Convolutional Reservoir Computing for World Models
Recently, reinforcement learning models have achieved great success, completing complex tasks such as mastering Go and other games with higher scores than human players. Many of these models collect considerable data on the tasks and improve accuracy…
Authors: Hanten Chang, Katsuya Futagami
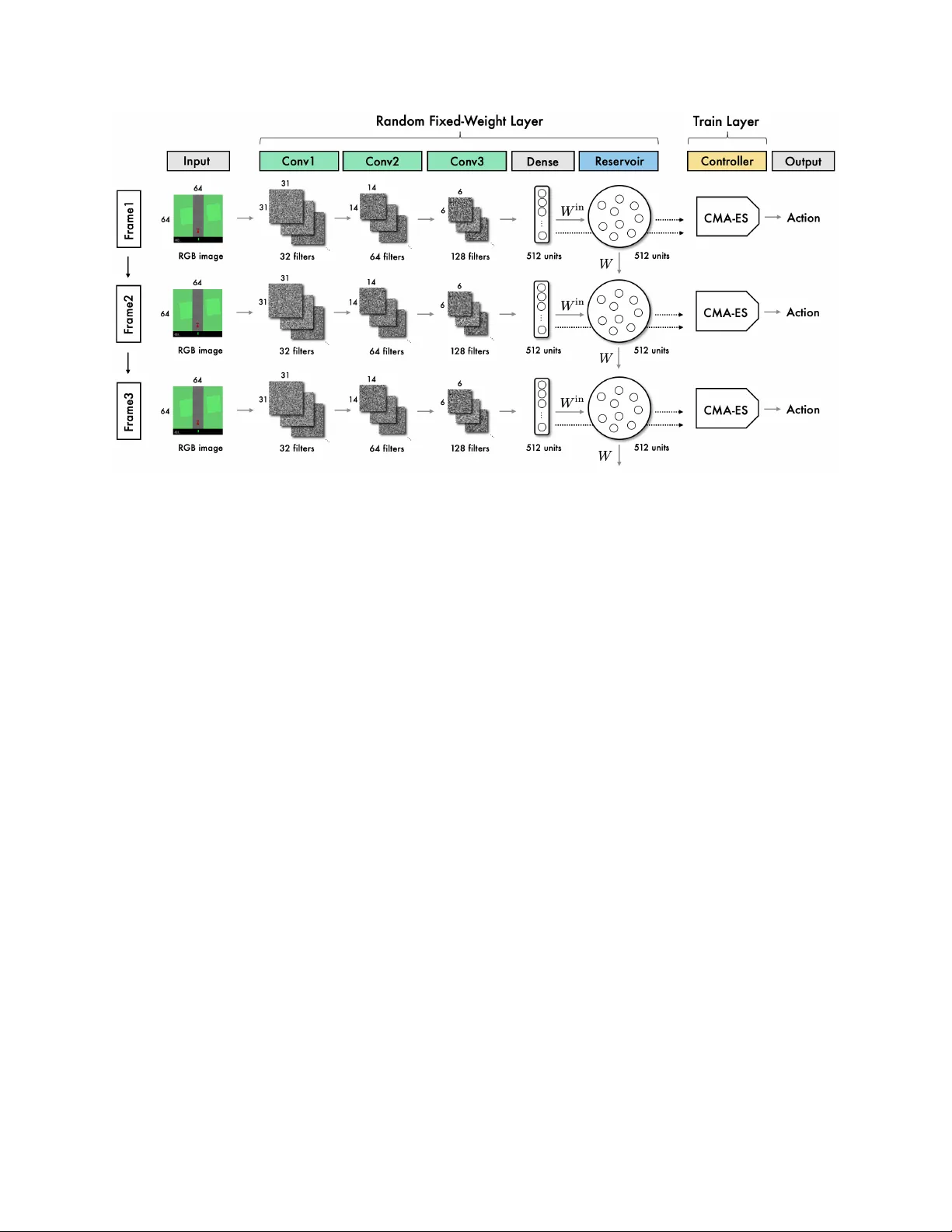
Con volutional Reserv oir Computing f or W orld Models A P R E P R I N T Hanten Chang Graduate school of Systems and Information Engineering, Univ ersity of Tsukuba, Japan s1820554@s.tsukuba.ac.jp Katsuya Futagami Graduate school of Systems and Information Engineering, Univ ersity of Tsukuba, Japan s1820559@s.tsukuba.ac.jp July 19, 2019 A B S T R A C T Recently , reinforcement learning models ha ve achie ved great success, completing comple x tasks such as mastering Go and other games with higher scores than human players. Many of these models collect considerable data on the tasks and improv e accuracy by e xtracting visual and time-series features using con volutional neural networks (CNNs) and recurrent neural networks, respecti vely . Howe ver , these networks ha ve v ery high computational costs because they need to be trained by repeatedly using a lar ge v olume of past playing data. In this study , we propose a no vel practical approach called reinforcement learning with con volutional reserv oir computing (RCRC) model. The RCRC model has sev eral desirable features: 1. it can extract visual and time-series features v ery fast because it uses random fixed-weight CNN and the reserv oir computing model; 2. it does not require the training data to be stored because it extracts features without training and decides action with e volution strate gy . Furthermore, the model achie ves state of the art score in the popular reinforcement learning task. Incredibly , we find the random weight-fixed simple networks lik e only one dense layer network can also reach high score in the RL task. 1 Introduction Recently , reinforcement learning (RL) models have achie ved great success, mastering comple x tasks such as Go [1, 2] and other games [3 – 5] with higher scores than human players. Many of these models use con volutional neural networks (CNNs) to e xtract visual features directly from the environment state pixels [6]. Some models use recurrent neural networks (RNNs) to extract time-series features and achie ved higher scores [5, 7]. Ho wev er , these deep neural netw ork (DNN) based models are v ery computationally e xpensi ve in that they train networks weights by repeatedly using a large volume of past playing data. Certain techniques can alle viate these costs, such as the distributed approach [4, 8] which ef ficiently uses multiple agents, and the prioritized experienced replay [9] which selects samples that facilitate training. Ho wev er , the cost of a series of computations, from data collection to action determination, remains high. W orld model [10, 11] can also reduce computational costs by completely separating the training process between the feature extraction model and the action decision model. W orld model replaces the feature extraction model training process with the supervised learning, by using v ariational auto-encoder (V AE) [12, 13] and mixture density netw ork combined with an RNN (MDN-RNN) [14, 15]. After extracting the en vironment state features, it uses an evolution strategy called the cov ariance matrix adaptation e volution strategy (CMA-ES) [16, 17] to train an action decision model, which achiev ed outstanding scores in popular RL tasks. The separation of these two models results in the stabilization of feature extraction and omission of parameters to be trained based on task-dependent re wards. From the success of world model, it is implied that in the RL feature e xtraction process, it is necessary to extract the features that e xpress the en vironment state rather than features trained to solv e the tasks. In this study , adopting this idea, we propose a new method called "reinforcement learning with con volutional reserv oir computing (RCRC)". The RCRC model is inspired by the reservoir computing. A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 Figure 1: Reservoir Computing ov ervie w for the time-series prediction task. Reservoir computing [18, 19] is a kind of RNNs, but the model weights are set to random. One of the models of the reservoir computing model, the echo state network (ESN) [20 – 22] is used to solve time-series tasks such as future value prediction. For this, the ESN e xtracts features for the input based on the dot product between the input and a random matrix generated without training. Surprisingly , features obtained in this manner are expressi ve enough to understand the input signal, and complex tasks such as chaotic time-series prediction can be solv ed by using them as the input for a linear model. In addition, the ESN has solv ed the tasks in multiple fields such as time-series classification [23, 24] and Q-learning-based RL [25]. Thus, even if the ESN uses random weights, it can e xtract sufficient e xpressi ve features of the input and can solve the task using the linear model. Similarly , in image classification, the model that uses features extracted by the CNN with random fixed-weights as the ESN input achiev es high accuracy classification with a smaller number of parameters [26]. Based on the success of the above random fix ed-weight models, RCRC extracts the visual features of the environment state using random fixed-weight CNN and, using these features as the ESN input, extracts time-series features of the en vironment state transitions. In the feature extraction process, all features are extracted based on matrices with random elements. Therefore, no training process is required, and feature extraction can be performed very fast. After extracting the en vironment state features, we use CMA-ES [16, 17] to train a linear combination of extracted features to perform the actions, as in world model. This model architecture results in the omission of the training process of feature extraction and recuded computational costs; there is also no need to store a lar ge volume of past playing data. Furthermore, we show that RCRC can achie ve state of the art score in popular RL task. Our contribution in this paper is as follo w: • W e developed a nov el and highly efficient approach to extract visual and time-series features of an RL en vironment state using a fixed random-weight model with no training. • By combining random weight networks with an e volution strate gy method, we eliminated the need to store any past playing data. • W e showed that a model with these desirable characteristics can achiev e state of the art score in popular continuous RL task. • W e sho wed that simple random weight-fixed networks, for example one dense layer netw ork, can also extract visual features and achiev e high score in continuous RL task. 2 Related W ork 2.1 Reservoir Computing Reservoir computing is a promising model that can solve complex tasks, such as chaotic time-series prediction, without training for the feature extraction process. In this study , we focus on the reservoir computing model, ESN [20 – 22]. ESN was initially proposed to solv e time-series tasks [20] and is regarded as an RNN model [19], it can be applied to multiple fields. Let the N -length, D u -dimensional input signal be u = { u (1) , u (2) , ..., u ( t ) , ..., u ( N ) } ∈ R N × D u and the signal that adds input signal to one bias term be U = [ u ; 1] = { U (1) , U (2) , ..., U ( T ) , ..., U ( N ) } ∈ R N × ( D u +1) . [;] is a vector 2 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 concatenation. ESN gets features called the reservoir state X = { X (1) , , ..., X ( t ) , ..., X ( N ) } ∈ R N × D x as follows: ˜ X ( t + 1) = f ( W in U ( t ) + W X ( t ))) X ( t + 1) = (1 − α ) X ( t ) + α ˜ X ( t + 1) where the matrices W in ∈ R ( D u +1) × D x and W ∈ R D x × D x are random sampled from a probability distrib ution such as a Gaussian distrib ution, and f is the acti vation function which is applied element-wise. As the acti vation function, linear and tanh functions are generally used; it is also kno wn that changing the activ ation function according to the task improves accurac y [27, 28]. The leakage rate α ∈ [0 , 1] is a hyper parameter that tunes the weight between the current and the previous v alues, and W has two major hyper parameters called sparsity which is ratio of 0 elements in matrix W and the spectral radius that is memory capacity hyper parameter which is calculated by the maximal absolute eigen v alue of W . Finally , ESN estimates the target signal y = { y (1) , y (2) , ..., y ( t ) , ..., y ( N ) } ∈ R N × D y as y ( t ) = W out [ X ( t ); U ( t ); 1] . The weight matrix W out ∈ R D y × ( D x + D u +1) is estimated by a linear model such as ridge re gression. An overvie w of reservoir computing is sho wn in Figure1. The unique feature of the ESN is that the tw o matrices W in and W used to update the reservoir state are randomly generated from a probability distribution and fixed without training. Therefore, the training process in the ESN consists only of a linear model to estimate W out ; therefore, the ESN model has a very lo w computational cost. In addition, the reservoir state reflects comple x dynamics despite being obtained by random matrix transformation, and it is possible to use it to predict comple x time-series by simple linear transformation [18, 20, 29]. Because of the lo w computational cost and high expressi veness of the extracted features, the ESN is also used to solve other tasks such as time-series classification [23, 24], Q-learning-based RL [25] and image classification [26]. 2.2 W orld models Recently , most RL models use DNNs to e xtract features and solved sev eral complex tasks. Howe ver , these models have high computational costs because a lar ge volume of past playing data need to be stored, and netw ork parameters need to be updated using the back propagation method. There are ce rtain techniques [4, 8, 9] and models that can reduce this cost; some models [10, 11, 30] separate the training process of the feature extraction and action decision models to more efficiently train the action decision model. The world model [10, 11] is one such model, and uses V AE [12, 13] and MDN-RNN [14, 15] as feature e xtractors. They are trained using supervised learning with randomly played 10000 episodes data. As a result, in the feature extraction process, the task-dependent parameters are omitted, and there remains only one weight parameter to be trained that decides the action in the model. Therefore, it becomes possible to use the evolution strategy algorithm CMA-ES [16, 17] ef ficiently to train that weight parameter . The process of optimizing weights of action decision model using CMA-ES can be parallelized. Although the feature extraction model is trained in a task-independent manner, world model achie ved outstanding scores and masterd popular RL task CarRacing-v0 [31]. CMA-ES is one of the e volution strate gy methods used to optimize parameters using a multi-candidate search generated from a multi v ariate normal distribution N ( m, σ 2 C ) . The parameters m , σ , and C are updated with a formula called the ev olution path. Evolution paths are updated according to the pre vious evolution paths and e valuation scores. Because CMA-ES updates parameters using only the e v aluation scores calculated by actual playing, it can be used re gardless of whether the actions of the en vironment are continuous or discrete values [16, 17]. Furthermore, training can be faster because the calculations can be parallelized by the number of solution candidates. In world model, the action decision model is simplified to reduce the number of task-dependent parameters, making it possible to use CMA-ES efficiently [10, 11]. W orld model improv es the computational cost of the action decision model and accelerates the training process by separating models and applying CMA-ES. Ho wever , in world model, it is necessary to independently optimize V AE, MDN-RNN, and CMA-ES. Further , because the feature extraction model is dependent on the en vironment, a lar ge amount of past data must be stored to train the feature extraction model each time the en vironment changes. 3 Proposal Model 3.1 Basic Concept W orld model [10, 11] e xtracts visual features and time-series features of en vironment states by using V AE [12, 13] and MDN-RNN [14, 15] without using environment scores. The models achie ve outstanding scores through the linear 3 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 Figure 2: RCRC overvie w to choose the action for CarRacing-v0 : the first and second layers are collecti vely called the con v olutional reservoir computing layer , and both layers’ model weights are sampled from Gaussian distrib ution and then fixed. transformation of these features. This implies that it only requires features that sufficiently e xpress the en vironment state, rather than features trained to solve the task. W e thus focus on extracting features that suf ficiently express en vironment state by networks with random fixed-weights. Using networks whose weights are random and fix ed has some adv antages, such as ha ving very low computational costs and no data storage requirements, while being able to suf ficiently extract features. F or example, a simple CNN with random fixed-weights can extract visual features and achie ve high accurac y [26]. Although the MDN-RNN is fixed in the world model, it can achiev e outstanding scores [32]. In the case of ESN, the model can predict complex time-series using features e xtracted by using random matrices transformations [18, 20, 29]. Therefore, it can be considered that CNN can extract visual features and ESN can e xtract time-series features, ev en if their weights are random and fixed. From this hypothesis, we propose reinforcement learning with the RCRC model, which includes both random fix ed-weight CNN and ESN. 3.2 Proposal model overview The RCRC model is di vided into three model layers. In the first layer , it e xtracts visual features by using a random fixed-weight CNN. In the second layer , it uses a series of visual features e xtracted in the first layer as input to the ESN to extract the time-series features. In the two layers abov e, collecti vely called the con volutional reservoir layer , visual and time-series features are extracted with no training. In the final layer , the linear combination matrix is trained from the outputs of the con v olutional reservoir layer to the actions. An ov erview is sho wn in Figure2. In the previous study , there is a similar world model–based approach [33] that uses fix ed weights in V AE and a memory component based on recurrent long short-term memory (LSTM) [34]. Ho wev er , this approach is ineffecti ve in solving CarRacing-v0 . In the training process, the best av erage score ov er 20 randomly created tracks of each generation were less than 200. Howe ver , as mentioned further on, we achie ve an a verage score abov e 900 ov er 100 randomly created tracks by taking reservoir computing kno wledge in the RCRC model. The characteristics of the RCRC model are as follows: • The computational cost of this model is very lo w because visual and time-series features of game states are extracted using a con volutional reserv oir computing layer whose weights are fixed and random. • In RCRC, only a linear combination in the controller layer needs to be trained because the feature e xtraction model (con volutional reserv oir computing layer) and the action training model (controller layer) are separated. 4 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 • RCRC can take a wide range of actions re gardless of continuous or discrete, because of maximizing the scores that is measured by actually playing. • Past data storage is not required, as neither the con v olutional reservoir computing layer nor the controller layer need to repeatedly train the past data as in backpropagation. • The con volutional reserv oir computing layer can be applied to other tasks without further training, because the layer is fixed with task-independent random weights. 3.3 Con volutional Reservoir Computing layer In the con volutional reservoir computing layer , the visual and time-series features of the en vironment state image are extracted by a random fixed-weight CNN and an ESN which has random fix ed-weight, respectively . A study using CNN with fixed random weights for each single-image as input to ESN has been previously conducted, and has shown its ability to classify MNIST dataset [35] with high accurac y [26]. Based on this study , we de veloped a no vel approach to perform RL tasks. By taking adv antage of the RL characteristic by which the current en vironment state and action determine the next state, RCRC updates the reservoir state with current and previous features. This updating process enables the reservoir state to ha ve time-series features. More precisely , consider the D con v -dimensional visual features extracted by fixed random weight CNN for t -th en vironment state pixels X con v ( t ) ∈ R D conv and the D esn -dimensional reserv oir state X esn ( t ) ∈ R D esn . The reservoir state X esn is time-series features and is updated as follows: ˜ X esn ( t + 1) = f ( W in X con v ( t ) + W X esn ( t ))) X esn ( t + 1) = (1 − α ) X esn ( t ) + α ˜ X esn ( t + 1) . This updating process has no training requirement, and is very fast, because W in and W are random matrices sampled from the probability distribution and fix ed. 3.4 Controller layer The controller layer decides the action by using the output of the conv olutional reserv oir computing layer , X con v and X esn . Let t -th en vironment state input vector which added one bias term be S ( t ) = [ X con v ( t ); X esn ( t ); 1] ∈ R D conv + D esn +1 ) . In the action decision, we suppose that the feature S ( t ) has sufficient e xpressiv e information and it can take action by a linear combination of S ( t ) . Therefore, we obtain action A ( t ) ∈ R N act as follows: ˜ A ( t ) = W out S ( t ) A ( t ) = g ( ˜ A ( t )) where, W out ∈ R ( D conv + D esn +1) × N act is the weight matrix and N act is the number of actions in the task en vironment; g is applied to each action to put each ˜ A ( t ) in the range of possible values in the task en vironment. Because the weights of the con volutional reserv oir computing layer are fixed, only the weight parameter W out requires training. W e optimize W out by using CMA-ES, as in world model. Therefore, it is possible to parallelize the training process and handle both discrete and continuous values as actions [16, 17]. The process of optimizing W out by CMA-ES are shown as follo ws: 1. Generate n solution candidates W out T ,i ( i = 1 , 2 , ..., n ) from a multiv ariate normal distribution N ( m ( T ) , σ ( T ) 2 C ( T )) 2. Create n en vironments and agents work er i that implement RCRC 3. Set W out i to the controller layer of worker i 4. In each ex ecution en vironment, each worker i plays m episodes and receiv es m scores G i,j ( j = 1 , 2 , ..., m ) 5. Update e volution paths with the score of each W out i which is G i = 1 /m P m j =1 G i,j 6. Update m , σ , C using ev olution paths 7. Generate a new n solution candidate W out ( T +1) ,i ( i = 1 , 2 , ..., n ) from the updated multiv ariate normal distrib u- tion N ( m ( T + 1) , σ ( T + 1) 2 C ( T + 1)) 8. Repeat 2 to 7 until the con ver gence condition is satisfied or the specified number of repetitions are completed 5 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 Figure 3: Example en vironment state image of CarRacing-v0 and three parameters in the en viroments. The score is added when the car passes through a tile laid on the course. In this process, T represents an update step of the weight matrix W out , and n is the number of solution candidates W out generated at each step. The worker is an agent that implements RCRC, and each work er extracts features, takes the action and plays in each independent en vironment to obtain scores. Therefore, it is possible to parallelize n processes to calculate each score. 4 Experiments 4.1 CarRacing-v0 W e e v aluate the RCRC model in the popular RL task CarRacing-v0 [31] in OpenAI Gym [36]. This is a car racing game en vironment that was kno wn as a difficult continuous actions task [10, 11]. The goal of this game is to go around the course without getting out by operating a car with three continuous parameters: steering wheel [ − 1 , 1] , accelerator [0 , 1] , and brake [0 , 1] . Each frame of the game screen is gi ven by RGB 3 channels and 96 × 96 pixels. The course is filled with tiles as shown in Figure3. Each time the car passes a tile on the course, 1000 / N is added to the score. N is the total number of tiles on the course. The course is randomly generated each time, and the total number of tiles in the course v aries around 300. If all the tiles are passed, the total rew ard will be 1000, b ut it is subtracted by 0.1 for each frame. The episode ends when all the tiles are passed or when 1000 frames are played. If the player can pass all the tiles without getting out of the course, the re ward will be o ver 900. The definition of "solv e" in this game is to get an av erage of 900 per 100 consecuti ve trials. 4.2 Precedur e In the con volutional reserv oir computing layer , we set 3 con volution layers and 1 dense layer . The filter sizes in the con v olution layers are 31, 14, and 6, and the strides are all 2. W e set D con v and D esn to 512 to expand the features. In the reservoir computing layer , we also set the sparsity of W to 0.8; the spectral radius of W to 0.95. All acti vation functions are set to tanh , which is often used in reservoir computing and achie ves higher scores. As in world model, we set three units ( ˜ A 1 ( t ) , ˜ A 2 ( t ) , and ˜ A 3 ( t ) ) as output of the controller layer , and each of them corresponds to an action: steering wheel A 1 ( t ) , accelerator A 2 ( t ) , and brake A 3 ( t ) [10, 11]. Also as in world model, each action A ( t ) is determined by con verting each ˜ A ( t ) by g sho wn as follo ws [10, 11]: g ( ˜ A ( t )) = tanh ˜ A 1 ( t ) [ tanh ˜ A 2 ( t ) + 1 . 0] / 2 . 0 clip [ tanh ˜ A 3 ( t ) , 0 , 1] . The function clip [ x, λ min , λ max ] is a function that limits the value of x in range from λ min to λ max by clipping. 6 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 Figure 4: The best average score o ver 8 randomly created tracks among 16 w orkers at CarRacing-v0 . T able 1: CarRacing-v0 scores of v arious methods. Method A verage Score DQN [37] 343 ± 18 DQN + Dropout [38] 892 ± 41 A3C (Continuous) [39] 591 ± 45 W orld model with random MDN-RNN [32] 870 ± 120 W orld model (V model) [10] 632 ± 251 W orld model [10] 906 ± 21 GA [33] 903 ± 73 RCRC model (V isual model) 864 ± 79 RCRC model 901 ± 20 In the experiment, 16 workers ( n = 16) with different W out parameters are prepared for each update step, and each worker is set to simulate o ver 8 randomly generated tracks ( m = 8) , and update W out with an av erage of these scores. As the input v alue, each frame is resized to 3 channels of 64 × 64 pixels. As in w orld model [10, 11], we ev aluate an av erage score ov er 100 randomly created tracks score as the generalization ability of the models. T o in vestigate the ability of each netw ork structures, we e v aluate three models: full RCRC model, the RCRC model that remov es the reservoir computing layer from con volutional reservoir computing layer (visual model), the RCRC model that has only one dense layer as feature extractor (dense model). The dense model uses flatten vector of 64 × 64 with 3 channels image, and weights of all models are random and fixed. The visual model extracts visual features and the dense model extracts only visual features with no conv olutional process. In both the visual model and the dense model, the inputs to the controller layer are the D con v -dimensional outputs from the dense layer sho wn in Figure2, and one bias term. 4.3 Result The best scores among 16 work ers are shown in Figure4. Each workers score are e valuated as average score ov er 8 randomly generated tracks. Although the world model improved score faster than the full RCRC model, the full RCRC model also reached high score. The full RCRC model reached an a verage score around 900 at 200 generations and stable high score after 400 generations, while the world model reached stable high score after 250 generations. This result sho ws that the full RCRC model is comparable to world model at the same condition, re gardless of no training 7 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 process in feature extractions. Howe ver , the full RCRC model was slower than the w orld model to achiev e stable high scores. Incredibly , the dense model reached an av erage score abo ve 880 o ver 8 randomly generated tracks, and the visual model reached abov e 890. The dense model’ s score transition has higher v olatility than the visual model’ s score transition. Furthermore, the visual model’ s score is less stable than the full RCRC model’ s score. These results shows that only one dense process can extract visual features e ven though the weight are random and fix ed, and the features extracted by con v olutional process and ESN improved scores. W e also test the ability of single dense network in the MNIST datasets [35] which is benchmark dataset of image recognition task, including 28 × 28 gray-scaled handwritten images. The MNIST dataset contains 60000 training data and 10000 testing data. In experiments, we mer ged these data, and randomly sampled 60000 data as training data and 10000 data as testing data with no duplication to e valuate model ability by multiple datasets. As input to the dense layer , we used 784 vector that is flatten representation of 28 × 28 gray-scaled handwritten images, and set the dense layer has 512 units. Each input v ector is divided by 255 to normalize v alue. The weight of the dense layer is randomly generated from a Gaussian distrib ution N (0 , 0 . 06 2 ) and then fixed. After extracting features by the dense layer , we uses these features as input to logistic regression with L2 penalty to classify images into 10 classes. As a result of this experiments, we confirmed the feature extracted by random fix ed-weight single dense layer has ability to achie ve a verage accurac y score 91 . 58 ± 0 . 27(%) ov er 20 trials by linear model. Surprisingly , this result sho ws that only single dense layer with random fixed-weight has ability to e xtract visual features. The generalization ability of the visual model and the full RCRC model that e valuated as av erage score ov er 100 randomly generated tracks are sho wn in T able1. The full RCRC model achie ved abo ve 901 ± 20 that is comparable to state of the art approaches such as the world model approach [10] and GA approach [33]. T o achie ve over 900 score of 100 randomly generated tracks, the models is only allo wed to mistake a fe w dri ving. Therefore the full RCRC model can be regarded as ha ving ability to solve CarRacing-v0 . Although the visual model e xtracts 512-dimensional visual features with random fix ed-weight CNN, it achie ves 864 ± 79 which is better than the V model that uses only 32-dimensional features extracted by V AE as input to controller layer in world model. Furthermore, the time-series features extracted by ESN impro ves dri ving. 5 Discussion and Future w ork In this study , we focused on e xtracting features that sufficiently e xpress the en vironment state, rather than those that are trained to solve the RL task. T o this end, we developed a no vel model called RCRC, which, using random fixed-weight CNN and a novel ESN method, respectiv ely , extracts visual features from en vironment state pixels and time-series features from a series of the state pixels. Therefore, no training process is required, and features can be ef ficiently extracted. In the controller layer , a linear combination of both features and actions is trained using CMA-ES. This model architecture results in highly practical features that omit the training process and reduce computational costs, and there is no need to store lar ge v olumes of data. W e also sho w that RCRC achie ves state of the art scores in a popular continuous RL task, CarRacing-v0 . This result brings us to the conclusion that netw ork structures themselves, such as CNN and ESN, hav e the capacity to extract features. W e also found that the single dense network and simple CNN model with random fixed-weight can e xtract visual features, and these models achie ved high scores. Although V AE has desirable features such as ability to reconstruct the input and high interpretability of latent space by using reparameterization trick which uses Gaussian noise to use backpropagation, we consider that large definiti ve features can also extract expressi ve enough visual features. Because of our limited computing resources, we were unable to assign more workers to CMA-ES. There is a possibility that more efficient and stable training could be performed by assigning more work ers. Although RCRC can take wide range of actions and parallelization by using CMA-ES, it is not suitable for the task that is hard to real simulation because it has to ev aluate parameters by real simulation. As a further impro vement, there is a possibility that the score can be impro ved and made it more stable by using a multi-con volutional reserv oir computing layer to extract multiple features [40]. The current con volutional reserv oir computing layer uses random weight samples generated from Gaussian distrib utions. Therefore, it can easily obtain multiple independent features by using different random seeds. Our results ha ve the potential to mak e RL widely av ailable. Recently , many RL models ha ve achiev ed high accuracy in v arious tasks, but most of them hav e high computational costs and often require significant time for training. This makes the introduction of RL inaccessible for many . Howe ver , by using our RCRC model, anyone can train the model at a high speed with much lo wer computational costs, and importantly , anyone can b uild a highly accurate model. 8 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 In addition, RCRC can handle both continuous- and discrete-valued tasks, and ev en when the en vironment changes, training can be performed without an y prior learning such as the V AE and MDN-RNN in world model. Therefore, it can be used easily by anyone in man y en vironments. In future work, we consider making predictions from pre vious extracted features and actions to the next ones to be an important and promising task. Because the ESN was initially proposed to predict complex time-series, it can be assumed to ha ve capacity to predict future features. If this prediction is achie ved with high accuracy , it can self-simulate RL tasks by making iterativ e predictions from initial state pixels. This will help to broaden the scope of RL applications. 6 Acknowledgements The authors are grateful to T akuya Y aguchi for the discussions on reinforcement learning. W e also thank Hiroyasu Ando for helping us to improv e the manuscript. References [1] David Silv er , Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George V an Den Driessche, Julian Schrittwieser , Ioannis Antonoglou, V eda Panneershelv am, Marc Lanctot, et al. Mastering the game of go with deep neural networks and tree search. nature , 529(7587):484, 2016. [2] David Silv er , Julian Schrittwieser, Karen Simonyan, Ioannis Antonoglou, Aja Huang, Arthur Guez, Thomas Hubert, Lucas Baker , Matthew Lai, Adrian Bolton, et al. Mastering the game of go without human kno wledge. Natur e , 550(7676):354, 2017. [3] V olodymyr Mnih, Koray Kavukcuoglu, David Silv er , Alex Gra ves, Ioannis Antonoglou, Daan Wierstra, and Martin A. Riedmiller . Playing atari with deep reinforcement learning. arXiv pr eprint arXiv:1312.5602 , 2013. [4] Dan Hor gan, John Quan, Da vid Budden, Gabriel Barth-Maron, Matteo Hessel, Hado v an Hasselt, and David Silver . Distrib uted prioritized experience replay . arXiv pr eprint arXiv:1803.00933 , 2018. [5] Ste ven Kapturo wski, Georg Ostrovski, W ill Dabney , John Quan, and Remi Munos. Recurrent experience replay in distributed reinforcement learning. In International Confer ence on Learning Repr esentations , 2019. [6] Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. Deep reinforcement learning: A brief survey . IEEE Signal Pr ocessing Magazine , 34(6):26–38, 2017. [7] Matthew Hausknecht and Peter Stone. Deep recurrent q-learning for partially observ able mdps. In 2015 AAAI F all Symposium Series , 2015. [8] V olodymyr Mnih, Adria Puigdomenech Badia, Mehdi Mirza, Alex Grav es, T imothy Lillicrap, T im Harley , David Silver , and Koray Kavukcuoglu. Asynchronous methods for deep reinforcement learning. In International confer ence on machine learning , pages 1928–1937, 2016. [9] T om Schaul, John Quan, Ioannis Antonoglou, and David Silver . Prioritized experience replay . arXiv pr eprint arXiv:1511.05952 , 2015. [10] David Ha and Jür gen Schmidhuber . W orld models. arXiv preprint , 2018. [11] David Ha and Jürgen Schmidhuber . Recurrent world models facilitate policy e v olution. In S. Bengio, H. W allach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neur al Information Pr ocessing Systems 31 , pages 2450–2462. Curran Associates, Inc., 2018. [12] Diederik P Kingma and Max W elling. Auto-encoding variational bayes. arXiv pr eprint arXiv:1312.6114 , 2013. [13] Danilo Jimenez Rezende, Shakir Mohamed, and Daan Wierstra. Stochastic backpropagation and approximate inference in deep generativ e models. arXiv pr eprint arXiv:1401.4082 , 2014. [14] Alex Gra ves. Generating sequences with recurrent neural networks. arXiv pr eprint arXiv:1308.0850 , 2013. [15] David Ha. Recurrent neural network tutorial for artists. blog .otor o.net , 2017. [16] Nikolaus Hansen and Andreas Ostermeier . Completely derandomized self-adaptation in evolution strate gies. Evolutionary Computation , 9(2):159–195, 2001. [17] Nikolaus Hansen. The CMA evolution strate gy: A tutorial. arXiv pr eprint arXiv:1604.00772 , 2016. [18] David V erstraeten, Benjamin Schrauwen, Michiel d’Haene, and Dirk Stroobandt. An experimental unification of reservoir computing methods. Neural networks , 20(3):391–403, 2007. 9 A P R E P R I N T - J U L Y 1 9 , 2 0 1 9 [19] Mantas Lukoše vi ˇ cius and Herbert Jaeger . Reservoir computing approaches to recurrent neural network training. Computer Science Revie w , 3(3):127–149, 2009. [20] Herbert Jaeger . The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn, Germany: German National Resear ch Center for Information T echnology GMD T echnical Report , 148(34):13, 2001. [21] Herbert Jaeger and Harald Haas. Harnessing nonlinearity: Predicting chaotic systems and saving energy in wireless communication. science , 304(5667):78–80, 2004. [22] Mantas Lukoše vi ˇ cius. A practical guide to applying echo state networks. In Neural networks: T ricks of the tr ade , pages 659–686. Springer , 2012. [23] Pattree ya T anisaro and Gunther Heidemann. T ime series classification using time warping in variant echo state networks. In 2016 15th IEEE International Confer ence on Machine Learning and Applications (ICMLA) , pages 831–836. IEEE, 2016. [24] Qianli Ma, Lifeng Shen, W eibiao Chen, Jiabin W ang, Jia W ei, and Zhiwen Y u. Functional echo state netw ork for time series classification. Information Sciences , 373:1–20, 2016. [25] István Szita, V iktor Gyenes, and András L ˝ orincz. Reinforcement learning with echo state netw orks. In Interna- tional Confer ence on Artificial Neural Networks , pages 830–839. Springer , 2006. [26] Zhiqiang T ong and Gouhei T anaka. Reservoir computing with untrained con volutional neural networks for image recognition. In 2018 24th International Confer ence on P attern Recognition (ICPR) , pages 1289–1294. IEEE, 2018. [27] Masanobu Inubushi and Kazuyuki Y oshimura. Reservoir computing beyond memory-nonlinearity trade-of f. Scientific r eports , 7(1):10199, 2017. [28] Hanten Chang, Shinji Nakaoka, and Hiroyasu Ando. Effect of shapes of acti vation functions on predictability in the echo state network. arXiv preprint , 2019. [29] Alireza Goudarzi, Peter Banda, Matthew R. Lakin, Christof T euscher , and Dark o Stefanovic. A comparative study of reservoir computing for temporal signal processing. arXiv pr eprint arXiv:1401.2224 , 2014. [30] Danijar Hafner , T imothy P . Lillicrap, Ian Fischer , Ruben V illegas, Da vid Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. arXiv preprint , 2018. [31] Oleg Klimo v . Carracing-v0. https://gym.openai.com/envs/CarRacing- v0/ , 2016. [32] Corentin T allec, Léonard Blier , and Diviyan Kalainathan. Reproducing "world models". is training the recurrent network really needed ? https://ctallec.github.io/world- models/ , 2018. [33] Sebastian Risi and Kenneth O. Stanley . Deep neuroe volution of recurrent and discrete world models. arXiv pr eprint arXiv:1906.08857 , 2019. [34] Sepp Hochreiter and Jürgen Schmidhuber . Long short-term memory . Neural computation , 9(8):1735–1780, 1997. [35] Y ann LeCun. The mnist database of handwritten digits. http://yann.lecun.com/exdb/mnist/ , 1998. [36] Greg Brockman, V icki Cheung, Ludwig Pettersson, Jonas Schneider , John Schulman, Jie T ang, and W ojciech Zaremba. Openai gym, 2016. [37] Luc. Prieur . Deep-Q learning for Box2d racecar RL problem. https://goo.gl/VpDqSw , 2017. [38] Patrik Gerber , Jiajing Guan, Elvis Nunez, Kaman Phamdo, T onmoy Monsoor , and Nicholas Malaya. Solving ope- nai’ s car racing environment with deep reinforcement learning and dropout. https://github.com/AMD- RIPS/ RL- 2018/blob/master/documents/nips/nips_2018.pdf , 2018. [39] Se W on Jang, Jesik Min, and Chan Lee. Reinforcement Car Racing with A3C . https://www.scribd.com/ document/358019044/ , 2017. [40] Marc Massar and Serge Massar . Mean-field theory of echo state netw orks. Physical Review E , 87(4):042809, 2013. 10
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment