On the Way to Futures High Energy Particle Physics Transport Code
High Energy Physics (HEP) needs a huge amount of computing resources. In addition data acquisition, transfer, and analysis require a well developed infrastructure too. In order to prove new physics disciplines it is required to higher the luminosity of the accelerator facilities, which produce more-and-more data in the experimental detectors. Both testing new theories and detector R&D are based on complex simulations. Today have already reach that level, the Monte Carlo detector simulation takes much more time than real data collection. This is why speed up of the calculations and simulations became important in the HEP community. The Geant Vector Prototype (GeantV) project aims to optimize the most-used particle transport code applying parallel computing and to exploit the capabilities of the modern CPU and GPU architectures as well. With the maximized concurrency at multiple levels the GeantV is intended to be the successor of the Geant4 particle transport code that has been used since two decades successfully. Here we present our latest result on the GeantV tests performances, comparing CPU/GPU based vectorized GeantV geometrical code to the Geant4 version.
💡 Research Summary
The paper presents the motivation, design, implementation, and early performance results of the GeantV project, a next‑generation particle transport framework intended to succeed the widely used Geant4 library in high‑energy physics (HEP) simulations. As modern particle accelerators increase luminosity, the amount of data that must be simulated grows dramatically, and the Monte‑Carlo detector simulation has become a larger bottleneck than the actual data acquisition. The authors argue that the stagnation of CPU clock speeds around 3–4 GHz and the proliferation of many‑core CPUs and GPUs demand a fundamentally different software architecture that can exploit fine‑grained parallelism and vector instructions.
GeantV is built around three hierarchical layers of parallelism. The Scheduler replaces the serial particle loop of Geant4 with a “basket” system that groups particles residing in the same type of volume. These baskets are processed in bulk using SIMD (single‑instruction‑multiple‑data) instructions, reducing memory traffic and improving cache utilization. The Physics component, still under development, currently relies on pre‑computed lookup tables for interaction probabilities and final states. By tabulating the results of complex physics calculations, the runtime cost of evaluating cross‑sections and selecting processes is dramatically reduced, at the expense of a potential loss of precision that can be mitigated by increasing table resolution. The Geometry layer is embodied in the VecGeom (Vectorized Geometry) library, which implements the core geometric primitives (boxes, tubes, etc.) and their associated operations (coordinate transformations, distance calculations, Boolean combinations) in a way that can be compiled for both CPUs and GPUs. On CPUs, VecGeom uses the Vc SIMD library to guarantee vectorization across different instruction sets (SSE4.2, AVX, AVX‑512). On GPUs, the same templated code is compiled with CUDA, and an OpenCL/SYCL backend is under construction to broaden hardware support.
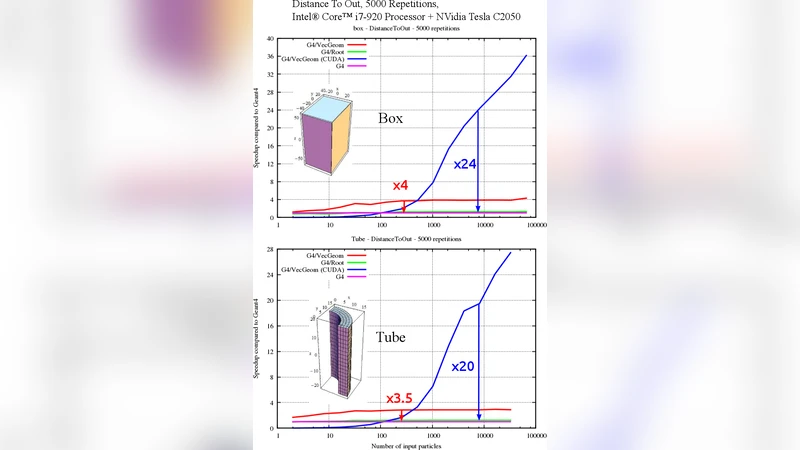
Performance measurements focus on the DistanceToOut method for two simple solids: a box and a tube. The test harness generates random particle positions and velocities, then measures the time required to compute the distance to the solid’s boundary for varying numbers of particles (from 10³ to 10⁶). The hardware platforms are an Intel Core i7‑920 CPU (SSE4.2) and an NVIDIA Tesla C2050 GPU. Each configuration is repeated 5 000 times to reduce statistical fluctuations. Results show that even with modest particle counts the CPU version achieves a speed‑up of roughly 2× compared to the equivalent Geant4 implementation, and the advantage grows to about 2.5× for larger batches. The GPU version exhibits a more dramatic scaling: with 10⁴ particles it already outperforms the CPU by a factor of 5–6, and for 10⁵–10⁶ particles the speed‑up reaches 8–12× and exceeds 15× at the highest counts. The authors note that for very small particle numbers the overhead of data transfer and kernel launch can make the CPU faster, but the trend clearly favors GPUs for the massive parallel workloads typical of modern HEP simulations.
The discussion emphasizes that GeantV’s multi‑level parallelism—scheduler‑level task aggregation, SIMD‑level data parallelism, and GPU‑level massive threading—delivers a combined performance gain that could reduce the total simulation wall‑time by an order of magnitude once the full physics and complex geometry capabilities are integrated. The current study is limited to primitive solids; extending VecGeom to handle complex composite volumes, implementing a high‑precision physics table system, and adding automatic tuning for different hardware configurations are identified as key future work. Moreover, the authors plan to integrate GeantV into larger HEP software stacks and to collaborate with the CERN PH‑SFT group for broader validation.
In conclusion, the paper demonstrates that a vectorized geometry engine, when coupled with a basket‑based scheduler, can already achieve substantial speed‑ups over Geant4 for basic geometric queries. These early results suggest that GeantV is a promising pathway to meet the computational challenges posed by upcoming high‑luminosity experiments, provided that the remaining physics and geometry modules reach comparable levels of optimization and accuracy.
Comments & Academic Discussion
Loading comments...
Leave a Comment