Interpretable Deep Learning under Fire
Providing explanations for deep neural network (DNN) models is crucial for their use in security-sensitive domains. A plethora of interpretation models have been proposed to help users understand the inner workings of DNNs: how does a DNN arrive at a specific decision for a given input? The improved interpretability is believed to offer a sense of security by involving human in the decision-making process. Yet, due to its data-driven nature, the interpretability itself is potentially susceptible to malicious manipulations, about which little is known thus far. Here we bridge this gap by conducting the first systematic study on the security of interpretable deep learning systems (IDLSes). We show that existing \imlses are highly vulnerable to adversarial manipulations. Specifically, we present ADV^2, a new class of attacks that generate adversarial inputs not only misleading target DNNs but also deceiving their coupled interpretation models. Through empirical evaluation against four major types of IDLSes on benchmark datasets and in security-critical applications (e.g., skin cancer diagnosis), we demonstrate that with ADV^2 the adversary is able to arbitrarily designate an input’s prediction and interpretation. Further, with both analytical and empirical evidence, we identify the prediction-interpretation gap as one root cause of this vulnerability – a DNN and its interpretation model are often misaligned, resulting in the possibility of exploiting both models simultaneously. Finally, we explore potential countermeasures against ADV^2, including leveraging its low transferability and incorporating it in an adversarial training framework. Our findings shed light on designing and operating IDLSes in a more secure and informative fashion, leading to several promising research directions.
💡 Research Summary
This paper, titled “Interpretable Deep Learning under Fire,” presents the first systematic study on the security vulnerabilities of Interpretable Deep Learning Systems (IDLSes). IDLSes combine a deep neural network (DNN) classifier with an interpretation model (interpreter) to provide explanations for the DNN’s predictions, which is crucial for building trust and enabling use in security-sensitive domains. However, the paper reveals that this very interpretability can be exploited as a new attack surface.
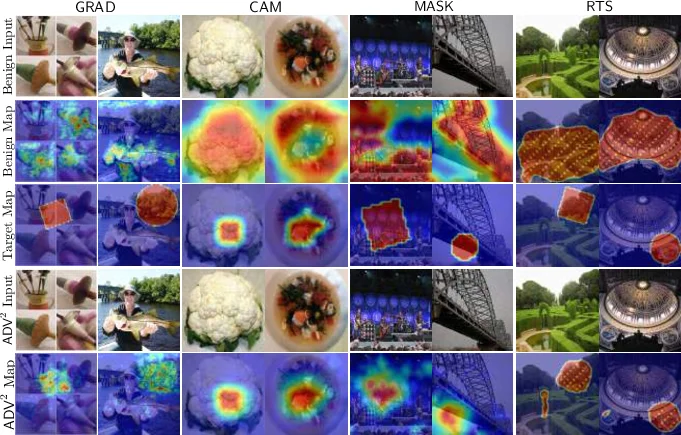
The core contribution is the introduction of ADV^2, a novel class of adversarial attacks. Unlike traditional attacks that only fool the target DNN, ADV^2 generates adversarial inputs that simultaneously mislead the classifier’s prediction and deceive its coupled interpreter into producing a specific, attacker-desired explanation (attribution map). The attack is formulated as an optimization problem that minimizes a combined loss function, incorporating both a prediction loss (to cause misclassification) and an interpretation loss (to manipulate the explanation). The paper details practical implementations of ADV^2 against four major types of interpreters: back-propagation-guided (e.g., Grad), representation-guided (e.g., CAM), model-guided, and perturbation-guided (e.g., LIME).
Through extensive empirical evaluation on benchmark datasets (ImageNet, CIFAR-10) and a security-critical application (skin cancer diagnosis using the ISIC 2019 dataset), the authors demonstrate the high effectiveness of ADV^2. Attackers can successfully craft inputs that are not only misclassified into an arbitrary target class but also generate interpretations that are visually similar to those of benign inputs or match an arbitrary target pattern, thereby evading detection mechanisms that rely on interpretation anomalies.
The paper identifies a fundamental root cause for this vulnerability: the “prediction-interpretation gap.” This gap arises because the interpreter is often a simplified model that only partially explains the complex, non-linear decision-making process of the DNN classifier. The misalignment between the two models creates opportunities for adversaries to find inputs that exploit both simultaneously. The authors analyze this gap and its implications for designing robust interpreters.
Finally, the paper explores potential countermeasures. A key finding is the low transferability of ADV^2 attacks across different interpreter types, suggesting that employing an ensemble of diverse interpreters could be a promising defense strategy. Furthermore, the authors propose “Adversarial Interpretation Distillation (AID),” an adversarial training framework that integrates ADV^2 attacks during the interpreter’s training process. Preliminary results show that AID can help reduce the prediction-interpretation gap and enhance the interpreter’s robustness against such dual-purpose attacks.
In conclusion, this groundbreaking work sounds a critical alarm for the secure deployment of interpretable AI. It establishes that interpretability does not automatically confer security and can, in fact, introduce new vulnerabilities. The findings underscore the urgent need for future research to focus on the robustness of explanation methods alongside their explanatory power, paving the way for designing IDLSes that are both informative and secure.
Comments & Academic Discussion
Loading comments...
Leave a Comment