OpenReq Issue Link Map: A Tool to Visualize Issue Links in Jira
Managing software projects gets more and more complicated with an increasing project and product size. To cope with this complexity, many organizations use issue tracking systems, where tasks, bugs, and requirements are stored as issues. Unfortunately, managing software projects might remain chaotic even when using issue trackers. Particularly for long lasting projects with a large number of issues and links between them, it is often hard to maintain an overview of the dependencies, especially when dozens of new issues get reported every day. We present a Jira plug-in that supports developers, project managers, and product owners in managing and overviewing issues and their dependencies. Our tool visualizes the issue links, helps to find missing or unknown links between issues, and detects inconsistencies.
💡 Research Summary
The paper addresses the growing difficulty of managing dependencies in large‑scale software projects that rely on issue‑tracking systems such as Jira. In massive installations—illustrated by the Qt Company’s Jira instance with over 110 k issues and nearly 25 k links—users can only view direct links on an issue’s page, making it hard to understand transitive relationships, detect missing or duplicate links, and ensure release‑plan consistency. To tackle these challenges, the authors present the OpenReq Issue Link Map, a service‑based Jira plug‑in that combines graph visualization, automated link detection, and consistency checking.
The system’s architecture consists of a web‑based front‑end and several micro‑services on the back‑end. The “graph of links” service maintains a real‑time graph representation of all issues and their links, enabling fast retrieval even for very large datasets. The “link detection” service generates candidate links in two ways: (1) by comparing issue titles and descriptions using text‑similarity techniques (TF‑IDF or embedding‑based cosine similarity) to suggest duplicate issues, and (2) by scanning issue comments for references to other issue keys, which often indicate a relationship that has not been formally linked. The service returns the top five recommendations, which users can accept or reject and assign an appropriate link type.
The “consistency checker” encodes release‑planning constraints as a constraint‑solving problem. It enforces that child issues must not be scheduled for a later release than their parent if they have equal or higher priority, that required (dependency) issues must appear in the same or an earlier release, and that duplicate issues inherit all links of the original. A SAT/SMT solver evaluates the current issue map against these constraints and highlights any violations together with the implicated releases.
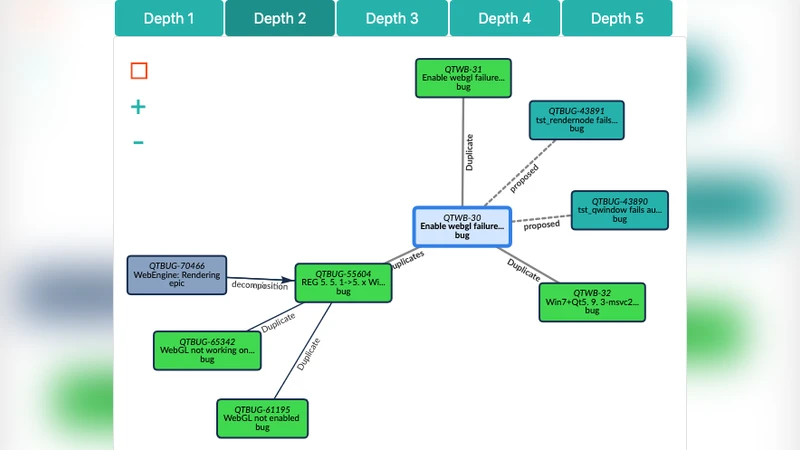
The user interface displays the issue map as an interactive graph on the left side, with a depth selector that limits the radius of exploration from the selected issue. Clicking any node re‑centers the view, allowing users to navigate the network intuitively. The right‑hand pane shows the selected issue’s metadata and provides tabs for “Link Detection” and “Consistency Checker.” When link detection is invoked, the recommended links appear as a list; acceptance triggers an automatic creation of the link in Jira after the user specifies its type. Consistency checking produces a visual report of constraint violations, making it easy for project managers to spot problematic dependencies before a release. Additional filters let users narrow the graph by attributes such as status, assignee, or priority.
A pilot evaluation with the Qt Company began in early 2018. The tool has already demonstrated value: for example, issue QTBUG‑55604, which shows only three direct links in the native Jira view, is revealed to have 19 transitive connections in the map, exposing hidden dependencies that could affect release decisions. Users reported that the visual overview reduces the time spent manually traversing issue chains and that the automated duplicate detection helps avoid redundant work.
The authors acknowledge current limitations. Text‑based duplicate detection can produce false positives or miss subtle duplicates, and rendering very large graphs may strain browser performance. Future work includes a human‑in‑the‑loop learning loop that refines the recommendation model from user feedback, an “auto‑repair” feature that suggests concrete actions to resolve detected inconsistencies, and performance optimizations such as WebGL‑based graph rendering. They also plan longitudinal studies on user acceptance of AI‑driven assistance in issue tracking.
In summary, OpenReq Issue Link Map offers a novel combination of visualization, AI‑assisted link recommendation, and formal consistency checking, providing a practical solution to the information‑overload problem inherent in large‑scale requirements engineering and issue management.
Comments & Academic Discussion
Loading comments...
Leave a Comment