Comparing reliability of grid-based Quality-Diversity algorithms using artificial landscapes
Quality-Diversity (QD) algorithms are a recent type of optimisation methods that search for a collection of both diverse and high performing solutions. They can be used to effectively explore a target problem according to features defined by the user. However, the field of QD still does not possess extensive methodologies and reference benchmarks to compare these algorithms. We propose a simple benchmark to compare the reliability of QD algorithms by optimising the Rastrigin function, an artificial landscape function often used to test global optimisation methods.
💡 Research Summary
This paper addresses a gap in the field of Quality-Diversity (QD) optimization by proposing a standardized benchmark to compare the reliability of grid-based QD algorithms. QD algorithms, such as MAP-Elites, aim to find a collection of high-performing solutions that are diverse across user-defined feature dimensions, rather than a single optimum. However, the field has lacked rigorous methodologies for objectively comparing these algorithms’ core exploration capabilities.
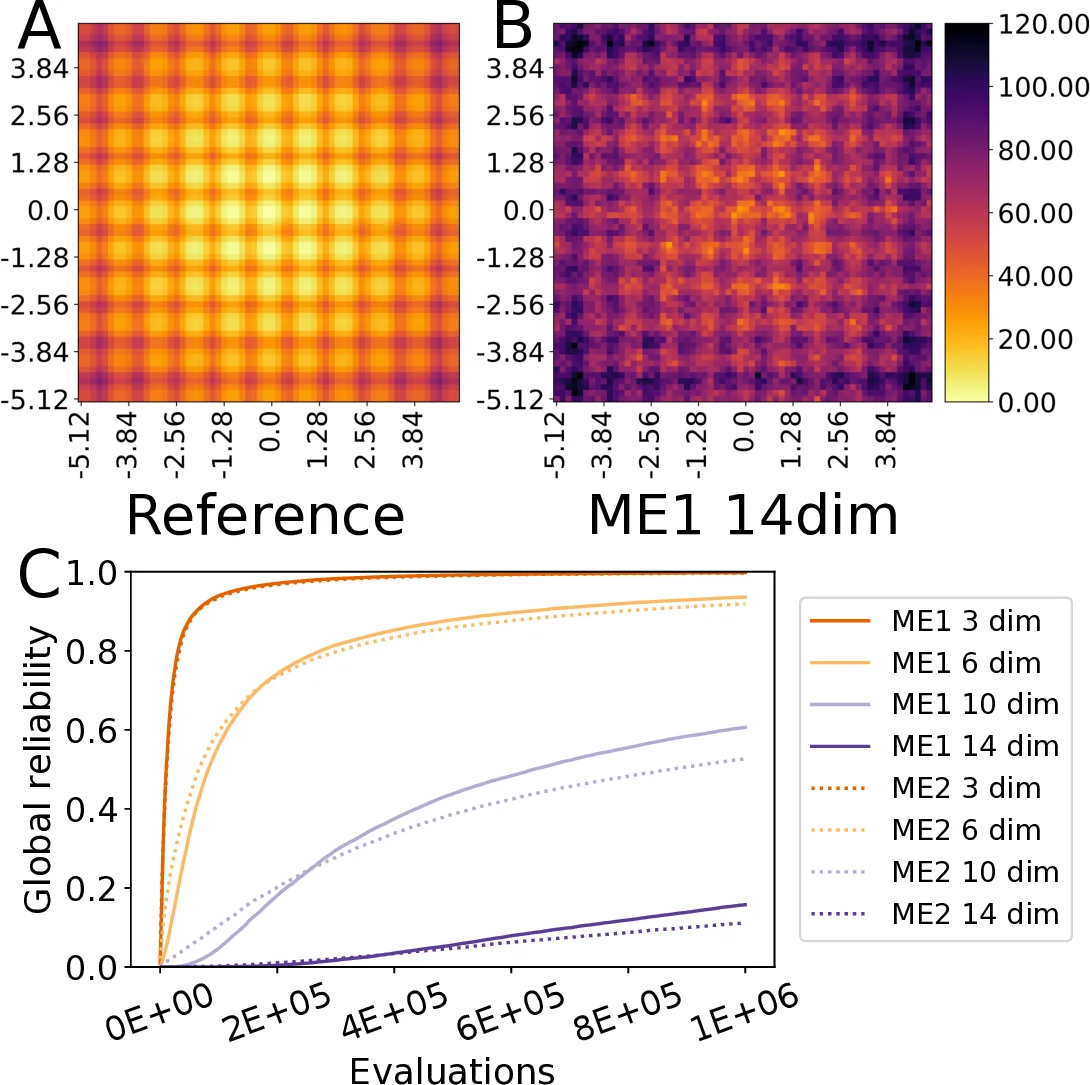
The authors introduce a benchmark centered on the well-known Rastrigin function, a highly multimodal artificial landscape commonly used to test global optimizers. The core idea is to treat the QD problem as “illuminating” this landscape: the algorithm must find high-quality solutions covering a grid defined by two features (the first two dimensions of the Rastrigin input). The key performance metric is “reliability,” which quantifies how close the solution found in each grid cell (bin) is to the theoretical best possible (oracle) value for that cell. Reliability is measured both locally per bin and globally as an average across the entire grid. A reference oracle grid is established by thoroughly illuminating the 2-dimensional Rastrigin function.
Using this framework, the study compares two variants of the MAP-Elites algorithm that differ only in their mutation operator: ME1 uses polynomial bounded mutation (as in the original algorithm), while ME2 uses Gaussian mutation. Both algorithms were tasked with illuminating Rastrigin functions of increasing dimensionality (N=3, 6, 10, 14) and their global reliability over one million evaluations was compared against the 2D reference.
The results clearly demonstrate that problem dimensionality significantly impacts reliability, with performance declining as dimensions increase for both algorithms. This highlights the challenge of scaling QD search to high-dimensional spaces. A notable finding is that ME1 (polynomial bounded mutation) consistently outperformed ME2 (Gaussian mutation), especially in higher dimensions (10D and 14D). This suggests that the choice of variation operator is critical for effective QD search. The bounded mutation likely provided more controlled exploration within the defined domain, leading to more efficient and systematic coverage of the grid. In contrast, the unbounded nature of Gaussian mutation may have caused inefficient exploration dispersion or solutions falling outside the relevant bounds.
In conclusion, the paper provides a simple, reproducible, and insightful methodology for benchmarking fundamental QD algorithm performance. It shifts the comparison to a controlled, well-understood artificial landscape, allowing researchers to isolate and evaluate exploration capabilities before applying algorithms to complex real-world problems. The demonstrated sensitivity to mutation operators underscores the importance of carefully designing variation mechanisms for QD search. The authors suggest future extensions to other benchmark functions and grid configurations, positioning this work as a potential foundation for more standardized testing in QD research.
Comments & Academic Discussion
Loading comments...
Leave a Comment