Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to ATARI games
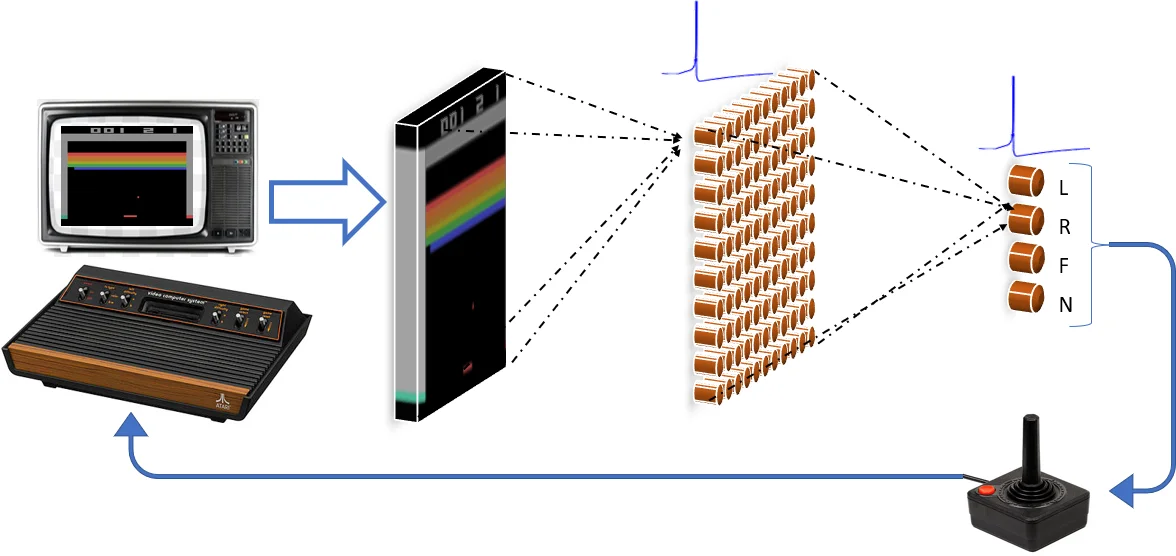
Deep Reinforcement Learning (RL) demonstrates excellent performance on tasks that can be solved by trained policy. It plays a dominant role among cutting-edge machine learning approaches using multi-layer Neural networks (NNs). At the same time, Deep RL suffers from high sensitivity to noisy, incomplete, and misleading input data. Following biological intuition, we involve Spiking Neural Networks (SNNs) to address some deficiencies of deep RL solutions. Previous studies in image classification domain demonstrated that standard NNs (with ReLU nonlinearity) trained using supervised learning can be converted to SNNs with negligible deterioration in performance. In this paper, we extend those conversion results to the domain of Q-Learning NNs trained using RL. We provide a proof of principle of the conversion of standard NN to SNN. In addition, we show that the SNN has improved robustness to occlusion in the input image. Finally, we introduce results with converting full-scale Deep Q-network to SNN, paving the way for future research to robust Deep RL applications.
💡 Research Summary
This paper presents a novel approach to enhancing the robustness of Deep Reinforcement Learning (RL) policies by converting trained artificial neural networks (ANNs) into Spiking Neural Networks (SNNs). While deep RL, particularly using Deep Q-Networks (DQN), achieves superhuman performance on complex tasks like ATARI games, it is notoriously vulnerable to noisy, incomplete, or adversarially perturbed input data. Inspired by the noise-resilience of biological neural systems, the authors investigate whether SNNs—often considered the third generation of neural networks due to their event-driven, bio-plausible operation—can mitigate these weaknesses.
The core methodology involves a conversion technique rather than direct training of SNNs. The researchers first train a standard ANN with Rectified Linear Unit (ReLU) activations using the DQN algorithm on the ATARI Breakout game. This network, which estimates the optimal action-value (Q-value) function, is then architecturally mapped to an SNN by replacing the ReLU neurons with various spiking neuron models, such as Integrate-and-Fire (IF), Leaky Integrate-and-Fire (LIF), and a modified Subtract-IF model. A critical step in the conversion is weight normalization and simulating the SNN for a sufficiently long period (500 time steps) to allow the firing rates of the output layer neurons to stabilize. These firing rates are interpreted as proportional to the original network’s Q-value estimates for each possible action (move left, move right, no movement, fire).
The experiments demonstrate a successful “proof of principle.” The converted SNN performs at a level comparable to the original ReLU ANN on the Breakout task, achieving similar game scores. This confirms that the functions learned by the ANN for RL can be effectively represented by an SNN through firing rate coding. The most significant finding, however, is the enhanced robustness of the converted SNN. When subjected to input occlusion tests—where random portions of the game screen are masked—the SNN version maintains significantly better performance than its ReLU counterpart. The authors attribute this robustness to the inherent properties of spiking networks: the all-or-nothing nature of spikes acts as a bottleneck that filters out sub-threshold noise, and the collective activity of neuronal populations can mitigate the impact of localized input distortions.
Finally, the study scales up the approach, successfully converting a full-scale Deep Q-Network (with convolutional and fully connected layers as per the original DQN architecture) into an SNN. This larger converted SNN also retains its performance, paving the way for applying these methods to state-of-the-art RL models. The work concludes that converting pre-trained RL policies to SNNs is a viable strategy not only for potential energy-efficient deployment on neuromorphic hardware (like Intel’s Loihi or IBM’s TrueNorth) but also for building RL agents that are inherently more robust to input perturbations and corruption, addressing a critical vulnerability in current deep learning systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment