Sample size calculations for the experimental comparison of multiple algorithms on multiple problem instances
This work presents a statistically principled method for estimating the required number of instances in the experimental comparison of multiple algorithms on a given problem class of interest. This approach generalises earlier results by allowing researchers to design experiments based on the desired best, worst, mean or median-case statistical power to detect differences between algorithms larger than a certain threshold. Holm’s step-down procedure is used to maintain the overall significance level controlled at desired levels, without resulting in overly conservative experiments. This paper also presents an approach for sampling each algorithm on each instance, based on optimal sample size ratios that minimise the total required number of runs subject to a desired accuracy in the estimation of paired differences. A case study investigating the effect of 21 variants of a custom-tailored Simulated Annealing for a class of scheduling problems is used to illustrate the application of the proposed methods for sample size calculations in the experimental comparison of algorithms.
💡 Research Summary
The paper addresses a fundamental gap in the experimental evaluation of meta‑heuristic and other optimization algorithms: how to determine, a priori, the number of problem instances and the number of algorithm runs per instance required to obtain statistically reliable comparisons when multiple algorithms are involved.
The authors extend earlier work that dealt only with two‑algorithm comparisons to the general case of A algorithms evaluated on N instances. Their methodology proceeds in two linked stages.
1. Determining the number of instances
The key idea is to define a Minimum Relevant Effect Size (MRES) – the smallest standardized performance difference that is considered practically important – and to set a desired statistical power (e.g., 0.80) together with a family‑wise significance level (e.g., α = 0.05). Because multiple pairwise hypotheses are tested, the overall error rate must be controlled. The authors adopt Holm’s step‑down procedure, which is uniformly more powerful than the classic Bonferroni correction while still guaranteeing control of the family‑wise error rate (FWER). Using the non‑central t‑distribution (or its non‑parametric analogue) they derive closed‑form expressions for the required number of instances N that achieve the target power for the worst‑case, best‑case, mean, or median power across all pairwise comparisons.
2. Allocating runs per instance
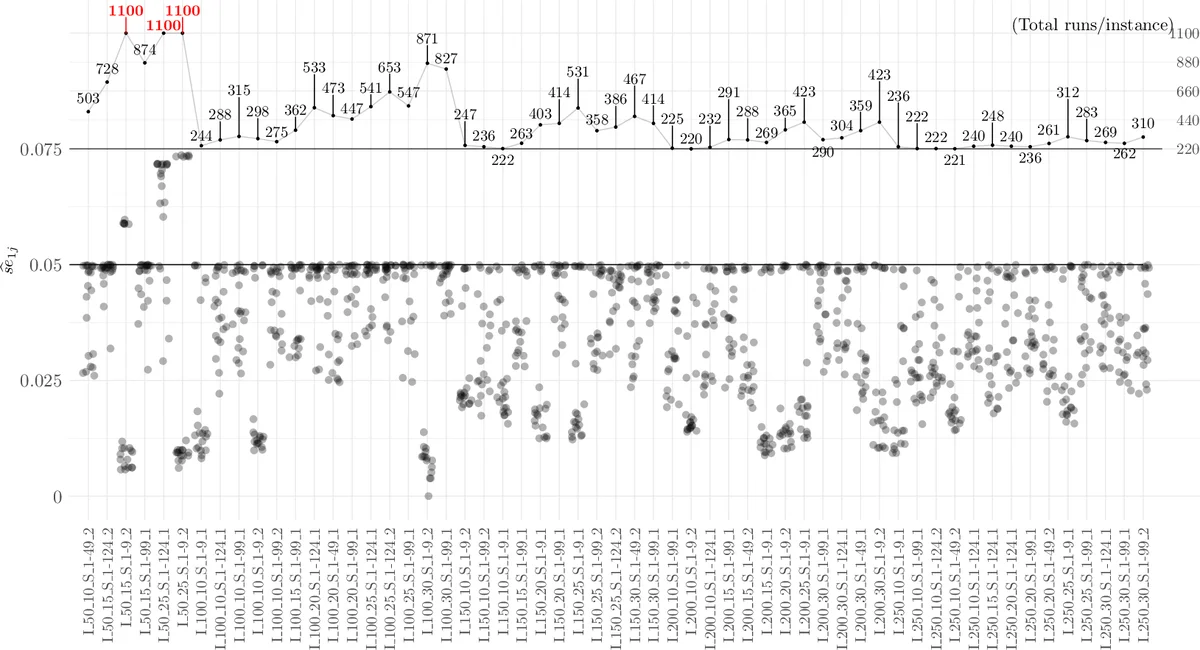
Once N is fixed, the next question is how many repetitions each algorithm should receive on each instance. The authors treat the paired differences between algorithms as the primary estimands and seek the allocation that minimizes the total number of runs while guaranteeing a pre‑specified accuracy (e.g., a confidence‑interval half‑width). For three common estimands – (i) the raw mean difference, (ii) the absolute percent difference, and (iii) the relative percent difference – they derive optimal sample‑size ratios based on the variances of the paired differences. The optimal ratio for the mean difference, for example, is proportional to the inverse of the standard deviations of the two algorithms, leading to an intuitive “more runs for the noisier algorithm” rule. A simple integer‑rounding heuristic converts the continuous ratios into actual run counts.
Statistical testing framework
The paper formalises the comparison problem using the complete block design model:
Y_{k|γ} = μ + τ_k + θ_γ + ε_{kγ},
where τ_k captures the algorithm effect, θ_γ the instance effect, and ε_{kγ} the residual. The omnibus null hypothesis H0: τ_1 = … = τ_A is first tested (using either ANOVA for normally distributed differences or Friedman’s test for non‑parametric data). If rejected, pairwise hypotheses H_{ij}: τ_i – τ_j = 0 are examined. Two families of pairwise tests are discussed: “all‑vs‑all” (A(A‑1)/2 tests) and “all‑vs‑one” (A‑1 tests). The latter, combined with Holm correction, yields higher power and often requires fewer instances for a given power target.
Practical implementation
All procedures are implemented in the R package CAISEr, which automates the calculation of N, the optimal run‑allocation ratios, and the execution of Holm‑adjusted pairwise tests.
Case study
The methodology is illustrated on a study of 21 variants of a custom Simulated Annealing algorithm applied to a class of scheduling problems. The authors set MRES = 0.1 (standardized units), power = 0.80, and α = 0.05. The resulting design calls for 30 problem instances and a run‑allocation pattern roughly 1 : 1.2 : 0.8 among selected algorithms, reflecting their empirical variances. The experimental results confirm that the planned power is achieved and that several algorithm pairs are identified as statistically different, matching the expectations set by the a‑priori calculations.
Conclusions
By linking sample‑size theory with multiple‑comparison correction, the paper provides a rigorous, reproducible blueprint for designing algorithm‑comparison experiments. It moves the community beyond ad‑hoc choices of 30 or 50 runs per algorithm, showing how to balance computational budget, practical relevance of effect sizes, and statistical rigor. The availability of an open‑source implementation further lowers the barrier for adoption, promising more reliable and comparable empirical studies in the meta‑heuristics field.
Comments & Academic Discussion
Loading comments...
Leave a Comment