Expediting TTS Synthesis with Adversarial Vocoding
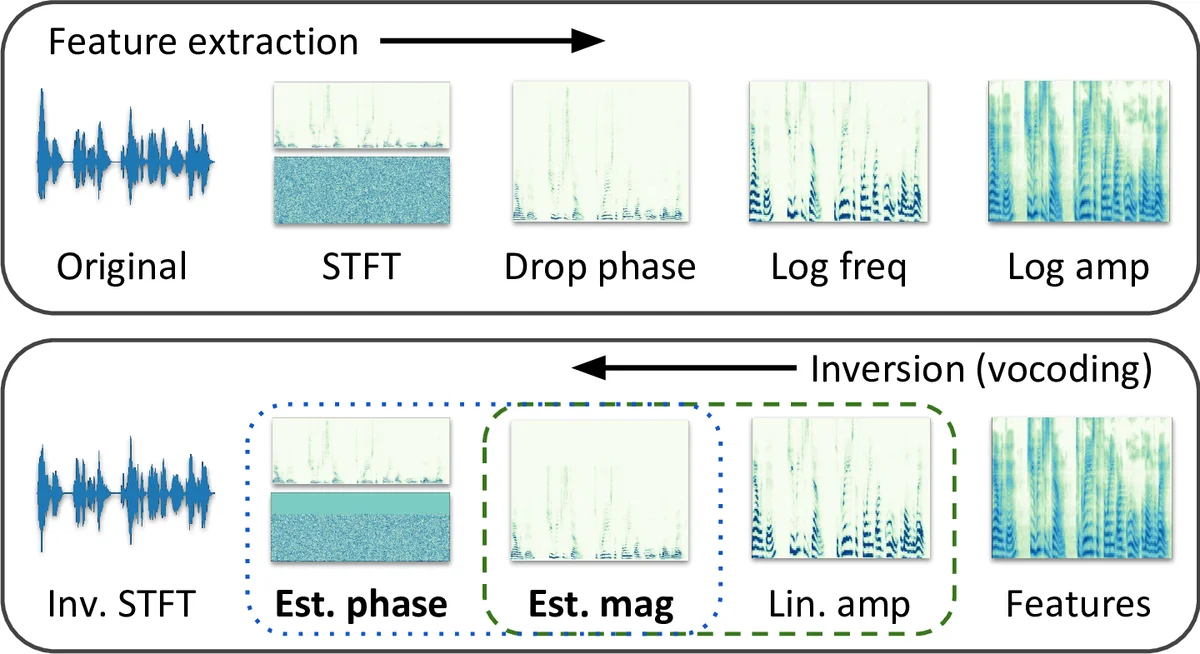
Recent approaches in text-to-speech (TTS) synthesis employ neural network strategies to vocode perceptually-informed spectrogram representations directly into listenable waveforms. Such vocoding procedures create a computational bottleneck in modern TTS pipelines. We propose an alternative approach which utilizes generative adversarial networks (GANs) to learn mappings from perceptually-informed spectrograms to simple magnitude spectrograms which can be heuristically vocoded. Through a user study, we show that our approach significantly outperforms na"ive vocoding strategies while being hundreds of times faster than neural network vocoders used in state-of-the-art TTS systems. We also show that our method can be used to achieve state-of-the-art results in unsupervised synthesis of individual words of speech.
💡 Research Summary
The paper addresses the computational bottleneck in modern text‑to‑speech (TTS) pipelines that arises from the vocoding stage. State‑of‑the‑art TTS systems such as Tacotron 2 and FastSpeech generate perceptually‑informed mel‑spectrograms, which are compact but discard phase information and compress the linear‑frequency magnitude axis. To reconstruct a waveform, both the missing phase and the original linear‑frequency magnitude must be estimated. Existing neural vocoders (WaveNet, WaveGlow) attempt to solve these two sub‑problems jointly, but they require running a deep network for every audio sample, making them orders of magnitude slower than the language‑to‑spectrogram front‑end.
The authors first conduct a user study to quantify the relative importance of magnitude versus phase estimation. By mixing and matching ideal (ground‑truth) magnitudes or phases with heuristic estimates for the other component, they find that either sub‑problem solved perfectly yields high naturalness, while the other can be handled with a simple heuristic. This motivates focusing on the magnitude estimation problem, while using a fast and high‑quality phase estimator: Local Weighted Sums (LWS), which outperforms the classic Griffin‑Lim algorithm and is about six times faster.
To improve magnitude estimation, the paper proposes an adversarial vocoding approach based on conditional GANs (pix2pix). The generator receives a mel‑spectrogram (log‑amplitude, mel‑scaled) and first produces a coarse linear‑frequency magnitude estimate via the pseudoinverse of the mel‑filterbank. This estimate is then refined by a U‑Net‑style encoder‑decoder with skip connections, trained with a combination of an adversarial loss and an L1 reconstruction loss (λ = 10). The discriminator operates on spectrogram patches, encouraging realistic local detail. The final pipeline combines the GAN‑generated magnitude with LWS‑estimated phase and performs an inverse STFT to synthesize audio.
Experiments are performed on the LJ Speech dataset (13 k utterances, 24 h) and on mel‑spectrograms generated by a Tacotron 2‑style model. Three compression levels (20, 40, 80 mel bins) are evaluated. Training uses a single NVIDIA 1080 Ti GPU for 100 k mini‑batches (batch size 8), taking about 12 hours. Evaluation includes two mean opinion score (MOS) studies: MOS‑Real (real speech mel‑spectrograms) and MOS‑TTS (synthetic mel‑spectrograms), as well as a speed‑up factor relative to real‑time (×RT).
Results show that the large adversarial vocoder (AdVoc) achieves a 3.1× real‑time speed (×RT = 3.111) while attaining MOS‑Real = 3.78 ± 0.07 and MOS‑TTS = 2.91 ± 0.08. The smaller model (AdVoc‑small) is even faster (×RT = 3.437) with slightly lower MOS (3.68/3.09). Compared to WaveNet (×RT ≈ 0.003, MOS ≈ 4.0) and WaveGlow (×RT ≈ 1.2, MOS ≈ 4.1), the proposed method offers a far superior speed‑quality trade‑off. Moreover, the approach works well on heavily compressed features (13:1 compression) and sets a new state‑of‑the‑art for unsupervised word‑level speech synthesis.
The key insight is that phase reconstruction can be handled efficiently with LWS, and that a GAN‑based magnitude estimator can replace the expensive neural vocoder, yielding a vocoding stage that is hundreds of times faster than existing end‑to‑end solutions while preserving naturalness. The paper suggests future work on further model compression, multi‑speaker/multi‑language extensions, and integration into real‑time streaming TTS systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment