BAE-NET: Branched Autoencoder for Shape Co-Segmentation
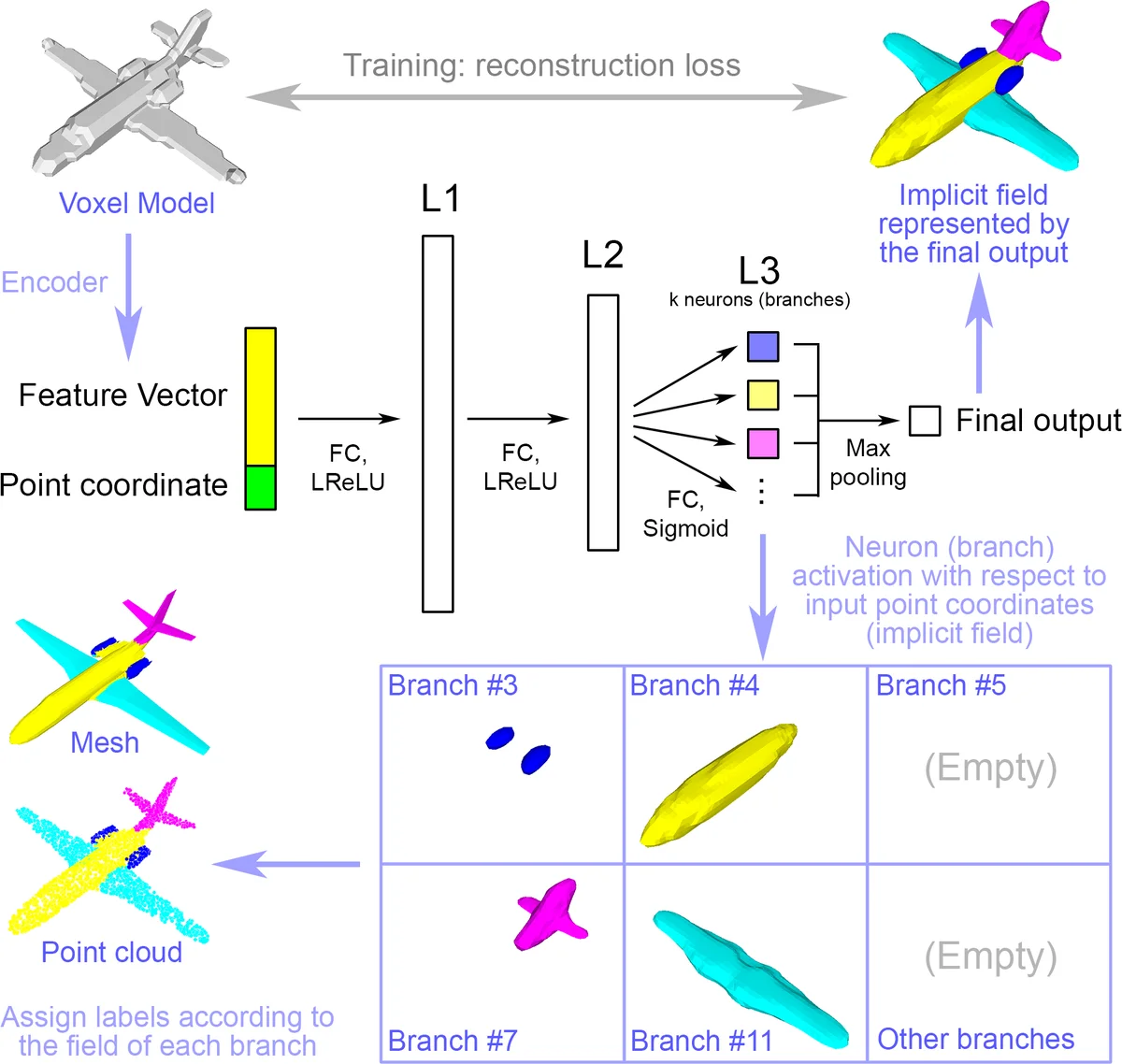
We treat shape co-segmentation as a representation learning problem and introduce BAE-NET, a branched autoencoder network, for the task. The unsupervised BAE-NET is trained with a collection of un-segmented shapes, using a shape reconstruction loss, without any ground-truth labels. Specifically, the network takes an input shape and encodes it using a convolutional neural network, whereas the decoder concatenates the resulting feature code with a point coordinate and outputs a value indicating whether the point is inside/outside the shape. Importantly, the decoder is branched: each branch learns a compact representation for one commonly recurring part of the shape collection, e.g., airplane wings. By complementing the shape reconstruction loss with a label loss, BAE-NET is easily tuned for one-shot learning. We show unsupervised, weakly supervised, and one-shot learning results by BAE-NET, demonstrating that using only a couple of exemplars, our network can generally outperform state-of-the-art supervised methods trained on hundreds of segmented shapes. Code is available at https://github.com/czq142857/BAE-NET.
💡 Research Summary
The paper reframes shape co‑segmentation as a representation learning problem and introduces BAE‑NET, a branched auto‑encoder designed to discover and segment recurring parts across a collection of shapes without requiring dense supervision. The network consists of a conventional convolutional encoder that compresses each input shape (voxel grid, 2‑D image, or point cloud) into a compact feature vector, and a decoder that concatenates this global code with individual point coordinates. The decoder is organized into multiple branches, each ending in a single neuron that predicts an inside/outside value for a specific part. The final shape reconstruction is obtained by max‑pooling the outputs of all branches, allowing parts to overlap naturally.
Training proceeds in three regimes. In the fully unsupervised setting, the model samples points in the 3‑D space around each shape and minimizes a mean‑squared error between the network’s scalar output and the ground‑truth occupancy (inside/outside) label, thereby learning both a global shape reconstruction and a decomposition into part‑specific implicit fields. When a few exemplar shapes with part annotations are available, a supervised loss is added that penalizes the per‑branch predictions against the known part labels. For one‑shot learning, the overall loss is a weighted sum of the unsupervised reconstruction loss over the entire dataset and the supervised part loss over the few labeled examples; in practice the authors alternate one supervised iteration after every four unsupervised iterations and apply a small L1 regularizer on the final‑layer parameters to discourage unnecessary overlap between branches.
The architecture is deliberately shallow: the decoder typically has three fully‑connected layers (e.g., {3072‑384‑12} for unsupervised training, where the last dimension equals the number of parts). This limited capacity forces each branch to learn a compact, linear‑ish representation of a recurring part, which the authors demonstrate with a 2‑D toy example where the network “sorts” images in a joint (feature + pixel) space. The max‑pooling operation at the output enables the model to handle complex, non‑convex parts and overlapping structures that primitive‑based methods (e.g., cuboid fitting) cannot represent.
Extensive experiments on ShapeNet, ShapeNet Part, and Tags2Parts show that BAE‑NET produces coherent co‑segmentations in the unsupervised case, comparable to or better than prior graph‑cut or clustering approaches. In weakly supervised scenarios (category‑level labels) the method refines part boundaries further. Most strikingly, in one‑shot experiments where only 1–3 shapes are annotated, BAE‑NET outperforms fully supervised baselines such as PointNet++ and PointCNN trained on 10 %–30 % of the labeled data (i.e., hundreds of examples). This demonstrates that the network can leverage the structural prior encoded in its branched decoder to generalize from very few examples.
Key contributions include: (1) a branched decoder that directly learns part‑specific implicit fields; (2) a reconstruction‑centric loss that enables unsupervised discovery of meaningful parts; (3) a simple yet effective scheme for integrating a handful of labeled exemplars to achieve one‑shot segmentation. The approach eliminates the need for handcrafted features, large‑scale graph optimization, or extensive annotation, while still delivering high‑quality, consistent segmentations across diverse shape categories. Consequently, BAE‑NET offers a practical, label‑efficient solution for 3‑D shape analysis, with potential extensions to other modalities such as 2‑D images or multimodal shape representations.
Comments & Academic Discussion
Loading comments...
Leave a Comment