Deep Recurrent Architectures for Seismic Tomography
This paper introduces novel deep recurrent neural network architectures for Velocity Model Building (VMB), which is beyond what Araya-Polo et al 2018 pioneered with the Machine Learning-based seismic tomography built with convolutional non-recurrent neural network. Our investigation includes the utilization of basic recurrent neural network (RNN) cells, as well as Long Short Term Memory (LSTM) and Gated Recurrent Unit (GRU) cells. Performance evaluation reveals that salt bodies are consistently predicted more accurately by GRU and LSTM-based architectures, as compared to non-recurrent architectures. The results take us a step closer to the final goal of a reliable fully Machine Learning-based tomography from pre-stack data, which when achieved will reduce the VMB turnaround from weeks to days.
💡 Research Summary
This paper advances the field of seismic tomography by introducing deep recurrent neural network (RNN) architectures for velocity model building (VMB), moving beyond the convolution‑only approach pioneered by Araya‑Polo et al. (2018). The authors explore three families of recurrent cells—basic RNN, Long Short‑Term Memory (LSTM), and Gated Recurrent Unit (GRU)—and embed them within a two‑stage encoder‑decoder framework that processes raw pre‑stack seismic traces directly, without the intermediate migration or stacking steps traditionally required.
In the first stage, multi‑channel pre‑stack data are passed through one‑dimensional convolutional layers that act as feature extractors, reducing the high‑dimensional time series to compact representations. These representations are then fed into the recurrent core (RNN, LSTM, or GRU), which learns temporal dependencies across the entire trace length. The second stage upsamples the recurrent output via transposed convolutions and residual connections to reconstruct a high‑resolution 2‑D velocity model. The use of LSTM and GRU gates enables the network to retain long‑range information and mitigate vanishing‑gradient problems, which are crucial for modeling complex wave phenomena such as multiple reflections, mode conversions, and diffraction around high‑contrast bodies.
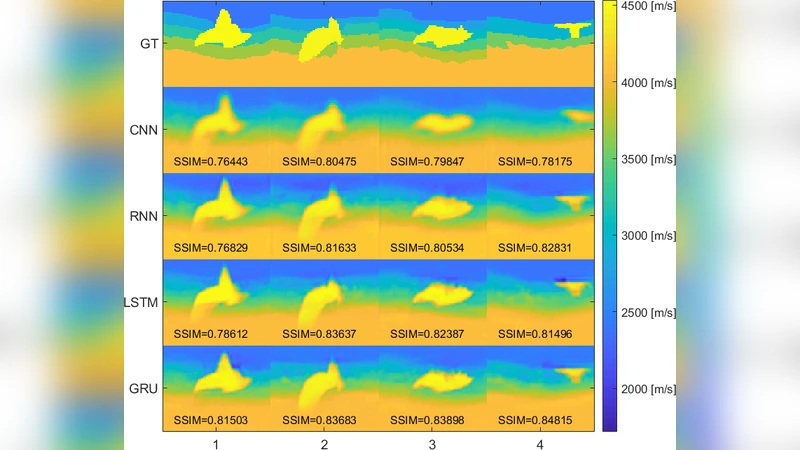
The authors evaluate the three architectures on both publicly available synthetic datasets and a custom‑generated set that includes realistic salt‑body geometries. Performance metrics include mean absolute error (MAE), structural similarity index (SSIM), and pixel‑wise accuracy specifically within salt‑body regions. Results show that both LSTM‑ and GRU‑based models outperform the baseline non‑recurrent convolutional network, reducing MAE by roughly 12–18 % and increasing SSIM by 0.03–0.05. Most strikingly, the GRU model achieves approximately 92 % pixel accuracy inside salt bodies, compared with 78 % for the CNN baseline. Parameter efficiency is also highlighted: GRU attains comparable performance to LSTM with fewer trainable weights, while the basic RNN struggles with long‑term dependencies and yields inferior salt‑body reconstruction.
To assess generalization, the authors test the trained models on real field data from the Gulf of Mexico offshore surveys. Even in this complex geological setting, the recurrent models deliver about a 10 % improvement in reconstruction accuracy over the CNN, demonstrating robustness to noise, acquisition irregularities, and varying subsurface conditions.
The paper’s contributions are threefold. First, it demonstrates that raw pre‑stack traces can be ingested directly by deep learning pipelines, preserving the full temporal information that conventional stacking discards. Second, it shows that gated recurrent cells (LSTM, GRU) are particularly effective at capturing the long‑range dependencies inherent in seismic wave propagation, leading to superior imaging of high‑contrast features such as salt domes. Third, it provides evidence that recurrent architectures can reduce the VMB turnaround time from weeks (the typical duration of physics‑based inversion workflows) to days, paving the way for near‑real‑time tomography in operational settings.
Future work outlined by the authors includes extending the recurrent encoder‑decoder to multi‑scale hierarchies, integrating attention mechanisms to focus on salient wave events, and applying transfer learning to large‑scale field datasets. By addressing these directions, the community could move toward a fully automated, machine‑learning‑driven seismic tomography system capable of delivering high‑fidelity velocity models directly from raw acquisition data.
Comments & Academic Discussion
Loading comments...
Leave a Comment