Learning Index Selection with Structured Action Spaces
Configuration spaces for computer systems can be challenging for traditional and automatic tuning strategies. Injecting task-specific knowledge into the tuner for a task may allow for more efficient exploration of candidate configurations. We apply this idea to the task of index set selection to accelerate database workloads. Index set selection has been amenable to recent applications of vanilla deep RL, but real deployments remain out of reach. In this paper, we explore how learning index selection can be enhanced with task-specific inductive biases, specifically by encoding these inductive biases in better action structures. Index selection-specific action representations arise when the problem is reformulated in terms of permutation learning and we rely on recent work for learning RL policies on permutations. Through this approach, we build an indexing agent that is able to achieve improved indexing and validate its behavior with task-specific statistics. Early experiments reveal that our agent can find configurations that are up to 40% smaller for the same levels of latency as compared with other approaches and indicate more intuitive indexing behavior.
💡 Research Summary
The paper tackles the challenging problem of automatic index‑set selection for database workloads using reinforcement learning (RL). Traditional RL approaches, such as Deep Q‑Networks (DQN), treat the action space as a flat set of discrete choices, which quickly becomes intractable because the number of possible index configurations grows combinatorially with the number of query attributes. Moreover, DQN‑based methods ignore the inherent dependencies between index columns, leading to inefficient exploration and unstable learning.
To address these issues, the authors reformulate index selection as a permutation learning problem. An index can be seen as a prefix of a permutation of the query’s attributes, so the action is naturally a permutation rather than an arbitrary discrete label. They adopt the Sinkhorn Policy Gradient (SPG) algorithm, a recent method for learning policies over permutations. SPG generates a doubly‑stochastic matrix via the Sinkhorn operator, samples a near‑permutation, and provides a differentiable pathway for policy gradient updates. This yields a compact, structured action representation that captures column ordering and inter‑column dependencies in a single continuous policy.
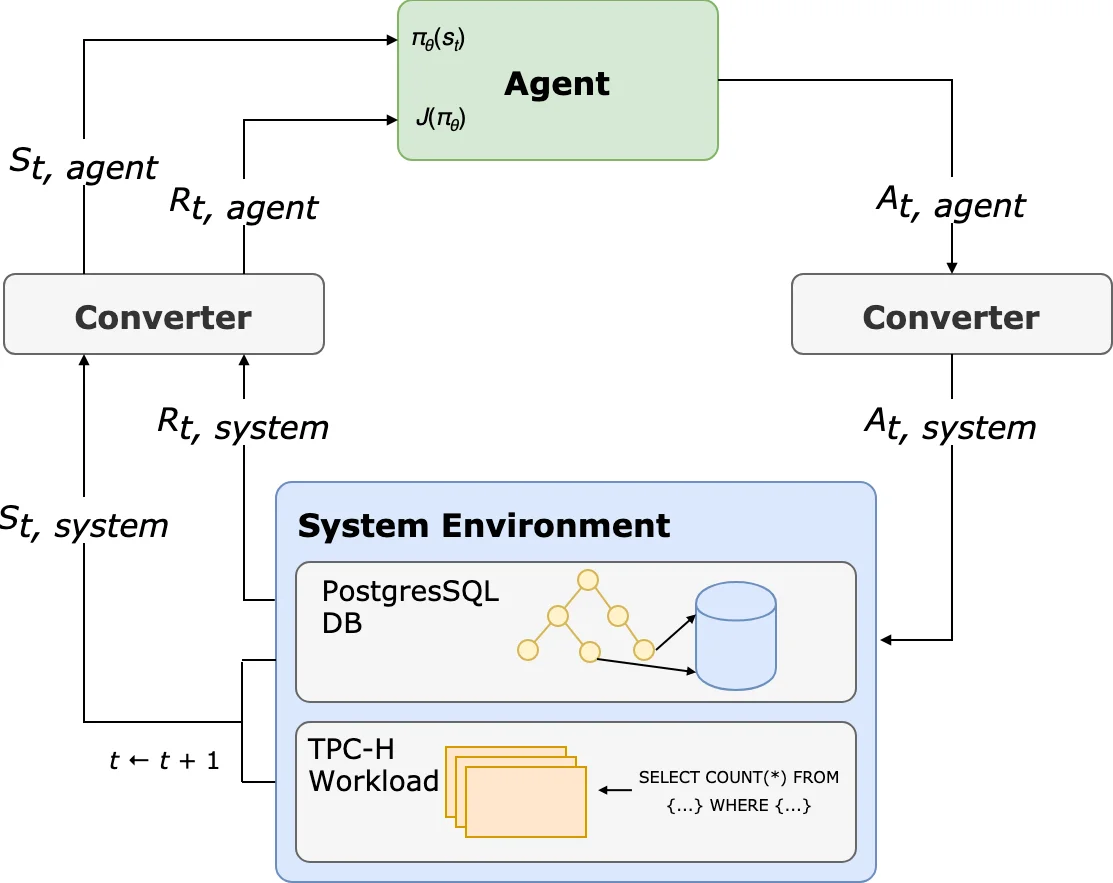
The system architecture consists of: (1) a state encoder that tokenizes the current query and the existing index context, embedding them into a fixed‑size vector; (2) the SPG‑based policy network that outputs a continuous matrix representing a distribution over attribute orderings; (3) a converter that maps the sampled permutation into a concrete index creation command for the DBMS; and (4) a reward function that balances query latency against the incremental size of the newly created index (Δsize). By using Δsize rather than absolute size, the reward provides finer‑grained feedback about space cost at each step.
The authors compare two action encoding schemes: a combinatorial scheme that enumerates all possible prefixes of all permutations (which scales poorly) and a compact “branching” scheme where each index key has its own output stream. The latter is used in prior work with Branching DQN (BDQN), but BDQN treats each stream independently, failing to capture the joint combinatorial nature of index columns. Experiments on synthetic TPCH‑derived workloads show that the SPG‑based agent consistently produces index sets that are 30‑40 % smaller than those generated by the BDQN baseline while achieving comparable query latency. The resulting indexes exhibit intuitive structures, adhering to the prefix‑intersection property of B‑tree indexes, indicating that the policy has learned useful database semantics.
Beyond performance, the SPG approach demonstrates improved training stability: reward variance is lower, convergence is faster, and the policy generalizes better across different query shapes. The paper acknowledges remaining limitations, such as the lack of evaluation on real‑world production databases, the simplicity of the weighted‑sum reward (which does not model update cost or multi‑tenant interactions), and the need for online adaptation. Future work is suggested to integrate more sophisticated cost models, test in live environments, and explore hierarchical permutation policies for even larger attribute sets.
In summary, the work shows that injecting task‑specific inductive bias into the action space—by modeling index selection as a permutation problem and using Sinkhorn‑based policy gradients—significantly enhances RL‑driven database tuning. It provides a concrete example of how structured action representations can overcome the curse of dimensionality in combinatorial system optimization tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment