📝 Original Info
- Title: Design space exploration of Ferroelectric FET based Processing-in-Memory DNN Accelerator
- ArXiv ID: 1908.07942
- Date: 2019-08-12
- Authors: Insik Yoon, Matthew Jerry, Suman Datta, Arijit Raychowdhury
📝 Abstract
In this letter, we quantify the impact of device limitations on the classification accuracy of an artificial neural network, where the synaptic weights are implemented in a Ferroelectric FET (FeFET) based in-memory processing architecture. We explore a design-space consisting of the resolution of the analog-to-digital converter, number of bits per FeFET cell, and the neural network depth. We show how the system architecture, training models and overparametrization can address some of the device limitations.
💡 Deep Analysis
Deep Dive into Design space exploration of Ferroelectric FET based Processing-in-Memory DNN Accelerator.
In this letter, we quantify the impact of device limitations on the classification accuracy of an artificial neural network, where the synaptic weights are implemented in a Ferroelectric FET (FeFET) based in-memory processing architecture. We explore a design-space consisting of the resolution of the analog-to-digital converter, number of bits per FeFET cell, and the neural network depth. We show how the system architecture, training models and overparametrization can address some of the device limitations.
📄 Full Content
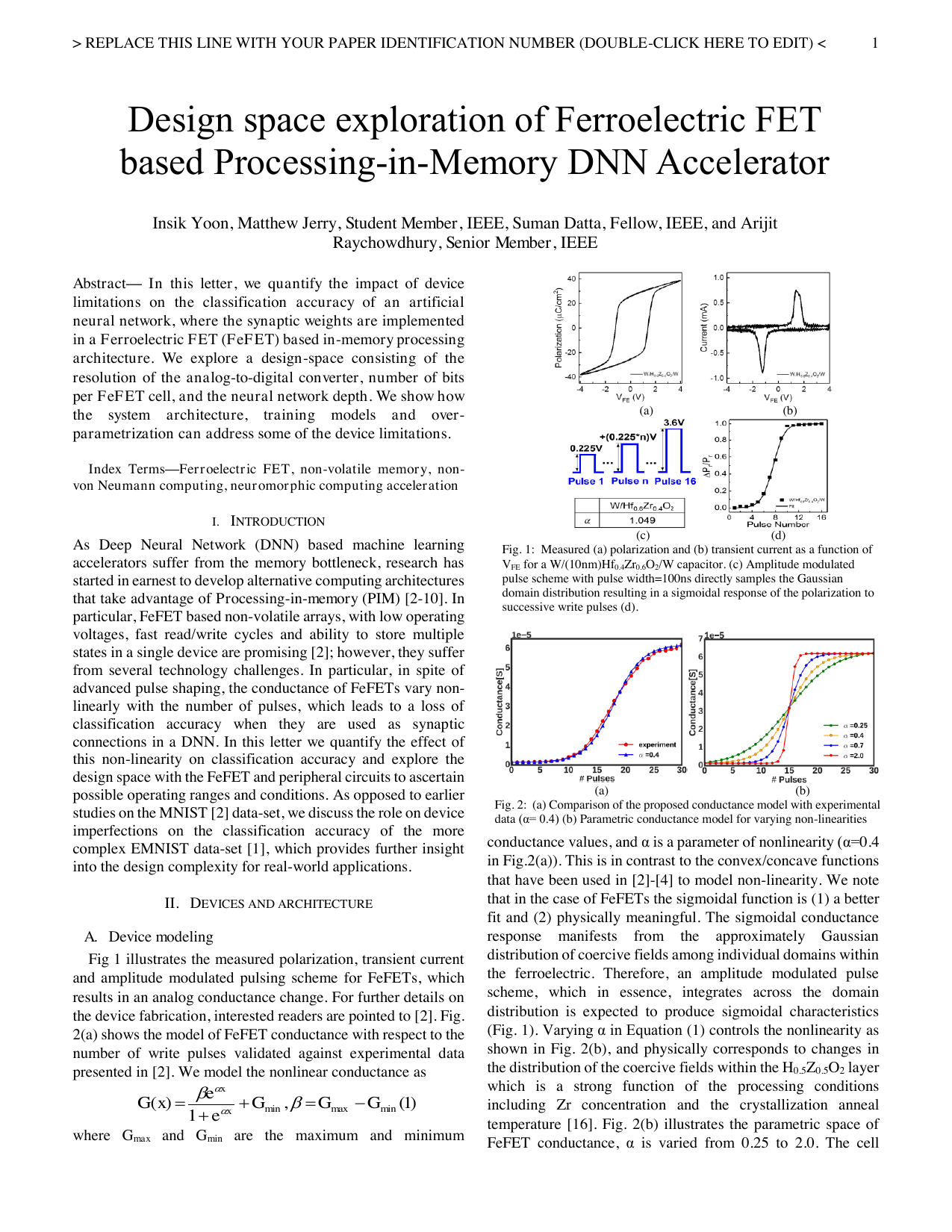
For further details on the device fabrication, interested readers are pointed to [2]. Fig. 2(a) shows the model of FeFET conductance with respect to the number of write pulses validated against experimental data presented in [2]. We model the nonlinear conductance as where Gmax and Gmin are the maximum and minimum conductance values, and α is a parameter of nonlinearity (α=0.4 in Fig. 2(a)). This is in contrast to the convex/concave functions that have been used in [2]- [4] to model non-linearity. We note that in the case of FeFETs the sigmoidal function is (1) a better fit and (2) physically meaningful. The sigmoidal conductance response manifests from the approximately Gaussian distribution of coercive fields among individual domains within the ferroelectric. Therefore, an amplitude modulated pulse scheme, which in essence, integrates across the domain distribution is expected to produce sigmoidal characteristics (Fig. 1). Varying α in Equation (1) controls the nonlinearity as shown in Fig. 2(b), and physically corresponds to changes in the distribution of the coercive fields within the H0.5Z0.5O2 layer which is a strong function of the processing conditions including Zr concentration and the crystallization anneal temperature [16]. 3) shows the schematic diagram for a differential FeFET memory cell capable of storing both positive and negative synaptic weights. We consider the default number of bits per FeFET cell is 5 (32 levels). The access transistors are connected to the gate of FeFETs, GL1 and GL2. During write, write pulses are applied through GL1 and GL2 when WL is asserted to high. During read, BL1 and BL2 are asserted to the read voltage and the currents from each row flowing through the SL are the summed via Kirchoff's circuit laws according to:
The differential cell structure allows us to generalize to both positive and negative numbers (both inputs and weights). As opposed to [4,12,13], this scheme (1) eliminates the need for using a separate array for storing negative weights and (2) enables the use of activation functions like “tanH” [17] and “leaky rectifier unit” [18] which are becoming more common in complex networks and whose outputs can be negative. Fig. 3(b) shows the FeFET memory array for the multiplication of 1 by m vector as well as m by n matrices. SL of each cell in the same row are connected together. The vector inputs are processed by the per-column digital-to-analog converters (DAC). When all the WLs of FeFET array are activated simultaneously, the current sum at SL of each row represents the output of a matrixvector multiplication. Therefore, by using such a PIM architecture, we can compute matrix-vector multiplication in O( 1) [3]. The SL current is transferred to digital value after ADC and sigmoid operation is applied.
The FeFET based PIM architecture for a DNN accelerator is shown in Fig. 4, and is used to explore fully connected Deep Neural Network (DNN) and their performance on the EMNIST Balanced datasets [1] [14] [15]. The network consists of 784 input nodes, a variable number of hidden neurons and 47 output neurons. Fig. 4 shows the conceptual schematic of how the system operates. We envision distinct FeFET memory arrays which store the synaptic weights of the input to the hidden layer and 1, 2 or 3 hidden layers connecting to the output layer. array, 8bit quantized weights are split up into two 4bits and stored in 4 bits/cell FeFET array. Since we split the weights the area of FeFET array is doubled. From the figure, we observe that the classification accuracy with 4bit/cell FeFET array is better than the classification accuracy with 8bit/cell FeFET array. With fixed ADC bit resolution, degradation of precision in computation is worse when 8bit/cell FeFETs are used compared to a case when 4 bit/cell FeFETs are used. We also note that the accuracy increases as the number of ADC bits change from 10 to 12; but the increase is marginal. Therefore, with 784 cells/row in 8bits/cell FeFET array, 10bit ADC shows target performance under area/power/latency constraints. Previous investigations with simpler data-sets (MNIST) [2] have shown acceptable accuracy with the state-of-the-art FeFET devices. We note that more complex data-sets (EMNIST) impose higher restrictions on the device imperfections and further research needs to address them before technology adoption. . This is a key insight which shows that even if the devices themselves suffer from non-linearity, we can improve the classification accuracy by adding more hidden layers and making the model more complex (and hence, over-parametrized). This, of course, comes with an increase in training time and area/power; a discussion which is beyond the scope of this letter.
In this paper, we present how nonlinearity in conductance of FeFET significantly affects classification accuracy in training, necessitating the development of resistive memory technologies with higher linearity. We demonstrate that HATI models per
…(Full text truncated)…
📸 Image Gallery
Reference
This content is AI-processed based on ArXiv data.