A Flexible High Demand Storage System for MAGIC-I and MAGIC-II using GFS
MAGIC-I is currently the Imaging Cherenkov Telescope with the worldwide largest reflector currently in operation. The initially achieved low trigger threshold of 60 GeV has been further reduced by means of a novel trigger that allows the telescope to record gamma ray showers down to 25 GeV. The high trigger rate combined with the 2 GHz signal sampling rate results in large data volumes that can reach 1 TByte per night for MAGIC-I and even more with the second MAGIC telescope coming soon into operation. To deal with the large storage requirements of MAGIC-I and MAGIC-II, we have installed the distributed file system GFS and a cluster of computers with concurrent access to the same shared storage units. The system can not only handle a sustained DAQ write rate above 1.2 kHz for MAGIC-I, but also allows other nodes to perform simultaneous concurrent access to the data on the shared storage units. Various simultaneous tasks can be used at any time, in parallel with data taking, including data compression, taping, on-line analysis, calibration and analysis of the data. The system is designed to quickly recover after the failure of one node in the cluster and to be easily extended as more nodes or storage units are required in the future.
💡 Research Summary
The paper presents the design, implementation, and performance evaluation of a distributed storage solution for the MAGIC‑I and upcoming MAGIC‑II Imaging Cherenkov Telescopes. MAGIC‑I, the world’s largest Cherenkov telescope, has reduced its trigger threshold from 60 GeV to 25 GeV using a novel low‑energy trigger, which consequently raises the event rate to above 1 kHz. Combined with a 2 GHz flash‑ADC sampling system, the data volume can reach roughly 1 TB per night for MAGIC‑I and will be even larger once MAGIC‑II becomes operational.
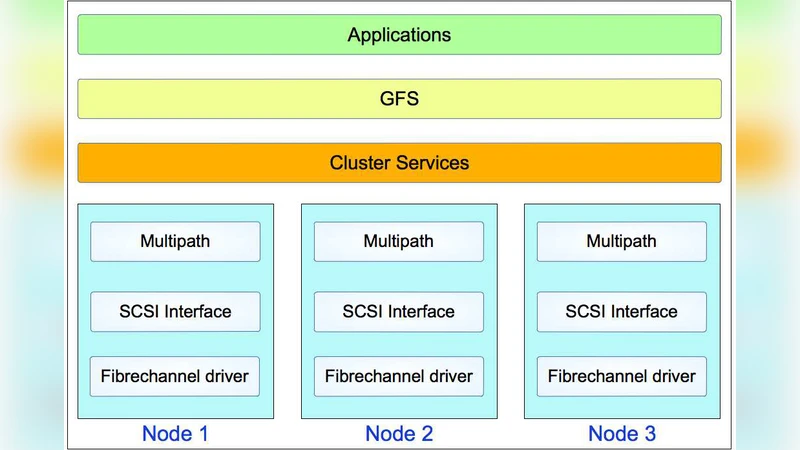
Traditional single‑server or NAS storage architectures cannot sustain the required sustained write throughput while simultaneously supporting online processing tasks such as compression, tape archiving, real‑time analysis, calibration, and scientific analysis. To overcome these limitations, the authors deployed a Red Hat Global File System (GFS) based cluster. GFS enables multiple nodes to read and write concurrently to the same physical storage pool, while a distributed lock manager maintains metadata consistency, eliminating a single point of failure.
The hardware configuration consists of eight data‑acquisition (DAQ) nodes, each capable of sustaining >1.2 kHz write rates, and four auxiliary nodes dedicated to compression, tape backup, online monitoring, calibration, and higher‑level analysis. All nodes share a 12 TB RAID‑6 storage array, providing dual‑parity protection against disk failures. GFS’s write‑through caching and multi‑stream I/O pathways allow loss‑free high‑speed recording, while its file‑locking scheme permits concurrent read access for downstream processes.
The system supports a fully parallel processing pipeline. While the DAQ nodes continuously write raw waveforms, a compression service reads the same files, creates compressed copies, and forwards them to a tape server for LTO archiving. Simultaneously, an online analysis node parses trigger information, generates quality‑monitoring plots, and can feed back adjustments to DAQ parameters in real time. A calibration node applies the latest gain and timing corrections, and a scientific analysis node can start preliminary data reduction without waiting for the night’s end. All these tasks run without I/O contention thanks to GFS’s coordinated locking and caching mechanisms.
Fault tolerance is a core design goal. If any node loses power, network connectivity, or suffers hardware failure, the GFS lock manager instantly redistributes locks to the remaining nodes, and the failed node, upon recovery, automatically resynchronizes its metadata and data blocks. Benchmarks reported in the paper show that the cluster recovers to a fully operational state within an average of three seconds, with zero data loss observed during simulated failures.
Scalability is addressed through the modular nature of the GFS cluster. Adding new storage shelves to the RAID‑6 pool and registering additional compute nodes expands both capacity and aggregate throughput almost linearly. This property ensures that the system can comfortably accommodate the projected >2 TB per night data flow from MAGIC‑II. Moreover, because GFS presents a POSIX‑compatible file system, existing analysis software requires no modification, simplifying integration and reducing operational overhead.
In summary, the authors demonstrate that a GFS‑based distributed file system can reliably handle the demanding data rates of modern Cherenkov telescopes, provide simultaneous access for multiple real‑time processing streams, recover rapidly from node failures, and scale effortlessly as the experiment grows. The architecture serves as a practical reference model for future large‑scale astrophysical observatories such as the Cherenkov Telescope Array (CTA), where comparable or higher data rates and stringent uptime requirements are expected.
Comments & Academic Discussion
Loading comments...
Leave a Comment