced by the explanation technique still result in realistic images. In terms of Counterfactual Image Generators, Causal- GAN [ 11 ] uses a Causal Controller to inform a Conditional GAN of which latent factor configurations to use in the gen- eration of new images. Our Causal Graph is based on their Causal Controller with a redefinition to allow for the com- putation of the log-lik elihood of an y latent factor sample. Their generator, howe ver , is not sufficient for the computa- tion of ef fects of interventions, as discussed in the following sections. W e will also comment on Fader Networks (Lam- ple et al . [ 12 ]) and AttGAN (He et al . [ 8 ]) as Conditional Image Generators, and their limitations in the application to Counterfactual Image Generation. 3. Background W e start our exposition with a brief introduction to the framew ork of causality focused on our specific application. Consider a set of random v ariables V = { X 1 , . . . , X n } and a set of exogenous random v ariables E = { E 1 , . . . , E n } . W e assume that the variables in E are mutu- ally independent and also independent to any variable in V other than their corresponding one, meaning ∀ i 6 = j, E i ⊥ ⊥ E j , E i ⊥ ⊥ X j but E i 6⊥ ⊥ X i . W e define a probability distri- bution over the e xogenous variables, P E ( e ) , while V is de- fined by a set of deterministic functions F = ( f 1 , . . . , f n ) , one for each of the variables in V . Each function f i relates their corresponding variable X i to its causes (other v ari- ables in V ) and the corresponding e xogenous noise v ariable E i . Therefore, if P a i , ∅ ⊆ P a i ( V , denotes the set of causes of X i , X i = f i ( P a i , E i ) . Therefore, f i is a de- terministic function relating the value of variable X i to the value of each of its causes P a i , plus an independent, e x- ogenous noise v ariable E i that accounts for the stochastic- ity of the relationship. Altogether , this framework allows us to define what Pearl [ 16 ] calls a Structural Causal Model M = ( V , E , F , P E ) . Note that the set of functions F defines a directed graph G = ( V ∪ E , E ) where E = { ( V j , V i ) | ∀ i = 1 ..n, ∀ j : V j ∈ P a i } ∪ { ( E i , V i ) | ∀ i = 1 ..n } . The set of edges that conv erge in a node defines the causal dependencies of that node ( P a i ) and the stochastic component of that rela- tionship ( E i ). W e will only consider graphs with no cycles; therefore, we study Structural Causal Models whose implic- itly defined graphs G are Directed Acyclic Graphs (DA G). For notational simplicity , we assume that nodes are sorted in a way that all parents of a node must have a lower index than that node. Since the graph is a DA G, a topological or- dering of the graph induces such an inde x order . Therefore, ∀ i 6 = j, X j ∈ P a i → j < i . As an e xample, consider the graph in figure 2 . W e are interested in determining when the floor will be slippery ( X 5 ). W e know that the floor is slippery when it is wet ( X 4 ), and it can be wet either because there has been rain ( X 2 ) or because our neighbours’ sprinkler has been acti- vated ( X 3 ). Finally , we know that rain probability depends on the current season ( X 1 ), and that our neighbours only Figure 2. W et floor example, proposed in [ 16 ]. The gray arrow represents the one that disappears when intervening on Sprinkler , creating the new interv ened model. program their sprinkler in non-rainy seasons. Therefore, we can infer causal relationships between our variables, such as the ones depicted in the graph in Figure 2 . Note that we omit the exogenous set of noise variables E from graph vi- sualizations because there are no edges between them and other nodes other than their corresponding ones, so their presence is implicit. Interventions in causal theory mean fixing the values of certain nodes (independently of the v alue of their parents) and perform predictions on the remainder of the graph. In- terventions can be understood as removing any edges lead- ing to the intervened nodes (both from v ariables in V and E ) and specifying the v alue that node ought to take. This allows to ask questions such as: ”will the floor be slip- pery if we turn of f the sprinkler?”. Interventions are de- noted as do ( X = x ) . In our example, the intervention is do ( sprinkler = off ) . Counterfactuals, on the other hand, are always based on a specific sample and an intervention to apply . Giv en both, we fix the noise signals ( E ) according to the sample, per- form the gi ven intervention and run predictions on the re- sulting model. This allows to ask questions such as: ”giv en that we kno w that the floor was slippery , the season is sum- mer , it has not rained today and the sprinkler was on, w ould the floor still ha ve been slippery had we turned the sprin- kler off?”. In this case, we perform the same interv ention but the noise signals are conditioned on the fact that we saw the initial given sample. In the counterf actual w orld (the model with the applied intervention and the affected noise signals), rain is independent to the sprinkler state and it has not rained, therefore, rain cannot ha ve started in any coun- terfactuals. Since the sprinkler was not activ ated and it has not rained, the floor cannot be wet and, consequently , it can- not be slippery either . The intervened causal model we will use to sample coun- terfactuals can be defined from modified sets b F and P b E . Giv en the original P E ( E 1 , . . . , E n ) and the input on which we base the counterfactual, x = ( x 1 , . . . , x n ) , we condi- tion the noise v ariables E = ( E 1 , . . . , E n ) on the current observation x . Therefore, the counterfactual model has an exogenous variable distribution P b E ( e ) = P E ( e | x ) . Now , giv en an intervention do ( X i = x 0 i , ∀ i ∈ I ) , the set of de- terministic functions F is replaced by b F = { f i ∈ F | ∀ i 6∈ I } ∪ { b f i := ( X i = x 0 i ) | ∀ i ∈ I } . This replaces any functions that defined the intervened variables with a simple assignment to the intervention v alue. Therefore, giv en a sample x and an intervention do ( X i = x 0 i , ∀ i ∈ I ) , counterfactual inference means computing predictions on a new Structural Causal Model c M = ( V , E , b F , P b E ) with b F , P b E defined as abov e. Figure 2 sho ws the intervened model if we omit the gray edge, which points to the intervened v ariable Sprinkler . In that setup, Sprinkler becomes independent of Rain, which was not true in the original causal model, which reflected our observational data. 4. Proposed method This section is divided in three subsections, correspond- ing to the different parts of our attrib ution method. W e be- gin with our Distributional Causal Graph, which will allow us to sample and compute lik elihoods of the samples. After- wards, we will cover the requirements for a Counterfactual Image Generator and the limitations of current approaches. Finally , we will detail the process through which we can es- timate the ef fects of interv entions and, therein, compute the attribution of latent f actors. 4.1. Distributional Causal Graph (DCG) Our objective is to explain predictions of an image clas- sifier , but these explanations will be based on latent factors, meaning, a set of descripti ve random v ariables (both dis- crete and continuous) that express semantically-charged as- pects of the input. W e assume that these factors are known for all instances in our training data, either through a clas- sifier that predicts them or by being present in the dataset. They are interdependent in a causal way and we kno w a causal graph that describes their relationship. As said be- fore, we omit any possible cycles in their causal relation- ships, hence the graph must be a D A G. Our approach to modeling this graph is based on the Causal Controller from K ocaoglu et al . [ 11 ]: each node is represented by a Multilayer Perceptron (MLP). The input of this MLP is all of its parent values (if any) concatenated as consecuti ve v ector dimensions, with the additional con- catenation of the corresponding e xogenous noise v ariable. In the case of K ocaoglu’ s Causal Controller, the output of the MLP is a sample of the latent factor . Our DCG di ver ges from their implementation in terms of input and output of each node. First, we need to make additional assumptions about the data in order to proceed. In the e xample from Figure 2 , all variables are discrete, binary variables. All of them can be modelled as Bernoulli distributions, except for X 1 , Season , which is a 4-dimensional Cate gorical distribution. Then, each of our MLP outputs will be an estimation of the dis- tribution parameters of the corresponding node, depending only (using as input) on its parent node samples. In the ex- ample, this means that all nodes except for X 1 will be rep- resented by an MLP that takes its parent values and returns the parameter p that represents the probability of the node achieving v alue 1, under the current circumstances. X 1 , on the other hand, will output 4 different probability parame- ters, ( p j ) j =1 .. 4 , that represent the probability of each possi- ble outcome (each of the seasons). Making distributional assumptions about the v ariables in the Causal Graph allows us to compute log-probabilities of any latent factor sample. Due to the D A G structure and the fact that all variables in E are independent, we kno w that ( X i ⊥ ⊥ X j | P a i ) , ∀ i = 1 ..n, ∀ j < i, X j 6∈ P a i . This is easily demonstrable using d-separation [ 16 ], since any path between non-immediately-connected nodes must pass through one of the parents of node X i . Accordingly , P ( X = ( x 1 , . . . , x n )) = Q i =1 ..n P ( X i = x i | X j = x j , ∀ X j ∈ P a i ) . Each of these probability terms can be computed using the PMF (for discrete variables) or the PDF (for continuous variables) of the corresponding distri- bution, using the estimated parameters from the correspond- ing MLP network. In other words, if θ i represents the pa- rameter(s) of node X i ’ s distribution, which is the output of the MLP f i , θ i = f i ( X j = x j , ∀ X j ∈ P a i ) . Therefore, log P ( X = ( x 1 , . . . , x n )) = P i =1 ..n log P ( X i = x i | θ i ) . This tells us ho w to compute distribution parameters and log-likelihoods, but not how to sample. Notice that we do not use an y e xogenous noise in the estimation of parameters θ i . That is because the noise signal is reserv ed to sampling. Follo wing the same line as the reparametrization trick in Kingma et al . [ 10 ], we assume that each e xogenous noise signal E i is a parameter-independent sample that we transform, using the parameters θ i and an appropriate transformation function, to sample from the target distri- bution. Let us suppose a univ ariate Gaussian node X i ∼ N ( µ ( P a i ) , σ ( P a i )) . Then, giv en a noise signal e i sam- pled from a N (0 , 1) prior , x i can be sampled by comput- ing the following deterministic, differentiable e xpression: x i = µ ( P a i ) + σ ( P a i ) · e i . This trick allo ws us to backprop- agate from a sample to its parameters, therefore allowing optimization with Gradient Descent techniques, e ven from the log-likelihood of the sample (as long as the PMF/PDF is differentiable). Note that any distribution that allows such an operation, sampled from any other independent distribution (not nec- essarily Gaussian) can automatically be used in this frame- work. Bernoulli and Categorical distributions can be sam- pled through the use of the so-called Gumbel T rick (Papan- dreou & Y uille [ 15 ]). Implicit Reparametrization Gradients (Figurnov et al . [ 5 ]) offers an alternative method that allo ws, in particular , sampling from any distribution with a differen- tiable CDF , such as Truncated Univ ariate Normal Distribu- tions, mixtures of reparametrizatable distributions, Gamma, Student’ s t or even V on Mises distributions. Hence, as long as we are able to sample differentiably from a parametric distribution, we can apply it to our DCG. Additionally , if the corresponding PMF or PDF is dif ferentiable with respect to the distrib ution’ s parameters, we can ev en backpropagate through log-likelihoods of latent factor samples. In order to train the DCG, we use Maximum Likelihood Estimation. W e compute the output of each node using the samples from our dataset as parent values. If we have a sam- ple x = ( x 1 , . . . , x n ) , we obtain the distribution parameters by running the MLP to obtain θ i = θ i ( x j : ∀ j, X j ∈ P a i ) . Then, we can compute the log-likelihood of the whole sam- ple and use the mean log-likelihood of a batch as a maxi- mizing objectiv e for optimization. 4.2. Counterfactual Image Generator The next step in the process is to translate a latent f ac- tor sample into an image. Howe ver , not any image suffices. Our latent factor model might not describe an image com- pletely , and the same vector might relate to sev eral dif fer- ent examples. Therefore, we need the original image as an anchor of the generati ve process, so that the resulting coun- terfactual is both similar to the original input (preserving those factors that the causal model does not consider) and also fulfills the demands of the counterfactual latent factor vector that we created with the DCG. Hence, the structure of a Counterfactual Image Genera- tor asks for an image and a counterfactual latent factor as in- put. The output must fulfill the latent factor (we could train an image classifier that checks if the required f actors and the resulting factors match) and it should be similar to the origi- nal image. This similarity , ho wev er, cannot be simply an L 2 or L 1 loss, since the differences created by the latent factor might create significant changes in the image that these two losses cannot ignore. Therefore, one needs to identify the remaining latent factors (not present in the causal model) and then the comparison between images should only take into account these factors. There are sev eral proposals in the literature that, in prin- ciple, could be accommodated to this use case, but tests re- vealed that their training method and/or architecture would not fulfill the requirements. CausalGAN (K ocaoglu et al . [ 11 ]) uses a GAN architecture coupled with a Causal Con- troller Graph. Since the GAN only recei ves a random noise vector and the latent factors, it cannot be anchored to the image of study and the result can be extremely dif ferent to the original image. One could e xtend the original archi- tecture to include an Encoder network, along with a recon- struction f actor that assures the anchoring of the original image. Ho wever , this approach is similar to the two follo w- ing ones, which did not prove ef fective. In any case, we do not dismiss the potential of the CausalGAN approach for this use case and might ev en study it further in future research. Fader Networks [ 12 ] and AttGAN [ 8 ] are the two other examples we have considered. Both use an Autoencoder architecture to try to solve the problem of attribute editing in images. The former adds a critic in the hidden latent code (the output of the encoder) as a way of ensuring that the decoder learns to use the editing factors in the generated image. The latter adds the critic to the actual output, stating that the approach of Fader Networks, that try to ensure that the hidden latent code is independent of the editing factors, is too restrictive. Instead, the y use a critic as adversarial loss (to generate realistic images), a classifier to adjust to the required editing factors and a reconstruction loss to anchor to the original image. Both approaches av oid the problem of using a recon- struction loss on the factor-altered version of the image, since they can pass the original editing v alues to try to re- construct the original image. Howe ver , in that way there exists a tension between the reconstruction of the anchor - ing image and the generation of new samples, that, in our experiments, renders them too sensiti ve to the weights ap- plied to each loss term. W e ar gue that this could be a reason behind the fact that the quality of their images decreases significantly as more factors are considered ( i.e . edition on moustache, makeup and eye glasses at the same time). It is not necessarily a problem in the image editing setting, but when trying to create counterfactual images, one needs to alter all factors at once, since any intervention can poten- tially af fect multiple factors at the same time. As a result, the quality of the counterfactuals is vastly affected and their validity for interv ention effect estimation is compromised. Additionally , these two approaches suffer from a more significant drawback. Since the y train using an Adversar - ial Loss, any non-realistic image is penalized and, there- fore, not properly trained. This might happen with any lo w- probability factor configuration, as ”woman with mous- tache” in a celebrities face dataset. Therefore, if one wants to estimate the ef fect of the appearance of a moustache in the image of a woman, the generator might not achiev e this transformation or might start removing attributes that con- form with their notion of womanhood so that the resulting image can include the moustache. This specific example is actually achie ved in AttGAN, but as more attributes are considered the quality and feasibility of the edit decreases. CausalGAN, on the other hand, is prepared for this kind of edits, since its generator is attached to a trained Causal Graph that allows for such an intervention. This highlights the importance of taking into account the causal structure of the data: if an interv ention is possible, the generator must learn to perform it. That is why causal blindness is a signif- icant drawback of the pre vious two approaches. In conclusion, this analysis highlights the desiderata for a Counterfactual Image Generator . As far as we kno w , there is no approach in the literature that accomplishes these re- quirements, which motiv ates further research on the topic. • Causal Generator: consider an y configuration sampled from an arbitrary interv ention, e ven if it is not lik ely in the observ ational data, because it might be in the intervened, counterfactual model. • Reconstruction loss applied only on latent factors not present in the causal graph: any f actor present in the graph must be ignored in the reconstruction loss, since it is subject to change in the edited image. • Adv ersarial training: non-realistic but correctly classi- fied images (with respect to the factor classifier) might appear without a critic to discard them. As a final note, it is worth mentioning that other kinds of problems ( i.e . tab ular data) do not need a generator at all, since the result from the DCG can be the input itself. There- fore, only problems with a separation between actual input and latent factors ( i.e . vision tasks) require this additional generator . 4.3. Effect estimation The final part in our method is to compute the effects of any interv ention on the classifier . In order to do that, we need to discuss how to compute counterf actuals in a DCG. Causal theory normally considers exogenous noise vari- ables ( E ) as tin y perturbations in the sample due to unac- counted causes of each node. As a result, when computing counterfactuals, it is reasonable to preserv e such noise sig- nals and only change the values of the nodes af fected by an intervention. That is the abduction step in the three-step process of Counterfactuals proposed by Pearl [ 16 ]. This is not the case in DCGs. Here, we assume that each node encodes a gi ven distribution, and the noise signal is the mechanism to sample from that distribution. Howe ver , the actual function used for sampling from the independent noise signal to the node’ s distrib ution specified by its pa- rameters induces an unavoidable bias in the assignment of the value. Consider , as an example, a Cate gorical variable of 3 cat- egories determined by parameters p = ( p 1 , p 2 , p 3 ) , with P i =1 .. 3 p i = 1 . If the noise signal e comes from a Uniform distrib ution, e ∼ U (0 , 1) , one way to sample from Cate gorical ( p 1 , p 2 , p 3 ) is to perform the operation f ( p 1 , p 2 , p 3 , e ) = 1 · 1 p 1 ≤ X
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment